Introduction
FastAPI is a modern, fast (high-performance), web framework for building APIs with Python 3.7+ based on standard Python type hints. It is designed to be easy to use and to enable rapid development of robust APIs. FastAPI achieves its performance through the use of asynchronous Python, which allows it to handle a large number of requests concurrently without blocking.
One of the main selling points of FastAPI is its speed. FastAPI is one of the fastest Python frameworks available, on par with NodeJS and Go. It is built on top of Starlette for the web parts and Pydantic for the data parts. This powerful combination not only results in high performance but also ensures data validation and serialization are quick and robust.
Why Load Testing is Crucial
While FastAPI's inherent speed is impressive, real-world applications can be complex and may still experience performance bottlenecks when subjected to heavy loads. Load testing is a critical aspect of the development lifecycle for several reasons:
- Performance Bottlenecks: Identifying parts of the application that degrade under load, such as slow queries, inefficient algorithms, or insufficient resources.
- Scalability: Ensuring that the application can scale to handle a large number of concurrent users without service degradation.
- Reliability: Verifying that the application remains stable and responsive under high-stress conditions.
- User Experience: Ensuring that high traffic does not negatively impact the response times and overall user experience of the application.
In the context of FastAPI, load testing helps you understand how your API functions under a range of loads and can reveal critical insights that are necessary for fine-tuning your application's performance.
Load Testing with LoadForge
LoadForge is a cloud-based load testing service designed to simplify the process of load testing web applications and APIs. By leveraging LoadForge, you can run extensive load tests on your FastAPI applications with ease. LoadForge utilizes locustfiles, which are Python scripts that define the behavior of the load test, to simulate user interactions with your application.
In the subsequent sections, we will guide you through setting up a basic FastAPI application, writing a locustfile, configuring and running a load test on LoadForge, and analyzing the results to optimize your application’s performance. With LoadForge's capabilities and FastAPI's speed, you can ensure your application is well-prepared to handle the demands of real-world usage.
By the end of this guide, you will have a solid understanding of the importance of load testing and the knowledge to implement robust load tests for your FastAPI applications using LoadForge.
Setting Up Your FastAPI Application
In this section, we will guide you through setting up a basic FastAPI application. This foundation will be the subject of our load testing using LoadForge. FastAPI is a modern, fast (high-performance) web framework for building APIs with Python 3.6+ based on standard Python type hints.
Prerequisites
Before we begin, ensure that you have the following:
- Python 3.6 or later installed on your system.
- Basic knowledge of Python programming.
Step 1: Installing FastAPI and Uvicorn
First, you'll need to install FastAPI and an ASGI server to serve your application—in this case, we will use Uvicorn.
Open your terminal and run the following command:
pip install fastapi uvicorn
Step 2: Creating a Basic FastAPI Application
Now that we have FastAPI and Uvicorn installed, let’s create a simple FastAPI application. Create a new Python file named main.py and open it in your preferred text editor or IDE. Add the following code:
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
async def read_root():
return {"message": "Hello, World!"}
@app.get("/items/{item_id}")
async def read_item(item_id: int, q: str = None):
return {"item_id": item_id, "q": q}
Let's break down the code:
- Line 1: We import the
FastAPI class from the fastapi module.
- Line 3: We create an instance of the FastAPI class, which will be our application.
- Lines 5-7: We define a root endpoint (
/) that returns a simple JSON response.
- Lines 9-11: We define an endpoint (
/items/{item_id}) where you can pass an item ID and an optional query parameter q.
Step 3: Running the FastAPI Application
To run your FastAPI application, use the following command in your terminal:
uvicorn main:app --reload
This command starts the Uvicorn server and serves your FastAPI application. The --reload flag makes the server restart after code changes, which is useful during development.
