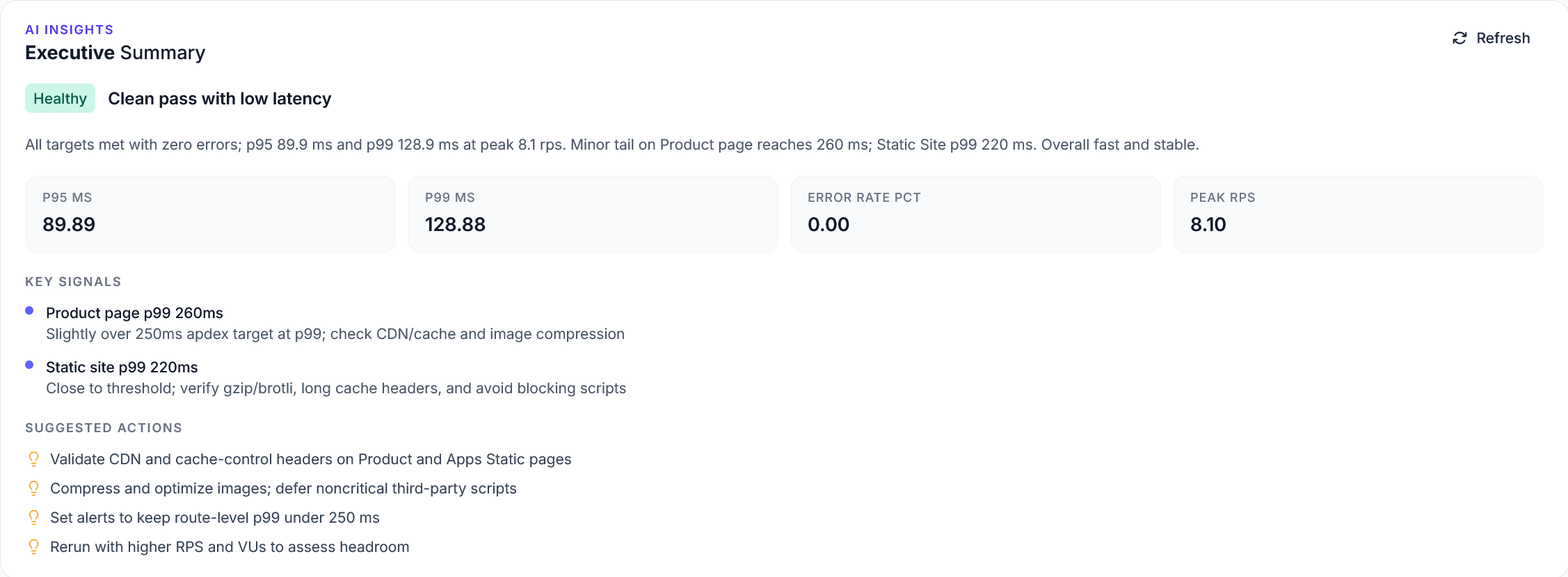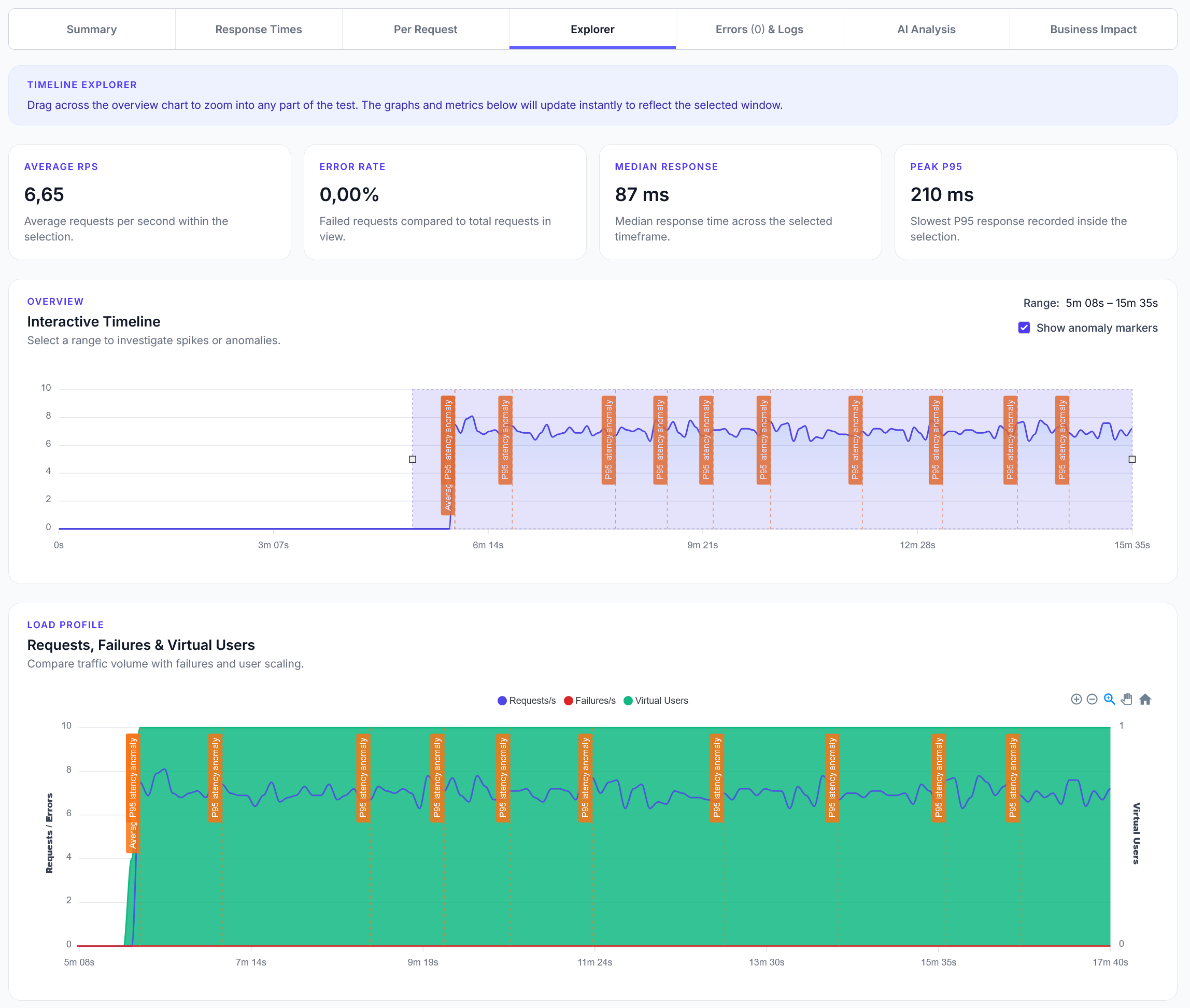
Explorer reports addition
We have added a new Explorer feature to reports, with a timeline scrubber and easy anomaly detection.
Crawl website and detect broken internal/external links with detailed reporting
LoadForge can record your browser, graphically build tests, scan your site with a wizard and more. Sign up now to run your first test.
This guide demonstrates how to create a comprehensive broken links checker with LoadForge, crawling through all pages and detecting various types of link issues.
from locust import HttpUser, task, between
import json
import time
import re
from urllib.parse import urljoin, urlparse
from collections import deque
import logging
class InternalLinksChecker(HttpUser):
wait_time = between(0.5, 1)
def on_start(self):
"""Initialize internal links checking"""
self.visited_pages = set()
self.pages_to_check = deque()
self.broken_links = []
self.total_links_checked = 0
self.base_domain = None
# Setup logging
logging.basicConfig(level=logging.INFO)
self.logger = logging.getLogger(__name__)
# Start with homepage
self._initialize_crawler()
def _initialize_crawler(self):
"""Initialize the crawler with the homepage"""
try:
homepage_response = self.client.get('/', name="INIT: Homepage Check")
if homepage_response.status_code == 200:
self.base_domain = urlparse(self.client.base_url).netloc
self.pages_to_check.append('/')
self.logger.info(f"Starting internal links check for domain: {self.base_domain}")
else:
self.logger.error(f"Failed to access homepage: {homepage_response.status_code}")
except Exception as e:
self.logger.error(f"Error initializing crawler: {str(e)}")
@task(10)
def crawl_internal_pages(self):
"""Main crawling task - only checks internal links"""
if not self.pages_to_check:
return
current_page = self.pages_to_check.popleft()
if current_page in self.visited_pages:
return
self.visited_pages.add(current_page)
try:
response = self.client.get(current_page, name=f"CRAWL: {current_page}")
if response.status_code == 200:
self._extract_and_validate_internal_links(current_page, response.text)
else:
self._log_broken_link(current_page, current_page, response.status_code,
f"Page not accessible: {response.status_code}")
except Exception as e:
self._log_broken_link(current_page, current_page, 0, f"Exception accessing page: {str(e)}")
def _extract_and_validate_internal_links(self, source_page, html_content):
"""Extract and validate only internal page links (URLs only, no resources)"""
