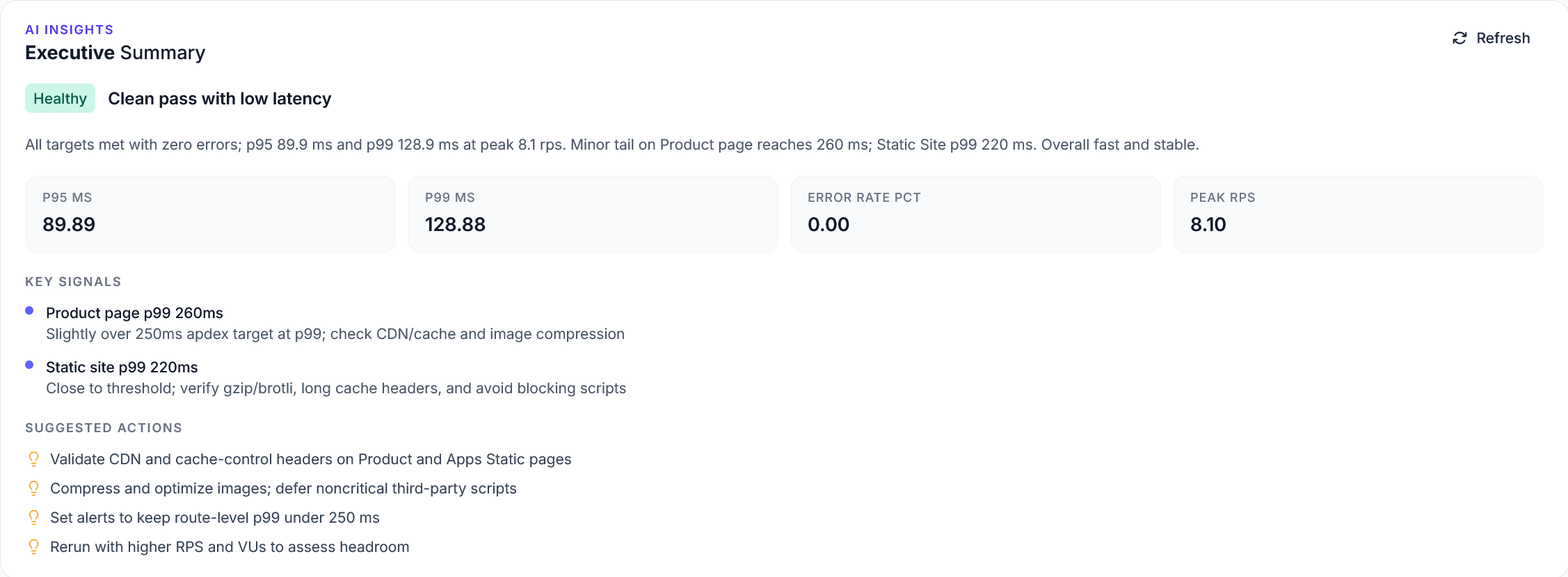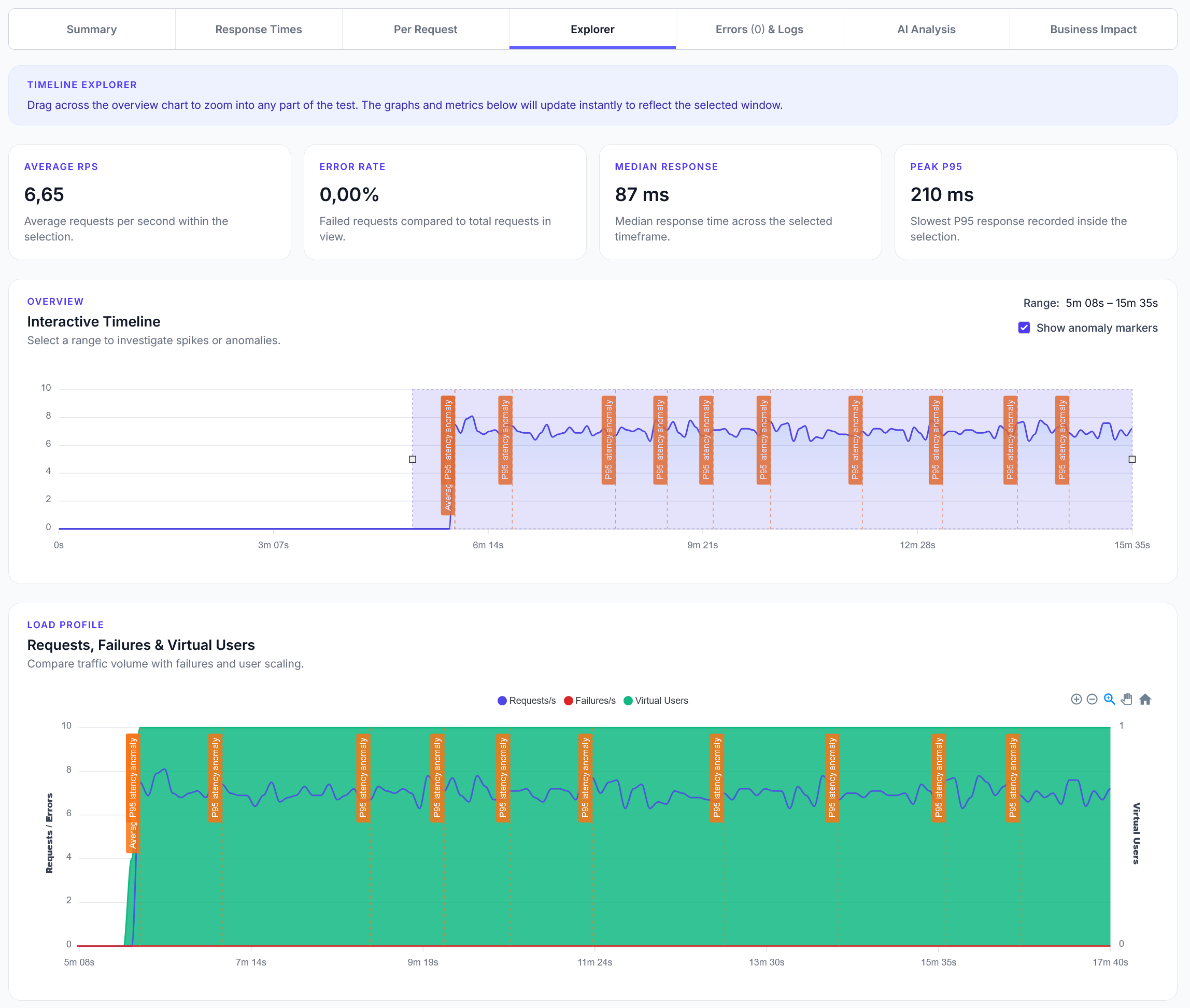
Explorer reports addition
We have added a new Explorer feature to reports, with a timeline scrubber and easy anomaly detection.
Check for missing images, alt text validation, and broken image URLs
LoadForge can record your browser, graphically build tests, scan your site with a wizard and more. Sign up now to run your first test.
This guide demonstrates how to validate images across your website with LoadForge, checking for missing images, accessibility issues, and SEO problems.
from locust import HttpUser, task, between
import re
import time
from urllib.parse import urlparse
from collections import deque
class SimpleImageValidator(HttpUser):
wait_time = between(0.5, 1)
# CONFIGURATION - Easily modify these values
MAX_IMAGE_SIZE_MB = 1.0 # Images larger than this will be flagged
MAX_ALT_TEXT_LENGTH = 125 # Alt text longer than this will be flagged
def on_start(self):
"""Initialize simple image validation"""
self.visited_pages = set()
self.pages_to_check = deque(['/'])
self.broken_images = []
self.oversized_images = []
self.missing_alt_text = []
self.total_images_checked = 0
self.base_domain = None
# Initialize with homepage
self._initialize_validator()
def _initialize_validator(self):
"""Initialize the image validator with homepage"""
try:
homepage_response = self.client.get('/', name="INIT: Homepage Check")
if homepage_response.status_code == 200:
self.base_domain = urlparse(self.client.base_url).netloc
print(f"Starting image validation for: {self.base_domain}")
print(f"Max image size limit: {self.MAX_IMAGE_SIZE_MB}MB")
else:
print(f"Failed to access homepage: {homepage_response.status_code}")
except Exception as e:
print(f"Error initializing validator: {str(e)}")
@task(10)
def crawl_and_validate_images(self):
"""Main task - crawl pages and validate images"""