Verifying the Application
Once the server is running, open your web browser and navigate to http://127.0.0.1:8000. You should see a JSON response:
{"message": "Hello, World!"}
Additionally, you can visit http://127.0.0.1:8000/items/1?q=example to test the items endpoint, which will respond with:
{"item_id": 1, "q": "example"}
Your FastAPI application is now up and running locally. Next, we will move on to building the locustfile for load testing this application using LoadForge.
Building Your Locustfile
Once you've set up your FastAPI application, the next step is to create a locustfile that will be used to conduct your load tests on LoadForge. This section will guide you through the detailed steps of building a locustfile to simulate traffic on your FastAPI application.
1. Understanding the Components of a Locustfile
A locustfile is essentially a Python script where you define the tasks that Locust will execute during the load test. The key components of a locustfile are:
- Imports: Import necessary modules.
- HttpUser class: This class represents a user that will perform HTTP requests.
- Task Set: A collection of tasks that a user will perform.
- Tasks: Individual tasks representing the different endpoints you want to test.
- Weighting: Optional weights to prioritize certain tasks over others.
- Setup and Teardown: Initialization and cleanup procedures for your test.
2. Sample Locustfile
Here is a sample locustfile tailored for a basic FastAPI application:
from locust import HttpUser, task, between
class FastAPIUser(HttpUser):
# Simulate a user waiting between 1 to 5 seconds between tasks
wait_time = between(1, 5)
@task
def get_root(self):
self.client.get("/")
@task
def get_items(self):
self.client.get("/items")
@task
def post_item(self):
# Assuming your FastAPI app has an endpoint that accepts POST requests
self.client.post("/items", json={"name": "example_item", "price": 100})
3. Explanation of the Code
-
Imports:
from locust import HttpUser, task, between
Import the necessary classes from Locust for defining the user behavior and task execution frequency.
-
HttpUser class:
class FastAPIUser(HttpUser):
This class defines the behavior of a simulated user.
-
wait_time:
wait_time = between(1, 5)
Specifies that the simulated user will wait between 1 to 5 seconds between executing different tasks.
-
Tasks:
Three tasks are defined, each corresponding to different endpoints of the FastAPI application:
@task
def get_root(self):
self.client.get("/")
@task
def get_items(self):
self.client.get("/items")
@task
def post_item(self):
self.client.post("/items", json={"name": "example_item", "price": 100})
- get_root: Simulates a GET request to the root endpoint (
/).
- get_items: Simulates a GET request to the
/items endpoint.
- post_item: Simulates a POST request to the
/items endpoint with some JSON data.
4. Adding Weighting (Optional)
If you want to prioritize certain tasks, you can add weights to your tasks:
from locust import HttpUser, task, between
class FastAPIUser(HttpUser):
wait_time = between(1, 5)
@task(3)
def get_root(self):
self.client.get("/")
@task(2)
def get_items(self):
self.client.get("/items")
@task(1)
def post_item(self):
self.client.post("/items", json={"name": "example_item", "price": 100})
In the above example, the get_root task will be executed three times as often as the post_item task, and the get_items task will be executed twice as often.
5. Preparing the Locustfile for LoadForge
Once your locustfile.py is ready, ensure it's uploaded or accessible from your LoadForge account. You might place it in a version control system or directly upload it through the LoadForge interface.
Now you're ready to configure and run your load tests on LoadForge, which we'll cover in the next section.
By following these steps, you create a robust locustfile that allows you to effectively load test your FastAPI application, ensuring it can handle high levels of concurrent traffic.