# Only look for <a href="..."> tags (actual page links)
link_pattern = r'<a[^>]+href=["\']([^"\']+)["\'][^>]*>'
# Find all <a> tag links
all_links = re.findall(link_pattern, html_content, re.IGNORECASE)
# Filter to only internal page links and validate them
for link in all_links:
if self._is_internal_link(link) and not self._should_skip_link(link):
# Only validate if it's a page link (not a resource)
if self._is_page_link(link):
self._validate_internal_link(source_page, link)
# Add to crawl queue
normalized_link = self._normalize_url(link)
if normalized_link and normalized_link not in self.visited_pages:
if normalized_link not in self.pages_to_check:
self.pages_to_check.append(normalized_link)
def _is_internal_link(self, link):
"""Check if a link is internal (same domain or relative)"""
# Skip anchors, external protocols
if link.startswith('#') or link.startswith('mailto:') or link.startswith('tel:'):
return False
# Relative paths are internal
if link.startswith('/') or not link.startswith('http'):
return True
# Check if absolute URL is same domain
if link.startswith('http'):
return urlparse(link).netloc == self.base_domain
return True
def _is_page_link(self, link):
"""Check if link is a page (not a resource like image/css/js)"""
# Skip common resource file extensions
resource_extensions = {'.css', '.js', '.jpg', '.jpeg', '.png', '.gif',
'.svg', '.ico', '.pdf', '.zip', '.mp4', '.mp3',
'.woff', '.woff2', '.ttf', '.eot', '.webp', '.avif'}
parsed_link = urlparse(link.lower())
path = parsed_link.path
# Check if it ends with a resource extension
for ext in resource_extensions:
if path.endswith(ext):
return False
# Always consider these as pages (common blog/article patterns)
page_patterns = [
r'/blog/',
r'/articles?/',
r'/posts?/',
r'/news/',
r'/(20\d{2})/', # Year pattern (2020, 2021, etc.)
r'/category/',
r'/tag/',
]
for pattern in page_patterns:
if re.search(pattern, path):
return True
return True
def _should_skip_link(self, link):
"""Determine if a link should be skipped entirely"""
skip_patterns = [
r'^mailto:',
r'^tel:',
r'^javascript:',
r'^data:',
r'^#$', # Empty anchor
r'^\s*$', # Empty or whitespace
]
for pattern in skip_patterns:
if re.match(pattern, link, re.IGNORECASE):
return True
return False
def _validate_internal_link(self, source_page, link):
"""Validate an internal link and log any issues"""
self.total_links_checked += 1
normalized_url = self._normalize_url(link)
if not normalized_url:
self._log_broken_link(source_page, link, 0, "Invalid URL format")
return
try:
with self.client.get(normalized_url,