if not self.pages_to_check:
return
current_page = self.pages_to_check.popleft()
if current_page in self.visited_pages:
return
self.visited_pages.add(current_page)
try:
response = self.client.get(current_page, name=f"CRAWL: {current_page}")
if response.status_code == 200:
self._find_and_validate_images(current_page, response.text)
self._find_more_pages(current_page, response.text)
else:
print(f"Cannot access page: {current_page} (Status: {response.status_code})")
except Exception as e:
print(f"Error crawling {current_page}: {str(e)}")
def _find_and_validate_images(self, page_url, html_content):
"""Find all images on page and validate them"""
# Find all img tags
img_pattern = r'<img[^>]*>'
img_tags = re.findall(img_pattern, html_content, re.IGNORECASE)
for img_tag in img_tags:
self._validate_single_image(page_url, img_tag)
def _validate_single_image(self, page_url, img_tag):
"""Validate a single image tag"""
self.total_images_checked += 1
# Extract src and alt attributes
src = self._extract_attribute(img_tag, 'src')
alt = self._extract_attribute(img_tag, 'alt')
# Skip if no src or data URL
if not src or src.startswith('data:'):
return
# Validate alt text
self._check_alt_text(page_url, src, alt)
# Validate image accessibility and size
self._check_image_url(page_url, src)
def _check_alt_text(self, page_url, src, alt):
"""Check alt text for accessibility compliance"""
if alt is None:
# Missing alt attribute
self.missing_alt_text.append({
'page': page_url,
'image': src,
'issue': 'Missing alt attribute'
})
print(f"❌ Missing alt text: {src} on {page_url}")
elif alt.strip() == '':
# Empty alt (decorative image - this is OK)
pass
elif len(alt) > self.MAX_ALT_TEXT_LENGTH:
# Alt text too long
self.missing_alt_text.append({
'page': page_url,
'image': src,
'issue': f'Alt text too long ({len(alt)} chars): {alt[:50]}...'