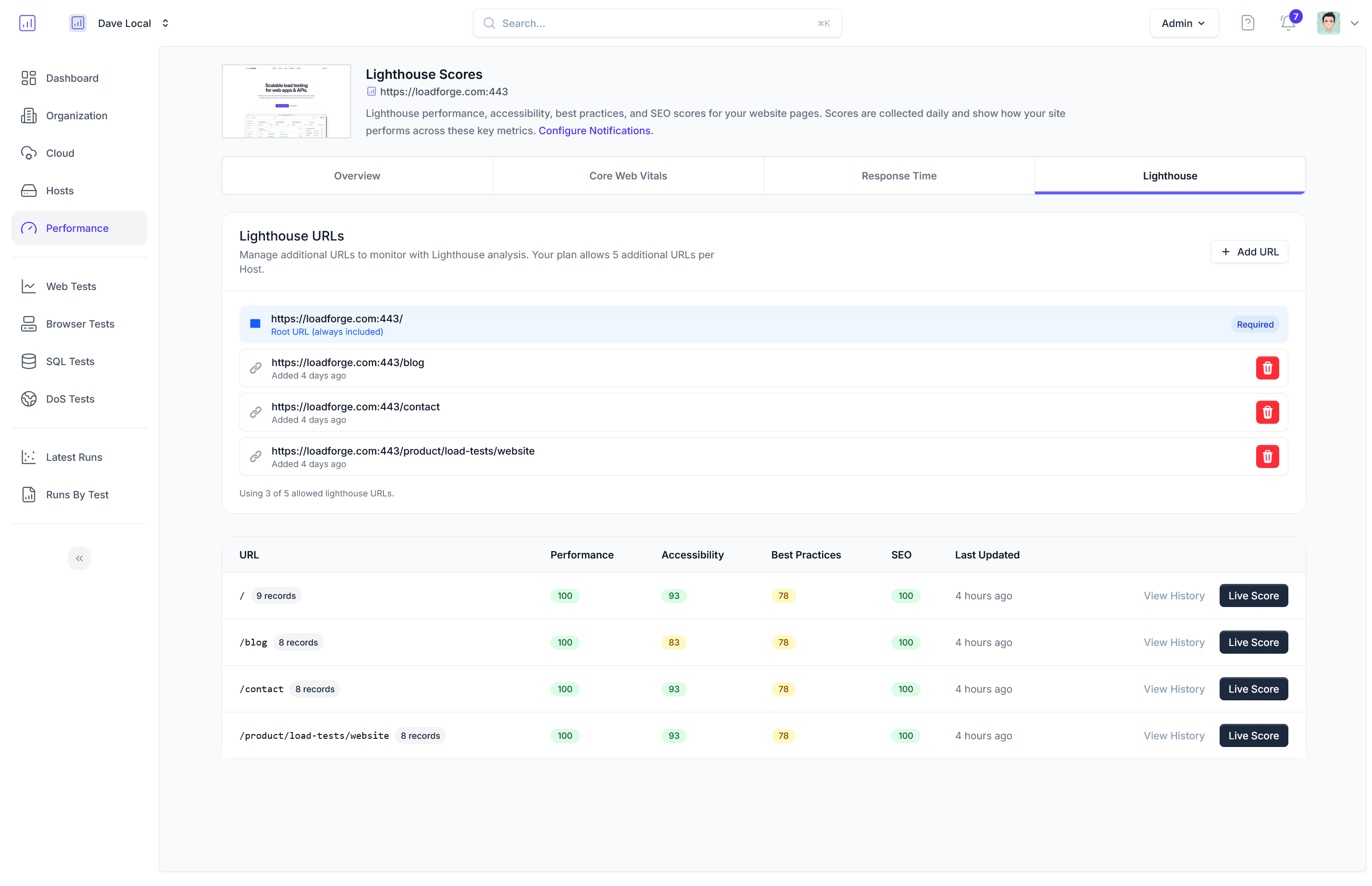
Configuring Your Load Test on LoadForge
Now that you've prepared your FastAPI application and your locustfile, it's time to configure your load test in LoadForge. This section will guide you through the essential settings to configure, including the number of users, spawn rate, and test duration, to ensure your load testing is comprehensive and effective.
Step-by-Step Configuration
-
Log into LoadForge Dashboard
Begin by logging into your LoadForge account. If you don’t have an account yet, you can sign up for a free trial.