name=f"LINK: {normalized_url}",
catch_response=True) as response:
if response.status_code == 404:
self._log_broken_link(source_page, link, 404, "Page not found")
response.failure("❌ 404 Not Found")
elif response.status_code >= 500:
self._log_broken_link(source_page, link, response.status_code, "Server error")
response.failure(f"❌ Server Error {response.status_code}")
elif response.status_code >= 400:
self._log_broken_link(source_page, link, response.status_code, "Client error")
response.failure(f"❌ Client Error {response.status_code}")
else:
response.success()
except Exception as e:
self._log_broken_link(source_page, link, 0, f"Request failed: {str(e)}")
def _log_broken_link(self, source_page, broken_link, status_code, reason):
"""Log broken link with detailed information"""
broken_link_info = {
'source_page': source_page,
'broken_link': broken_link,
'status_code': status_code,
'reason': reason,
'timestamp': time.time()
}
self.broken_links.append(broken_link_info)
# Log to console and LoadForge
error_msg = f"BROKEN LINK: {broken_link} (Status: {status_code}) found on page: {source_page} - {reason}"
self.logger.error(error_msg)
print(error_msg)
def _normalize_url(self, link):
"""Normalize URL for consistent checking"""
try:
# Handle relative paths
if link.startswith('/'):
return link
elif link.startswith('http'):
parsed = urlparse(link)
if parsed.netloc == self.base_domain:
return parsed.path + ('?' + parsed.query if parsed.query else '')
return None # External link, skip
else:
# Relative link - normalize to absolute path
return '/' + link.lstrip('./')
except Exception:
return None
@task(1)
def report_status(self):
"""Print status to console (no API submission needed)"""
if len(self.visited_pages) < 3: # Wait until we have some data
return
print(f"STATUS: {len(self.visited_pages)} pages crawled, "
f"{self.total_links_checked} links checked, "
f"{len(self.broken_links)} broken links found")
def on_stop(self):
"""Final summary when test completes"""
print("\n" + "="*50)
print("INTERNAL LINKS CHECK COMPLETE")
print("="*50)
print(f"Pages crawled: {len(self.visited_pages)}")
print(f"Total links checked: {self.total_links_checked}")
print(f"Broken links found: {len(self.broken_links)}")
if self.broken_links:
print(f"\nBROKEN LINKS FOUND ({len(self.broken_links)}):")
print("-" * 40)
for link_info in self.broken_links:
print(f"❌ {link_info['broken_link']} (HTTP {link_info['status_code']})")
print(f" Found on: {link_info['source_page']}")
print(f" Reason: {link_info['reason']}")
print()
else:
print("✅ No broken links found!")