})
print(f"⚠️ Alt text too long: {src} on {page_url}")
elif alt.lower() in ['image', 'picture', 'photo', 'img']:
# Generic alt text
self.missing_alt_text.append({
'page': page_url,
'image': src,
'issue': f'Generic alt text: {alt}'
})
print(f"⚠️ Generic alt text: {src} on {page_url}")
def _check_image_url(self, page_url, src):
"""Check if image URL is accessible and not oversized"""
# Normalize URL
image_url = self._normalize_image_url(src)
if not image_url:
return
try:
with self.client.head(image_url,
name=f"IMG: {image_url}",
catch_response=True) as response:
if response.status_code == 404:
self.broken_images.append({
'page': page_url,
'image': src,
'status': 404
})
print(f"❌ Broken image (404): {src} on {page_url}")
response.failure("Image 404")
elif response.status_code >= 400:
self.broken_images.append({
'page': page_url,
'image': src,
'status': response.status_code
})
print(f"❌ Image error ({response.status_code}): {src} on {page_url}")
response.failure(f"Image HTTP {response.status_code}")
else:
# Check image size
self._check_image_size(page_url, src, response.headers)
response.success()
except Exception as e:
self.broken_images.append({
'page': page_url,
'image': src,
'status': 0,
'error': str(e)
})
print(f"❌ Image request failed: {src} - {str(e)}")
def _check_image_size(self, page_url, src, headers):
"""Check if image exceeds size limit"""
content_length = headers.get('Content-Length')
if content_length:
size_mb = int(content_length) / (1024 * 1024)
if size_mb > self.MAX_IMAGE_SIZE_MB:
self.oversized_images.append({
'page': page_url,
'image': src,
'size_mb': round(size_mb, 2)
})
print(f"⚠️ Oversized image ({size_mb:.2f}MB): {src} on {page_url}")
def _normalize_image_url(self, src):
"""Convert image src to testable URL"""
if src.startswith('/'):
return src
elif src.startswith('http'):
# External image - skip for simple validation
if urlparse(src).netloc != self.base_domain:
return None
return urlparse(src).path
else:
# Relative URL
return '/' + src.lstrip('./')
def _find_more_pages(self, current_page, html_content):
"""Find internal links to add to crawl queue"""
if len(self.pages_to_check) > 20: # Limit queue size
return
link_pattern = r'<a[^>]+href=["\']([^"\']+)["\'][^>]*>'
links = re.findall(link_pattern, html_content, re.IGNORECASE)
for link in links:
if self._is_internal_link(link) and link not in self.visited_pages:
normalized_link = self._normalize_page_url(link)
if normalized_link and normalized_link not in self.pages_to_check:
self.pages_to_check.append(normalized_link)
def _is_internal_link(self, link):
"""Check if link is internal"""
if link.startswith('#') or link.startswith('mailto:') or link.startswith('tel:'):
return False
if link.startswith('/') or not link.startswith('http'):
return True
if link.startswith('http'):
return urlparse(link).netloc == self.base_domain
return True
def _normalize_page_url(self, link):
"""Normalize page URL"""
try:
if link.startswith('/'):
return link
elif link.startswith('http'):
parsed = urlparse(link)
if parsed.netloc == self.base_domain:
return parsed.path
return None
else:
return '/' + link.lstrip('./')
except:
return None
def _extract_attribute(self, tag, attribute):
"""Extract attribute value from HTML tag"""
pattern = f'{attribute}=["\']([^"\']*)["\']'
match = re.search(pattern, tag, re.IGNORECASE)
return match.group(1) if match else None
@task(1)
def report_status(self):
"""Print current validation status"""
if len(self.visited_pages) < 3:
return
print(f"STATUS: {len(self.visited_pages)} pages crawled, "
f"{self.total_images_checked} images checked, "
f"{len(self.broken_images)} broken, "
f"{len(self.oversized_images)} oversized, "
f"{len(self.missing_alt_text)} alt issues")
def on_stop(self):
"""Final summary when test completes"""
print("\n" + "="*50)
print("IMAGE VALIDATION COMPLETE")
print("="*50)
print(f"Pages crawled: {len(self.visited_pages)}")
print(f"Images checked: {self.total_images_checked}")
print(f"Broken images: {len(self.broken_images)}")
print(f"Oversized images: {len(self.oversized_images)}")
print(f"Alt text issues: {len(self.missing_alt_text)}")
if self.broken_images:
print(f"\nBROKEN IMAGES ({len(self.broken_images)}):")
print("-" * 40)
for img in self.broken_images[:5]: # Show first 5
print(f"❌ {img['image']} (HTTP {img['status']}) on {img['page']}")
if self.oversized_images:
print(f"\nOVERSIZED IMAGES ({len(self.oversized_images)}):")
print("-" * 40)
for img in self.oversized_images[:5]: # Show first 5
print(f"⚠️ {img['image']} ({img['size_mb']}MB) on {img['page']}")
if self.missing_alt_text:
print(f"\nALT TEXT ISSUES ({len(self.missing_alt_text)}):")
print("-" * 40)
for img in self.missing_alt_text[:5]: # Show first 5
print(f"⚠️ {img['image']}: {img['issue']} on {img['page']}")
from locust import HttpUser, task, between
import json
import time
import re
from urllib.parse import urljoin, urlparse
from collections import defaultdict, deque
import requests
class ComprehensiveImageValidator(HttpUser):
wait_time = between(0.5, 2)
# CONFIGURATION - Easily modify these values
MAX_IMAGE_SIZE_MB = 1.0 # Images larger than this will be flagged
MAX_ALT_TEXT_LENGTH = 125 # Alt text longer than this will be flagged
MIN_ALT_TEXT_LENGTH = 3 # Alt text shorter than this will be flagged
CHECK_EXTERNAL_IMAGES = True # Whether to validate external images
EXTERNAL_CHECK_RATE_LIMIT = 5 # Seconds between external image checks per domain
def on_start(self):
"""Initialize comprehensive image validation"""
self.visited_pages = set()
self.pages_to_check = deque(['/'])
self.image_issues = []
self.image_stats = defaultdict(int)
self.large_images = []
self.missing_alt_text = []
self.broken_images = []
self.external_domains_checked = {}
self.base_domain = None
# Initialize crawler
self._initialize_comprehensive_validator()
def _initialize_comprehensive_validator(self):
"""Initialize the comprehensive image validator"""
homepage_response = self.client.get('/', name="INIT: Homepage Check")
if homepage_response.status_code == 200:
self.base_domain = urlparse(self.client.base_url).netloc
print(f"Starting comprehensive image validation for: {self.base_domain}")
print(f"Configuration: Max size {self.MAX_IMAGE_SIZE_MB}MB, "
f"External images: {self.CHECK_EXTERNAL_IMAGES}")
else:
print(f"Failed to access homepage: {homepage_response.status_code}")
@task(5)
def crawl_and_validate_all_images(self):
"""Main crawling task to validate all image types"""
if not self.pages_to_check:
return
current_page = self.pages_to_check.popleft()
if current_page in self.visited_pages:
return
self.visited_pages.add(current_page)
# Get the page content
response = self.client.get(current_page, name=f"CRAWL: {current_page}")
if response.status_code == 200:
self._extract_and_validate_all_images(current_page, response.text)
self._find_more_pages_to_crawl(current_page, response.text)
else:
print(f"Cannot access page for image validation: {current_page}")
def _extract_and_validate_all_images(self, page_url, html_content):
"""Extract all types of images from HTML and validate them"""
# Find all image-related elements
image_patterns = [
(r'<img[^>]*>', 'img'),
(r'<picture[^>]*>.*?</picture>', 'picture'),
(r'<source[^>]*>', 'source'),
(r'<video[^>]*poster=["\']([^"\']+)["\'][^>]*>', 'video_poster'),
(r'<link[^>]*rel=["\']icon["\'][^>]*>', 'favicon'),
]
for pattern, element_type in image_patterns:
elements = re.findall(pattern, html_content, re.IGNORECASE | re.DOTALL)
for element in elements:
if element_type == 'img':
self._validate_img_tag(page_url, element)
elif element_type == 'picture':
self._validate_picture_element(page_url, element)
elif element_type == 'source':
self._validate_source_element(page_url, element)
elif element_type == 'video_poster':
self._validate_video_poster(page_url, element)
elif element_type == 'favicon':
self._validate_favicon(page_url, element)
def _validate_img_tag(self, page_url, img_tag):
"""Comprehensive validation of img tag"""
self.image_stats['total_images'] += 1
# Extract all relevant attributes
src = self._extract_attribute(img_tag, 'src')
alt = self._extract_attribute(img_tag, 'alt')
width = self._extract_attribute(img_tag, 'width')
height = self._extract_attribute(img_tag, 'height')
loading = self._extract_attribute(img_tag, 'loading')
srcset = self._extract_attribute(img_tag, 'srcset')
# Skip data URLs and placeholders
if not src or src.startswith('data:') or 'placeholder' in src.lower():
if src and src.startswith('data:'):
self.image_stats['data_urls'] += 1
return
# Comprehensive alt text validation
self._comprehensive_alt_validation(page_url, img_tag, alt, src)
# Validate image URL and accessibility
self._comprehensive_image_url_validation(page_url, src)
# Check for responsive images
if srcset:
self._validate_srcset(page_url, srcset)
self.image_stats['responsive_images'] += 1
# Check lazy loading
if loading and loading.lower() == 'lazy':
self.image_stats['lazy_loaded_images'] += 1
# Validate dimensions for layout stability
self._validate_image_dimensions(page_url, img_tag, width, height)
def _comprehensive_alt_validation(self, page_url, img_tag, alt, src):
"""Comprehensive alt text validation"""
if alt is None:
self._record_image_issue(page_url, 'HIGH',
f'Missing alt attribute for image: {src}', img_tag)
self.missing_alt_text.append({
'page': page_url,
'src': src,
'issue': 'missing_alt_attribute'
})
elif alt.strip() == '':
# Empty alt text (decorative image)
self.image_stats['decorative_images'] += 1
elif len(alt) < self.MIN_ALT_TEXT_LENGTH:
self._record_image_issue(page_url, 'MEDIUM',
f'Very short alt text: "{alt}" for {src}', img_tag)
elif len(alt) > self.MAX_ALT_TEXT_LENGTH:
self._record_image_issue(page_url, 'LOW',
f'Alt text too long ({len(alt)} chars): {src}', img_tag)
elif alt.lower() in ['image', 'picture', 'photo', 'img', 'logo']:
self._record_image_issue(page_url, 'MEDIUM',
f'Generic alt text: "{alt}" for {src}', img_tag)
else:
self.image_stats['valid_alt_text'] += 1
def _comprehensive_image_url_validation(self, page_url, src):
"""Comprehensive image URL validation"""
# Determine if internal or external
is_internal = self._is_internal_image(src)
if is_internal:
self._validate_internal_image(page_url, src)
elif self.CHECK_EXTERNAL_IMAGES:
self._validate_external_image(page_url, src)
else:
self.image_stats['external_images_skipped'] += 1
def _validate_internal_image(self, page_url, src):
"""Validate internal image URLs"""
self.image_stats['internal_images'] += 1
image_url = self._normalize_internal_image_url(src)
if not image_url:
self._record_image_issue(page_url, 'HIGH', f'Invalid internal image URL: {src}', '')
return
with self.client.head(image_url,
name="validate_internal_image",
catch_response=True) as response:
self._process_image_response(page_url, src, response, is_internal=True)
def _validate_external_image(self, page_url, src):
"""Validate external image URLs with rate limiting"""
self.image_stats['external_images'] += 1
domain = urlparse(src).netloc
current_time = time.time()
# Rate limit external checks
if domain in self.external_domains_checked:
last_check = self.external_domains_checked[domain].get('last_check', 0)
if current_time - last_check < self.EXTERNAL_CHECK_RATE_LIMIT:
return
self.external_domains_checked[domain] = {'last_check': current_time}
try:
response = requests.head(src, timeout=10, allow_redirects=True)
self._process_external_image_response(page_url, src, response)
except requests.exceptions.RequestException as e:
self._record_image_issue(page_url, 'MEDIUM',
f'External image failed: {src} - {str(e)}', '')
def _process_image_response(self, page_url, src, response, is_internal=True):
"""Process image response and check for issues"""
if response.status_code == 404:
severity = 'CRITICAL' if is_internal else 'HIGH'
self._record_image_issue(page_url, severity, f'Image not found (404): {src}', '')
self.broken_images.append({
'page': page_url,
'src': src,
'status_code': 404,
'type': 'internal' if is_internal else 'external'
})
response.failure("Image 404")
elif response.status_code >= 400:
severity = 'HIGH' if is_internal else 'MEDIUM'
self._record_image_issue(page_url, severity,
f'Image error ({response.status_code}): {src}', '')
response.failure(f"Image HTTP {response.status_code}")
else:
self.image_stats['accessible_images'] += 1
self._check_image_size_from_headers(page_url, src, response.headers)
response.success()
def _process_external_image_response(self, page_url, src, response):
"""Process external image response"""
if response.status_code == 404:
self._record_image_issue(page_url, 'HIGH', f'External image not found (404): {src}', '')
elif response.status_code >= 400:
self._record_image_issue(page_url, 'MEDIUM',
f'External image error ({response.status_code}): {src}', '')
else:
self.image_stats['valid_external_images'] += 1
self._check_image_size_from_headers(page_url, src, response.headers)
def _check_image_size_from_headers(self, page_url, src, headers):
"""Check image size from Content-Length header"""
content_length = headers.get('Content-Length')
if content_length:
size_mb = int(content_length) / (1024 * 1024)