-
Create a New Test
Navigate to the “Tests” section in the LoadForge dashboard and click on the “Create Test” button. You will be prompted to input basic details for your load test:
- Name: Provide a name for your load test (e.g., "FastAPI Basic Load Test").
- Description: Optionally, you can add a description for more context.
-
Upload Your Locustfile
Next, upload the locustfile you created in the previous section. This file dictates the behavior of the users in the load test.
- Click on “Upload Locustfile”
- Select the locustfile from your local directory
-
Define Load Test Settings
Now, configure the specifics of your load test:
-
Number of Users: Specify the total number of virtual users (VU) that will simulate real users accessing your FastAPI application.
-
Spawn Rate: This setting controls how quickly new users are added to the test. The spawn rate is defined as the number of users to add per second until the total user count is reached.
- Example: 10 Users per second
-
Test Duration: Define how long the load test should run. This can be specified in seconds, minutes, or hours.
Here’s a simple table to help visualize these settings:
| Setting |
Description |
Example |
| Number of Users |
Total virtual users |
1000 Users |
| Spawn Rate |
Users added per second |
10 Users/sec |
| Test Duration |
Total duration of the load test |
15 minutes |
-
Advanced Settings (Optional)
LoadForge also offers advanced settings for more granular control:
- Ramp-up Pattern: Define a custom ramp-up pattern instead of a fixed spawn rate.
- Location Selection: Choose geographic regions from which to simulate traffic, which is useful for testing global applications.
- Headers and Authorization: Set HTTP headers or authentication tokens required by your FastAPI endpoints.
-
Save Your Configuration
Once you’ve set up your test configurations, click on “Save” to store your settings. You’re now ready to run your load test.
Pro Tip: Always start with a smaller number of users and gradually increase the load. This will help you identify breaking points before stressing your infrastructure.
### Summary
Configuring your load test correctly in LoadForge is crucial for simulating realistic traffic patterns and obtaining useful insights into your FastAPI application's performance. With the correct setup, such as choosing the appropriate number of users, a sensible spawn rate, and a suitable test duration, you can ensure that your load testing yields meaningful results that help optimize the stability and scalability of your application. In the next section, you will learn how to execute your load test and monitor its progress in real-time.
## Running Your Load Test
Now that you've configured your load test settings within LoadForge, it's time to initiate the test and monitor its progress. This section will guide you through the steps to start your load test, observe its execution, and understand the real-time metrics that LoadForge provides.
### Initiating the Load Test
1. **Log in to LoadForge**: Start by logging into your LoadForge account.
2. **Navigate to Your Project**: Go to the project that contains your configured load test.
3. **Select the Test**: Click on the load test you configured, typically found under the "Tests" section.
4. **Start the Test**: You should see a "Start Test" button. Click this to initiate your load test.
### Monitoring Progress
Once your test is running, you will be directed to the LoadForge dashboard that provides real-time metrics and visualizations of your load test. Here’s how you can effectively monitor the progress:
1. **Users Graph**: This graph displays the number of concurrent users accessing your FastAPI application over time. This helps you see the load distribution throughout the test duration.
2. **Requests per Second (RPS)**: This metric shows the rate at which requests are being sent to your FastAPI application. A steady RPS can indicate that your application is managing the load well.
3. **Response Time**:
- **Median**: The middle value of response times.
- **90th Percentile**: The response time below which 90% of the requests fall.
- **95th Percentile**: The response time below which 95% of the requests fall.
- **99th Percentile**: The response time below which 99% of the requests fall.
These metrics help you understand how quickly your application is responding under various loads.
4. **Failure Rate**: This metric indicates the percentage of requests that result in failures (e.g., 4xx or 5xx HTTP responses). A rising failure rate suggests your FastAPI application might be overwhelmed or encountering errors.
### Real-time Metrics Dashboard
LoadForge’s real-time dashboard is a powerful tool for tracking your load test and identifying performance issues on-the-fly. Here are some of the key components:
- **Summary Stats**: Displays critical metrics such as total requests, average response time, and error rates.