from locust import HttpUser, task, between
import json
import time
import random
import re
from urllib.parse import urljoin, urlparse, urlunparse
from collections import defaultdict, deque
import requests
class BrokenLinksChecker(HttpUser):
wait_time = between(0.5, 2)
def on_start(self):
"""Initialize broken links checking"""
self.visited_pages = set()
self.pages_to_check = deque()
self.broken_links = []
self.redirect_chains = []
self.external_links = {}
self.anchor_links = {}
self.link_stats = defaultdict(int)
self.base_domain = None
# Start with homepage
self._initialize_crawler()
def _initialize_crawler(self):
"""Initialize the crawler with the homepage"""
homepage_response = self.client.get('/',
name="homepage_initial_check")
if homepage_response.status_code == 200:
self.base_domain = urlparse(self.client.base_url).netloc
self.pages_to_check.append('/')
print(f"Starting broken links check for domain: {self.base_domain}")
else:
print(f"Failed to access homepage: {homepage_response.status_code}")
@task(5)
def crawl_and_check_links(self):
"""Main crawling task to check links on pages"""
if not self.pages_to_check:
return
current_page = self.pages_to_check.popleft()
if current_page in self.visited_pages:
return
self.visited_pages.add(current_page)
# Get the page content
response = self.client.get(current_page,
name="crawl_page_for_links")
if response.status_code == 200:
self._extract_and_validate_links(current_page, response.text)
else:
self._record_broken_link(current_page, response.status_code, "Page not accessible")
def _extract_and_validate_links(self, page_url, html_content):
"""Extract all links from HTML and validate them"""
# Find all links in the HTML
link_patterns = [
r'<a[^>]+href=["\']([^"\']+)["\'][^>]*>', # <a href="...">
r'<link[^>]+href=["\']([^"\']+)["\'][^>]*>', # <link href="...">
r'<img[^>]+src=["\']([^"\']+)["\'][^>]*>', # <img src="...">
r'<script[^>]+src=["\']([^"\']+)["\'][^>]*>', # <script src="...">
r'<iframe[^>]+src=["\']([^"\']+)["\'][^>]*>', # <iframe src="...">
]
all_links = []
for pattern in link_patterns:
links = re.findall(pattern, html_content, re.IGNORECASE)
all_links.extend(links)
# Process each link
for link in all_links:
self._validate_single_link(page_url, link)
# Add internal pages to crawl queue
internal_links = [link for link in all_links if self._is_internal_link(link)]
for link in internal_links:
normalized_link = self._normalize_url(link)
if normalized_link and normalized_link not in self.visited_pages:
self.pages_to_check.append(normalized_link)
def _validate_single_link(self, source_page, link):
"""Validate a single link and categorize issues"""
self.link_stats['total_links'] += 1
# Skip certain types of links
if self._should_skip_link(link):
self.link_stats['skipped_links'] += 1
return
# Handle different link types
if link.startswith('#'):
self._validate_anchor_link(source_page, link)
elif self._is_internal_link(link):
self._validate_internal_link(source_page, link)
else:
self._validate_external_link(source_page, link)
def _should_skip_link(self, link):
"""Determine if a link should be skipped"""
skip_patterns = [
r'^mailto:',
r'^tel:',
r'^javascript:',
r'^data:',
r'^#$', # Empty anchor
r'^\s*$', # Empty or whitespace
]
for pattern in skip_patterns:
if re.match(pattern, link, re.IGNORECASE):
return True
return False
def _validate_internal_link(self, source_page, link):
"""Validate internal links"""
self.link_stats['internal_links'] += 1
normalized_url = self._normalize_url(link)
if not normalized_url:
self._record_broken_link(source_page, 0, f"Invalid URL format: {link}")
return
# Check if it's a fragment link
if '#' in normalized_url:
base_url, fragment = normalized_url.split('#', 1)
self._validate_anchor_link(source_page, f"#{fragment}", base_url)
normalized_url = base_url
# Test the internal link
with self.client.get(normalized_url,
name="validate_internal_link",
catch_response=True) as response:
if response.status_code == 404:
self._record_broken_link(source_page, 404, f"Internal link not found: {link}")
response.failure("404 Not Found")
elif response.status_code >= 400:
self._record_broken_link(source_page, response.status_code, f"Internal link error: {link}")
response.failure(f"HTTP {response.status_code}")
elif 300 <= response.status_code < 400:
self._track_redirect_chain(source_page, link, response)
response.success()
else:
self.link_stats['valid_internal_links'] += 1
response.success()
def _validate_external_link(self, source_page, link):
"""Validate external links (with rate limiting)"""
self.link_stats['external_links'] += 1
# Rate limit external link checking
domain = urlparse(link).netloc
current_time = time.time()
if domain in self.external_links:
last_check = self.external_links[domain].get('last_check', 0)
if current_time - last_check < 5: # 5 second rate limit per domain
return
self.external_links[domain] = {'last_check': current_time}
try:
# Use requests for external links to avoid LoadForge rate limits
response = requests.head(link, timeout=10, allow_redirects=True)
if response.status_code == 404:
self._record_broken_link(source_page, 404, f"External link not found: {link}")
elif response.status_code >= 400:
self._record_broken_link(source_page, response.status_code, f"External link error: {link}")
else:
self.link_stats['valid_external_links'] += 1
except requests.exceptions.RequestException as e:
self._record_broken_link(source_page, 0, f"External link failed: {link} - {str(e)}")
def _validate_anchor_link(self, source_page, anchor, target_page=None):
"""Validate anchor/fragment links"""
self.link_stats['anchor_links'] += 1
if target_page is None:
target_page = source_page
# Get the target page content to check for anchor
response = self.client.get(target_page,
name="validate_anchor_target")
if response.status_code == 200:
anchor_id = anchor[1:] # Remove the #
# Check for anchor in HTML
anchor_patterns = [
f'id=["\']?{re.escape(anchor_id)}["\']?',
f'name=["\']?{re.escape(anchor_id)}["\']?',
f'<a[^>]+name=["\']?{re.escape(anchor_id)}["\']?[^>]*>',
]
found_anchor = False
for pattern in anchor_patterns:
if re.search(pattern, response.text, re.IGNORECASE):
found_anchor = True
break
if not found_anchor:
self._record_broken_link(source_page, 0, f"Anchor not found: {anchor} on page {target_page}")
else:
self.link_stats['valid_anchor_links'] += 1
else:
self._record_broken_link(source_page, response.status_code, f"Cannot check anchor {anchor} - target page error")
def _track_redirect_chain(self, source_page, original_link, response):
"""Track and analyze redirect chains"""
redirect_info = {
'source_page': source_page,
'original_link': original_link,
'status_code': response.status_code,
'final_url': response.url,
'redirect_count': len(response.history)
}
if redirect_info['redirect_count'] > 3:
self._record_broken_link(source_page, response.status_code,
f"Too many redirects ({redirect_info['redirect_count']}): {original_link}")
self.redirect_chains.append(redirect_info)
self.link_stats['redirected_links'] += 1
def _record_broken_link(self, source_page, status_code, description):
"""Record a broken link with details"""
broken_link = {
'source_page': source_page,
'status_code': status_code,
'description': description,
'timestamp': time.time(),
'severity': self._get_severity(status_code)
}
self.broken_links.append(broken_link)
self.link_stats['broken_links'] += 1
print(f"BROKEN LINK: {description} (found on {source_page})")
def _get_severity(self, status_code):
"""Determine severity of broken link"""
if status_code == 404:
return 'HIGH'
elif status_code >= 500:
return 'CRITICAL'
elif status_code >= 400:
return 'MEDIUM'
else:
return 'LOW'
def _is_internal_link(self, link):
"""Check if a link is internal to the current domain"""
if link.startswith('/'):
return True
if link.startswith('http'):
return urlparse(link).netloc == self.base_domain