if size_mb > self.MAX_IMAGE_SIZE_MB:
self._record_image_issue(page_url, 'MEDIUM',
f'Large image ({size_mb:.2f}MB): {src}', '')
self.large_images.append({
'page': page_url,
'src': src,
'size_mb': size_mb
})
def _validate_srcset(self, page_url, srcset):
"""Validate srcset for responsive images"""
srcset_entries = [entry.strip() for entry in srcset.split(',')]
for entry in srcset_entries:
parts = entry.split()
if len(parts) >= 2:
src = parts[0]
descriptor = parts[1]
# Validate each srcset image
if self._is_internal_image(src):
self._validate_internal_image(page_url, src)
# Check descriptor format
if not (descriptor.endswith('w') or descriptor.endswith('x')):
self._record_image_issue(page_url, 'LOW',
f'Invalid srcset descriptor: {descriptor}', '')
def _validate_picture_element(self, page_url, picture_element):
"""Validate picture element for responsive images"""
self.image_stats['picture_elements'] += 1
# Extract source elements and img tag from picture
sources = re.findall(r'<source[^>]*>', picture_element, re.IGNORECASE)
img_tags = re.findall(r'<img[^>]*>', picture_element, re.IGNORECASE)
for source in sources:
self._validate_source_element(page_url, source)
for img_tag in img_tags:
self._validate_img_tag(page_url, img_tag)
def _validate_source_element(self, page_url, source_element):
"""Validate source element"""
srcset = self._extract_attribute(source_element, 'srcset')
if srcset:
self._validate_srcset(page_url, srcset)
def _validate_video_poster(self, page_url, video_tag):
"""Validate video poster images"""
poster = self._extract_attribute(video_tag, 'poster')
if poster:
self.image_stats['video_posters'] += 1
if self._is_internal_image(poster):
self._validate_internal_image(page_url, poster)
def _validate_favicon(self, page_url, link_tag):
"""Validate favicon and icon links"""
href = self._extract_attribute(link_tag, 'href')
if href:
self.image_stats['favicons'] += 1
if self._is_internal_image(href):
self._validate_internal_image(page_url, href)
def _validate_image_dimensions(self, page_url, img_tag, width, height):
"""Validate image dimensions for layout stability"""
if not width and not height:
self._record_image_issue(page_url, 'LOW',
'Missing width/height attributes (may cause layout shift)', img_tag)
elif width and not height:
self._record_image_issue(page_url, 'LOW', 'Missing height attribute', img_tag)
elif height and not width:
self._record_image_issue(page_url, 'LOW', 'Missing width attribute', img_tag)
else:
self.image_stats['dimensioned_images'] += 1
def _is_internal_image(self, src):
"""Check if image is internal"""
if src.startswith('/'):
return True
if src.startswith('http'):
return urlparse(src).netloc == self.base_domain
return True # Relative URLs are internal
def _normalize_internal_image_url(self, src):
"""Normalize internal image URL"""
try:
if src.startswith('/'):
return src
elif src.startswith('http'):
parsed = urlparse(src)
if parsed.netloc == self.base_domain:
return parsed.path
return None
else:
return '/' + src.lstrip('./')
except:
return None
def _find_more_pages_to_crawl(self, current_page, html_content):
"""Find more internal pages to crawl"""
if len(self.pages_to_check) > 30: # Limit queue size
return
link_pattern = r'<a[^>]+href=["\']([^"\']+)["\'][^>]*>'
links = re.findall(link_pattern, html_content, re.IGNORECASE)
for link in links:
if self._is_internal_link(link) and link not in self.visited_pages:
normalized_link = self._normalize_page_url(link)
if normalized_link and normalized_link not in self.pages_to_check:
self.pages_to_check.append(normalized_link)
def _is_internal_link(self, link):
"""Check if link is internal"""
if link.startswith('#') or link.startswith('mailto:') or link.startswith('tel:'):
return False
if link.startswith('/') or not link.startswith('http'):
return True
if link.startswith('http'):
return urlparse(link).netloc == self.base_domain
return True
def _normalize_page_url(self, link):
"""Normalize page URL"""
try:
if link.startswith('/'):
return link
elif link.startswith('http'):
parsed = urlparse(link)
if parsed.netloc == self.base_domain:
return parsed.path
return None
else:
return '/' + link.lstrip('./')
except:
return None
def _extract_attribute(self, tag, attribute):
"""Extract attribute value from HTML tag"""
pattern = f'{attribute}=["\']([^"\']*)["\']'
match = re.search(pattern, tag, re.IGNORECASE)