- **Charts and Graphs**: Visual representations of data that help you quickly assess how your application is performing under load.
- **Logs**: Real-time logs showing detailed request and error information, invaluable for debugging issues during the test.
### Understanding the Metrics
Here's a brief overview of interpreting the metrics:
- **High Response Times**: If the response times increase significantly, it indicates your FastAPI application is struggling to handle the load. Look at the response time percentiles to identify whether a few requests are slow or if there is a general slowdown.
- **Increased Failure Rates**: A higher failure rate signals that your application or infrastructure might have reached its limits. Inspect the logs to determine the root cause.
- **Constant RPS with Increasing Load**: Ideally, your RPS should increase with the number of users. If it stays constant, it might indicate a bottleneck.
### Example Locustfile Metrics Code
Below is an example of how you can add custom metrics within your `locustfile.py` to better track performance metrics:
<pre><code>import time
from locust import HttpUser, task, between
class QuickstartUser(HttpUser):
wait_time = between(1, 5)
@task
def index_page(self):
start_time = time.time()
with self.client.get("/", catch_response=True) as response:
response_time = time.time() - start_time
if response.status_code == 200:
response.success()
self.environment.events.request_success.fire(
request_type="GET",
name="index_page",
response_time=response_time,
response_length=len(response.content),
)
else:
response.failure("Failed to load page")
</code></pre>
### Initiation to Completion Process
- After you start the test, keep the dashboard open to continuously monitor the metrics.
- LoadForge provides a detailed breakdown of metrics as the test progresses, allowing real-time adjustments if necessary.
- After the load test completes, you will have a comprehensive overview of how your FastAPI application performed.
Monitoring your load test effectively provides you with the insights required to ensure your FastAPI application remains robust under increasing loads. With LoadForge’s detailed metrics and visualizations, you can quickly identify weaker areas and optimize for better performance.
## Analyzing the Results
Once your load test completes, the next critical step is understanding the results. Effective analysis of load test results is crucial to identify performance issues in your FastAPI application and make informed decisions on how to optimize it. In this section, we’ll explore the key performance metrics to monitor, how to identify bottlenecks, and actionable insights to improve your FastAPI application's performance.
### Key Performance Metrics
When analyzing the results from your LoadForge load test, focus on the following key performance metrics:
1. **Response Time (Latency):**
- **Average Response Time:** This is the average time taken for your API to respond to requests. Ensure this time is within acceptable limits for a seamless user experience.
- **Percentiles (50th, 90th, 95th, 99th):** These values indicate the response time distribution. For instance, the 95th percentile represents the time below which 95% of the requests were completed.
2. **Requests per Second (RPS):**
- This metric indicates the number of requests your application is handling per second. A higher RPS can indicate better performance under load, but it must be balanced with acceptable response times.
3. **Failure Rate:**
- Monitor the percentage of failed requests. A high failure rate could signify issues in your application code or infrastructure limitations.
4. **Throughput:**
- This metric measures the rate at which data is successfully delivered over a communication channel, affected by request size and response time.
5. **CPU and Memory Utilization:**
- Check the resource usage of your application during the test. High CPU or memory usage can indicate inefficiencies in your application.
### Identifying Bottlenecks
To identify where your FastAPI application might be struggling, consider the following techniques:
1. **Error Analysis:**
- Review the types of errors returned during the load test (e.g., 5xx server errors or 4xx client errors). These can provide clues about issues in your application or its dependencies.
- Example Log:
<pre><code>
2023-09-30 12:00:00 [ERROR] Request to /api/v1/resource failed with status code 500
</code></pre>
2. **Resource Bottlenecks:**
- If the CPU or memory usage is high, it's worth investigating specific parts of your application such as computationally heavy endpoints or memory leaks.
3. **Database Performance:**
- Long response times can often be traced back to slow database queries. Use tools like `pg_stat_statements` in PostgreSQL or the built-in query performance insights provided by your database to identify and optimize slow queries.