return True # Relative links are internal
def _normalize_url(self, link):
"""Normalize URL for consistent checking"""
try:
if link.startswith('/'):
return link
elif link.startswith('http'):
parsed = urlparse(link)
if parsed.netloc == self.base_domain:
return parsed.path + ('?' + parsed.query if parsed.query else '') + ('#' + parsed.fragment if parsed.fragment else '')
return link
else:
# Relative link
return '/' + link.lstrip('./')
except:
return None
@task(1)
def generate_broken_links_report(self):
"""Generate comprehensive broken links report"""
if len(self.broken_links) == 0 and len(self.visited_pages) < 5:
return # Not enough data yet
report = {
'timestamp': time.time(),
'domain': self.base_domain,
'pages_crawled': len(self.visited_pages),
'total_broken_links': len(self.broken_links),
'link_statistics': dict(self.link_stats),
'broken_links_by_severity': self._group_by_severity(),
'top_broken_pages': self._get_top_broken_pages(),
'redirect_analysis': self._analyze_redirects()
}
# Send report to monitoring endpoint
self.client.post('/api/qa/broken-links-report',
json=report,
name="submit_broken_links_report")
print(f"REPORT: Found {len(self.broken_links)} broken links across {len(self.visited_pages)} pages")
def _group_by_severity(self):
"""Group broken links by severity"""
severity_groups = defaultdict(list)
for link in self.broken_links:
severity_groups[link['severity']].append(link)
return dict(severity_groups)
def _get_top_broken_pages(self):
"""Get pages with most broken links"""
page_counts = defaultdict(int)
for link in self.broken_links:
page_counts[link['source_page']] += 1
return sorted(page_counts.items(), key=lambda x: x[1], reverse=True)[:10]
def _analyze_redirects(self):
"""Analyze redirect patterns"""
return {
'total_redirects': len(self.redirect_chains),
'excessive_redirects': len([r for r in self.redirect_chains if r['redirect_count'] > 3]),
'redirect_domains': list(set([urlparse(r['final_url']).netloc for r in self.redirect_chains]))
}
def on_stop(self):
"""Final report on test completion"""
print("\n=== BROKEN LINKS CHECK COMPLETE ===")
print(f"Pages crawled: {len(self.visited_pages)}")
print(f"Total links checked: {self.link_stats['total_links']}")
print(f"Broken links found: {len(self.broken_links)}")
print(f"Redirect chains: {len(self.redirect_chains)}")
if self.broken_links:
print("\nBROKEN LINKS SUMMARY:")
for link in self.broken_links[:10]: # Show first 10
print(f" - {link['description']} [{link['severity']}]")
from locust import HttpUser, task, between
import json
import time
class AdvancedLinkValidator(HttpUser):
wait_time = between(1, 3)
@task(2)
def check_sitemap_links(self):
"""Validate all links in sitemap.xml"""
response = self.client.get('/sitemap.xml',
name="get_sitemap")
if response.status_code == 200:
# Parse sitemap and validate each URL
import xml.etree.ElementTree as ET
try:
root = ET.fromstring(response.text)
urls = [elem.text for elem in root.iter() if elem.tag.endswith('loc')]
for url in urls[:20]: # Limit for testing
self._validate_sitemap_url(url)
except ET.ParseError:
print("Invalid sitemap XML format")
def _validate_sitemap_url(self, url):
"""Validate individual sitemap URL"""
response = self.client.get(url,
name="validate_sitemap_url")
if response.status_code != 200:
print(f"Sitemap URL broken: {url} - Status: {response.status_code}")
@task(1)
def check_robots_txt_links(self):
"""Check links mentioned in robots.txt"""
response = self.client.get('/robots.txt',
name="get_robots_txt")
if response.status_code == 200:
# Extract sitemap URLs from robots.txt
lines = response.text.split('\n')
sitemap_urls = [line.split(': ')[1].strip() for line in lines
if line.lower().startswith('sitemap:')]
for sitemap_url in sitemap_urls:
self.client.get(sitemap_url,
name="validate_robots_sitemap")
This guide provides comprehensive broken link detection with detailed error reporting and analysis for maintaining website quality.