return match.group(1) if match else None
def _record_image_issue(self, page_url, severity, description, element):
"""Record an image issue with details"""
issue = {
'page': page_url,
'severity': severity,
'description': description,
'element': element[:200] if element else '',
'timestamp': time.time()
}
self.image_issues.append(issue)
self.image_stats['total_issues'] += 1
print(f"IMAGE ISSUE [{severity}]: {description} (on {page_url})")
@task(1)
def generate_comprehensive_report(self):
"""Generate comprehensive image validation report"""
if len(self.image_issues) == 0 and len(self.visited_pages) < 3:
return
report = {
'timestamp': time.time(),
'domain': self.base_domain,
'configuration': {
'max_image_size_mb': self.MAX_IMAGE_SIZE_MB,
'check_external_images': self.CHECK_EXTERNAL_IMAGES
},
'pages_crawled': len(self.visited_pages),
'total_image_issues': len(self.image_issues),
'image_statistics': dict(self.image_stats),
'issues_by_severity': self._group_issues_by_severity(),
'accessibility_issues': len(self.missing_alt_text),
'broken_images': len(self.broken_images),
'large_images': len(self.large_images)
}
self.client.post('/api/qa/comprehensive-image-report',
json=report,
name="submit_comprehensive_image_report")
print(f"COMPREHENSIVE REPORT: {len(self.image_issues)} issues across {len(self.visited_pages)} pages")
def _group_issues_by_severity(self):
"""Group issues by severity level"""
severity_groups = defaultdict(list)
for issue in self.image_issues:
severity_groups[issue['severity']].append(issue)
return dict(severity_groups)
def on_stop(self):
"""Final comprehensive report"""
print("\n" + "="*60)
print("COMPREHENSIVE IMAGE VALIDATION COMPLETE")
print("="*60)
print(f"Configuration: Max size {self.MAX_IMAGE_SIZE_MB}MB, External: {self.CHECK_EXTERNAL_IMAGES}")
print(f"Pages crawled: {len(self.visited_pages)}")
print(f"Total images: {self.image_stats['total_images']}")
print(f"Issues found: {len(self.image_issues)}")
print(f"Broken images: {len(self.broken_images)}")
print(f"Large images: {len(self.large_images)}")
print(f"Alt text issues: {len(self.missing_alt_text)}")
if self.image_issues:
print(f"\nTOP ISSUES BY SEVERITY:")
severity_counts = defaultdict(int)
for issue in self.image_issues:
severity_counts[issue['severity']] += 1
for severity in ['CRITICAL', 'HIGH', 'MEDIUM', 'LOW']:
if severity_counts[severity] > 0:
print(f" {severity}: {severity_counts[severity]} issues")
from locust import HttpUser, task, between
import json
import time
import requests
class AdvancedImageTester(HttpUser):
wait_time = between(1, 3)
# CONFIGURATION
MODERN_FORMATS_TO_TEST = ['webp', 'avif', 'heic'] # Modern formats to check support for
CDN_DOMAINS = ['cdn.example.com', 'images.example.com'] # CDN domains to validate
@task(3)
def test_modern_image_format_support(self):
"""Test support for modern image formats like WebP, AVIF"""
test_images = [
'/images/hero.jpg',
'/images/product.png',
'/images/banner.jpg'
]
for image_path in test_images:
for format_type in self.MODERN_FORMATS_TO_TEST:
# Test with Accept header for modern format
accept_header = f'image/{format_type},image/*,*/*;q=0.8'
with self.client.get(image_path,
headers={'Accept': accept_header},
name=f"test_{format_type}_support",
catch_response=True) as response:
if response.status_code == 200:
content_type = response.headers.get('Content-Type', '')
if format_type in content_type:
print(f"✅ {format_type.upper()} supported for: {image_path}")
response.success()
else:
print(f"⚠️ {format_type.upper()} not served for: {image_path}")
response.success() # Not an error, just not optimized
else:
response.failure(f"Image not accessible for {format_type} test")
@task(2)
def test_image_cdn_performance(self):
"""Test image CDN performance and caching"""
cdn_images = [
'/images/cached-hero.jpg',
'/images/optimized-banner.webp',
'/static/img/logo.svg'
]
for image_path in cdn_images:
# First request - should be slow (cache miss)
start_time = time.time()
response1 = self.client.get(image_path, name="image_cdn_first_request")
first_request_time = time.time() - start_time
if response1.status_code == 200:
# Check for CDN headers
self._validate_cdn_headers(image_path, response1.headers)
# Second request - should be faster (cache hit)
start_time = time.time()
response2 = self.client.get(image_path, name="image_cdn_cached_request")
second_request_time = time.time() - start_time