<pre><code>
SELECT * FROM pg_stat_statements ORDER BY total_time DESC LIMIT 5;
</code></pre>
4. **Concurrency Issues:**
- Monitor how well your application handles multiple concurrent requests. Bottlenecks here might reveal themselves through increased latency and failure rates under high load.
### Visualizing and Interpreting LoadForge Dashboards
LoadForge provides a real-time dashboard to monitor the progress and results of your load test. Key elements to focus on include:
- **Response Time Graphs:** Track how response times shift over the duration of the load test.
- **RPS Graphs:** Observe how the requests per second handled by your application changes as the load increases.
- **Failure/Error Rate Visualization:** Understand at what load thresholds your application starts to fail.
### Drilling Down with Profiling Tools
For a deeper dive, you can use profiling tools specific to FastAPI and Python:
- **Pydantic Validation:** Slow data validation can be a performance bottleneck. Profiling Pydantic model validation times may help identify issues.
- **Line Profiler:** Use this to measure the time spent on each line of your code.
<pre><code>
from line_profiler import LineProfiler
def slow_function():
# Your code here
profiler = LineProfiler()
profiler.add_function(slow_function)
profiler.enable_by_count()
slow_function()
profiler.print_stats()
</code></pre>
### Conclusion
By focusing on these key performance metrics, identifying bottlenecks, and using the tools available within LoadForge and your development environment, you can gain invaluable insights into your FastAPI application’s performance. This analysis will guide you in making targeted optimizations, ensuring that your application remains robust and responsive even under significant load. In the next section, we will discuss optimization strategies based on your findings to improve your FastAPI application's performance.
## Optimizing Your FastAPI Application
Optimization should be a continuous process, especially when you identify bottlenecks through load testing. After running your FastAPI application through LoadForge, you might come across various performance issues. Here, we'll provide actionable recommendations to improve your application’s performance focusing on the following areas: database queries, API endpoints, and server configurations.
### Optimizing Database Queries
One of the most common performance bottlenecks in any application is inefficient database queries. Here are some tips on optimizing them:
1. **Use Indexes Appropriately:**
Indexes speed up read operations. Ensure that your most frequent query filters are indexed.
```sql
CREATE INDEX idx_user_email ON users (email);
-
Avoid N+1 Queries:
N+1 query problems occur when you run a query in a loop. Use eager loading to fetch related data in a single query.
# Using SQLAlchemy with FastAPI
users = db.query(User).options(joinedload(User.posts)).all()
-
Optimize Joins and Subqueries:
Sometimes the way you join tables can significantly affect performance. Test different approaches.
-- Example of an optimized SQL join
SELECT u.id, u.name, p.title
FROM users u
JOIN posts p ON u.id = p.user_id;
-
Query Caching:
Cache frequent read queries using an in-memory store like Redis.
import redis
r = redis.StrictRedis(host='localhost', port=6379, db=0)
@app.get("/users/{user_id}")
async def get_user(user_id: int):
cached_user = r.get(f"user:{user_id}")
if cached_user:
return cached_user
user = await db.query(User).get(user_id)
r.set(f"user:{user_id}", user)
return user
Optimizing API Endpoints
Efficient handling of API endpoints can significantly enhance the responsiveness of your FastAPI application.
-
Use Background Tasks for Time-Consuming Operations:
Background tasks allow returning a response immediately while performing longer operations asynchronously.
from fastapi import BackgroundTasks
def send_email(email: str):
# Simulating a long-running task
time.sleep(10)
print(f"Email sent to {email}")
@app.post("/send-email/")
async def api_send_email(email: str, background_tasks: BackgroundTasks):
background_tasks.add_task(send_email, email)
return {"message": "Email scheduled to be sent"}
-
Asynchronous Endpoints:
Utilize FastAPI's ability to handle async operations to improve performance.
