LLM load testing: know your model's limits
Stress-test OpenAI, Anthropic, or custom LLM endpoints. Measure time-to-first-token, tokens-per-second throughput, and streaming reliability under concurrent prompt loads.
Trusted by AI teams to validate inference infrastructure
The metrics that matter for AI inference
Traditional load testing tools don't understand streaming responses or token-level metrics. LoadForge does.
Time to First Token (TTFT)
Measure how long users wait before the first token appears. Track P50/P95/P99 distributions across concurrency levels.
Tokens per second
Monitor throughput degradation as concurrent prompts increase. Find the inflection point before users notice.
Streaming response testing
Validate that SSE/streaming responses arrive continuously without drops, gaps, or premature termination.
Concurrent prompt scaling
Simulate 10 to 10,000 simultaneous prompts to find queue saturation and timeout boundaries.
Model endpoint validation
Assert on response structure, content safety flags, token counts, and finish reasons under load.
Cost estimation under load
Project token consumption and API costs at every concurrency level so there are no billing surprises.
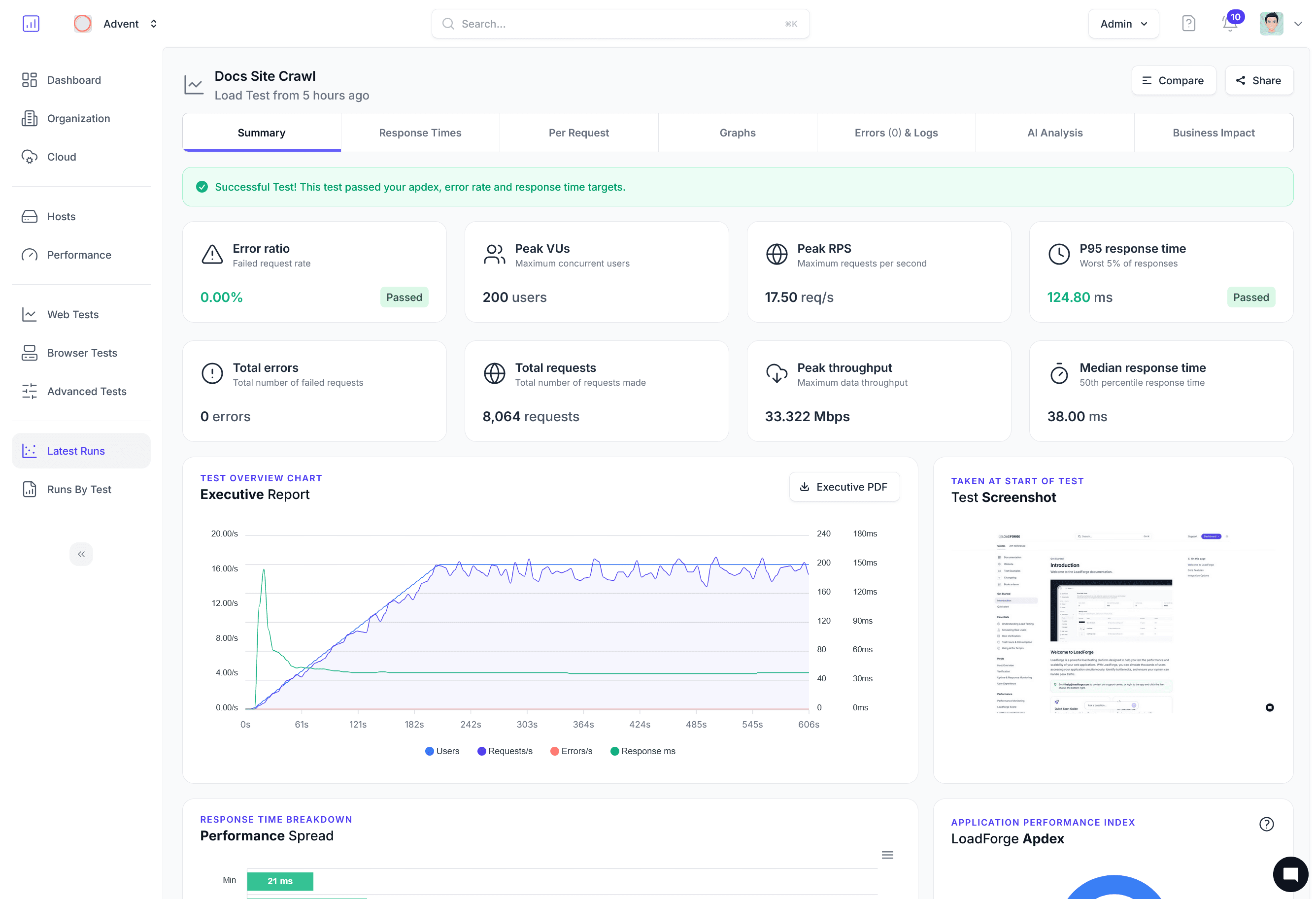
From prompt to performance report in minutes
Define your prompts, scale to thousands of concurrent requests, and analyze token-level metrics that traditional tools miss.