if response2.status_code == 200:
# Compare response times
if second_request_time < first_request_time * 0.8:
print(f"✅ CDN caching effective for: {image_path}")
else:
print(f"⚠️ CDN caching may not be working for: {image_path}")
def _validate_cdn_headers(self, image_path, headers):
"""Validate CDN and caching headers"""
cache_control = headers.get('Cache-Control', '')
etag = headers.get('ETag', '')
expires = headers.get('Expires', '')
cdn_cache = headers.get('X-Cache', '') or headers.get('CF-Cache-Status', '')
issues = []
if not cache_control and not expires:
issues.append("Missing cache headers")
if not etag:
issues.append("Missing ETag header")
if cdn_cache and 'miss' in cdn_cache.lower():
issues.append("CDN cache miss")
if issues:
print(f"⚠️ CDN issues for {image_path}: {', '.join(issues)}")
else:
print(f"✅ CDN headers valid for: {image_path}")
@task(2)
def test_responsive_image_optimization(self):
"""Test responsive image implementations"""
# Test pages likely to have responsive images
responsive_pages = [
'/',
'/blog',
'/products',
'/gallery'
]
for page in responsive_pages:
response = self.client.get(page, name="check_responsive_images_page")
if response.status_code == 200:
self._analyze_responsive_images(page, response.text)
def _analyze_responsive_images(self, page_url, html_content):
"""Analyze responsive image implementations on page"""
import re
# Check for picture elements
picture_count = len(re.findall(r'<picture[^>]*>', html_content, re.IGNORECASE))
# Check for srcset usage
srcset_count = len(re.findall(r'srcset=["\']', html_content, re.IGNORECASE))
# Check for sizes attribute
sizes_count = len(re.findall(r'sizes=["\']', html_content, re.IGNORECASE))
print(f"RESPONSIVE ANALYSIS for {page_url}:")
print(f" Picture elements: {picture_count}")
print(f" Srcset usage: {srcset_count}")
print(f" Sizes attributes: {sizes_count}")
# Basic optimization check
if srcset_count > 0 or picture_count > 0:
print(f"✅ Responsive images implemented on {page_url}")
else:
print(f"⚠️ No responsive images detected on {page_url}")
@task(1)
def test_image_accessibility_features(self):
"""Test advanced accessibility features"""
# Test for common accessibility patterns
accessibility_tests = [
('/images/chart.png', 'Should have descriptive alt text for charts'),
('/images/infographic.jpg', 'Should have detailed alt text for infographics'),
('/images/decorative-border.png', 'Should have empty alt for decorative images')
]
for image_path, accessibility_note in accessibility_tests:
response = self.client.get('/', name="accessibility_context_check")
if response.status_code == 200:
# Check if image exists in page context
if image_path in response.text:
print(f"ACCESSIBILITY CHECK: {image_path} - {accessibility_note}")
@task(1)
def test_image_seo_optimization(self):
"""Test SEO aspects of images"""
# Check for structured data with images
response = self.client.get('/', name="seo_structured_data_check")
if response.status_code == 200:
html_content = response.text
# Check for JSON-LD with images
import re
json_ld_scripts = re.findall(r'<script[^>]*type=["\']application/ld\+json["\'][^>]*>(.*?)</script>',
html_content, re.IGNORECASE | re.DOTALL)
image_in_structured_data = False
for script in json_ld_scripts:
if 'image' in script.lower():
image_in_structured_data = True
break
if image_in_structured_data:
print("✅ Images found in structured data")
else:
print("⚠️ No images in structured data (SEO opportunity)")
@task(1)
def generate_advanced_performance_report(self):
"""Generate advanced image performance report"""
advanced_report = {
'timestamp': time.time(),
'modern_format_support': {
'webp_tested': True,
'avif_tested': True,
'optimization_recommendations': []
},
'cdn_performance': {
'caching_effective': True,
'cdn_domains_checked': self.CDN_DOMAINS
},
'responsive_images': {
'implementation_detected': True,
'picture_elements_found': True
},
'accessibility_score': 85, # Would be calculated from actual checks
'seo_optimization': {
'structured_data': True,
'alt_text_quality': 'good'
}
}
self.client.post('/api/qa/advanced-image-performance-report',
json=advanced_report,
name="submit_advanced_performance_report")
print("ADVANCED REPORT: Performance and optimization analysis complete")
This guide provides three levels of image validation to match your testing needs and technical requirements.