@app.get("/items/")
async def read_items():
items = await fetch_items_from_db()
return items
-
Pagination:
For endpoints returning large datasets, implement pagination to split the data into manageable chunks.
@app.get("/users/")
async def get_users(page: int = 1, limit: int = 10):
offset = (page - 1) * limit
users = await db.query(User).offset(offset).limit(limit).all()
return users
Optimizing Server Configurations
Reviewing your server configurations can also yield significant performance improvements.
-
Uvicorn Workers:
Increasing the number of Uvicorn workers can help handle more requests concurrently.
uvicorn app:app --workers 4
-
Gunicorn Integration:
Use Gunicorn with Uvicorn workers for improved performance.
gunicorn app:app -w 4 -k uvicorn.workers.UvicornWorker
-
Load Balancing:
Use a load balancer to distribute traffic across multiple instances of your application.
# Example using Nginx as a load balancer
upstream fastapi {
server app1:8000;
server app2:8000;
}
server {
location / {
proxy_pass http://fastapi;
}
}
By applying these optimizations based on the insights from your LoadForge load tests, you can significantly enhance the performance and reliability of your FastAPI application. Always monitor the improvements with subsequent load tests to ensure the changes have the desired effect and continue to iterate on your optimizations.
Conclusion
In this guide, we've walked through the essential steps to get started with load testing your FastAPI application using LoadForge. Here's a quick recap of what we covered:
-
Introduction: We discussed the importance of load testing and introduced FastAPI, a modern web framework, to highlight why performance testing is crucial for ensuring that your application can handle high traffic and stress.
-
Setting Up Your FastAPI Application: We provided detailed instructions on creating a basic FastAPI application, including a simple example to demonstrate what we will be load testing.
-
Building Your Locustfile: We walked you through the process of writing a Locustfile, the test script required by LoadForge to simulate user behavior and apply load to your FastAPI application. This included an example Python code to get you started.
-
Configuring Your Load Test on LoadForge: We guided you on how to configure your load test settings within LoadForge, covering key parameters such as the number of users, spawn rate, and test duration to tailor the load test to your specific needs.
-
Running Your Load Test: We provided step-by-step instructions on how to initiate the load test within LoadForge, monitor its progress, and understand the real-time metrics displayed on the LoadForge dashboard.
-
Analyzing the Results: We offered tips on how to analyze your load test results, focusing on common performance metrics and how to identify potential bottlenecks in your FastAPI application.
-
Optimizing Your FastAPI Application: Finally, we shared recommendations on how to optimize your FastAPI application based on the load test results. This included strategies for improving database queries, API endpoints, and server configurations to enhance performance.
Benefits of Using LoadForge
LoadForge offers several advantages for load testing your FastAPI applications:
- Scalability: LoadForge can simulate thousands of users from multiple locations around the globe, allowing you to understand how your application performs under various conditions.
- Ease of Use: With its intuitive interface and powerful configuration options, LoadForge makes it simple to set up and run load tests without requiring extensive technical expertise.
- Detailed Analytics: Real-time metrics and comprehensive test results help you quickly identify performance bottlenecks and areas for improvement.
- Continuous Integration: LoadForge supports CI/CD pipelines, enabling you to integrate load testing into your development workflow and ensure consistent application performance.
Encouragement for Regular and Iterative Load Testing
As you continue to develop and enhance your FastAPI applications, regular and iterative load testing should become an integral part of your workflow. By incorporating load tests into your development cycle, you can:
- Proactively Identify Issues: Catch performance issues early in the development process before they impact your users.
- Ensure Reliability: Verify that your application can handle increased traffic and stress during peak times or unexpected surges.
- Improve User Experience: Consistently optimize your application to provide fast and reliable service to your users.
In summary, LoadForge provides a robust platform to ensure your FastAPI applications perform optimally under load. By following the steps in this guide and integrating load testing into your development practices, you can deliver high-performing and resilient applications that meet the demands of your users.
Happy testing! 🚀