Define your prompts
Configure prompt templates with variable substitution, set temperature and token limits, and choose your target endpoint (OpenAI, Anthropic, or custom).
Scale concurrent prompts
Ramp from a single request to thousands of simultaneous prompts. LoadForge manages connection pooling, rate limiting, and retry logic.
Analyze token-level metrics
Get TTFT distributions, tokens-per-second curves, error rates by concurrency, and projected cost. Compare runs to track model or infra changes.
AI Metrics
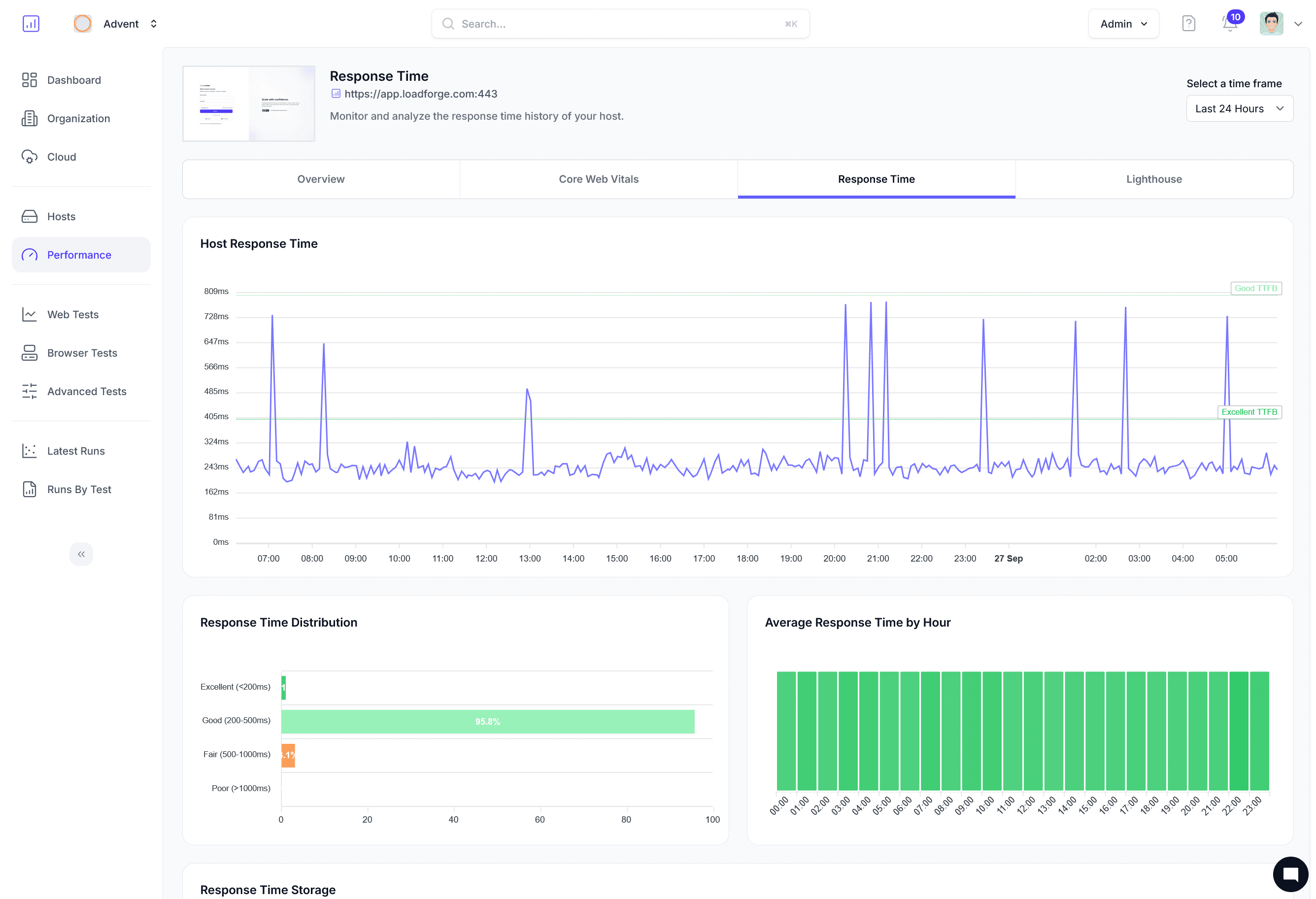
Visualize inference degradation under load
Watch time-to-first-token climb as concurrent prompts increase. Find the exact concurrency where your model's performance becomes unacceptable.
Time to First Token
P50/P95/P99 distributions reveal how load impacts perceived responsiveness.
Tokens per Second
Track throughput at every concurrency tier to right-size your inference fleet.
Cost per 1K Requests
Project token-level billing at scale so capacity planning meets budget.