Introduction to Strapi and Database Performance
Strapi is an open-source headless CMS designed to facilitate the creation, management, and distribution of content across various platforms. As a decoupled CMS, Strapi allows developers to manage content via a user-friendly admin panel and deliver it through APIs to any frontend framework or third-party application, giving them the freedom to choose their tech stack and scale their projects more effectively.
Strapi's Core Architecture
Here's a simplified look at Strapi's core architecture to help you understand the context in which database performance matters:
- Admin Panel: A React-based interface that admins and content managers use to create, edit, and manage content.
- API Layer: Strapi automatically generates RESTful or GraphQL endpoints for each content type, which can be consumed by frontend applications.
- Middleware: Processes requests and responses, handling tasks such as authentication, authorization, and custom logic.
- Database: Utilizes SQL or NoSQL databases to store and manage content data. Strapi supports various databases, including PostgreSQL, MongoDB, MySQL, and SQLite.
User -> API Layer -> Middleware -> Database
Why Database Performance Matters
Database performance is crucial in any content management system, and Strapi is no exception. Here are a few reasons why optimizing database performance is vital:
- User Experience: Faster query responses lead to quicker content delivery, enhancing the overall user experience.
- Scalability: Efficient database operations ensure that your Strapi application can handle more concurrent users and larger datasets without degrading performance.
- Resource Utilization: Optimized databases make better use of server resources, reducing the cost associated with infrastructure and maintenance.
- Data Integrity: Ensuring high performance increases the reliability of data transactions, reducing the likelihood of data corruption and loss.
Key Performance Metrics
When discussing database performance in Strapi, several key metrics are often considered:
- Query Response Time: The time it takes for the database to respond to a query.
- Throughput: The number of transactions that the database can process in a given timeframe.
- Resource Usage: CPU, memory, and I/O utilization by the database system.
- Concurrency: The ability to handle multiple database transactions simultaneously.
Setting the Context
In this guide, we will explore various techniques to optimize database performance for your Strapi application. From choosing the right database and optimizing schemas to implementing effective caching strategies and performing load testing with LoadForge, you will discover proven methods to enhance the performance and reliability of your Strapi-based projects.
This foundational understanding of Strapi's architecture and the importance of database performance sets the stage for the detailed tips and techniques that follow. Stay tuned as we delve deeper into each optimization strategy to help you build a fast and efficient Strapi application.
Choosing the Right Database
Selecting the appropriate database for your Strapi project is a crucial decision that can significantly influence your application's overall performance and scalability. Strapi, being a headless CMS, offers support for various databases like PostgreSQL, MongoDB, and MySQL. Each database has its own strengths and limitations, and the right choice depends on your specific requirements, including read/write performance, scalability, and data consistency needs. This section will guide you through the different database options available for Strapi and their impacts on performance.
PostgreSQL
PostgreSQL is a powerful, open-source object-relational database system known for its robustness, advanced features, and performance. It is a popular choice for Strapi for several reasons:
- Advanced Features: PostgreSQL offers advanced features like Full-Text Search, JSONB support, and complex queries, which can be beneficial for complex Strapi applications.
- ACID Compliance: PostgreSQL ensures data integrity and consistency, making it ideal for applications that require strong transactional support.
- Performance: With proper indexing and optimization, PostgreSQL can handle large amounts of data efficiently. It is also well-suited for complex read-heavy operations.
Example PostgreSQL Configuration for Strapi
Here is a basic configuration to get you started with PostgreSQL in Strapi:
module.exports = ({ env }) => ({
defaultConnection: 'default',
connections: {
default: {
connector: 'bookshelf',
settings: {
client: 'postgres',
host: env('DATABASE_HOST', '127.0.0.1'),
port: env.int('DATABASE_PORT', 5432),
database: env('DATABASE_NAME', 'strapi'),
username: env('DATABASE_USERNAME', 'strapi'),
password: env('DATABASE_PASSWORD', 'strapiPassword'),
ssl: env.bool('DATABASE_SSL', false),
},
options: {},
},
},
});
MongoDB
MongoDB is a NoSQL database known for its flexibility and scalability. It employs a document-oriented data model, which can be advantageous for certain types of Strapi applications:
- Schema-less Design: MongoDB's schema-less nature makes it highly flexible, suitable for rapidly changing applications and prototypes.
- Horizontal Scalability: MongoDB supports sharding, allowing seamless horizontal scaling to handle large amounts of read and write operations.
- Performance: Ideal for write-heavy applications due to its high throughput and ability to handle unstructured data.
Example MongoDB Configuration for Strapi
Here is a sample configuration to connect Strapi with MongoDB:
module.exports = ({ env }) => ({
defaultConnection: 'default',
connections: {
default: {
connector: 'mongoose',
settings: {
host: env('DATABASE_HOST', '127.0.0.1'),
srv: env.bool('DATABASE_SRV', false),
port: env.int('DATABASE_PORT', 27017),
database: env('DATABASE_NAME', 'strapi'),
username: env('DATABASE_USERNAME', 'strapi'),
password: env('DATABASE_PASSWORD', 'strapiPassword'),
},
options: {
authenticationDatabase: env('AUTHENTICATION_DATABASE', null),
ssl: env.bool('DATABASE_SSL', false),
},
},
},
});
MySQL
MySQL is another widely-used relational database management system known for its reliability and speed. It is a good choice for Strapi projects for several reasons:
- Mature Ecosystem: MySQL has a mature ecosystem with excellent community support and a wide range of tools and libraries.
- High Performance: MySQL is optimized for high-read performance and is well-suited for applications with a high volume of concurrent read operations.
- Ease of Use: MySQL is known for its simplicity and ease of setup, making it a popular choice for developers.
Example MySQL Configuration for Strapi
Below is an example configuration to help you connect Strapi with MySQL:
module.exports = ({ env }) => ({
defaultConnection: 'default',
connections: {
default: {
connector: 'bookshelf',
settings: {
client: 'mysql',
host: env('DATABASE_HOST', '127.0.0.1'),
port: env.int('DATABASE_PORT', 3306),
database: env('DATABASE_NAME', 'strapi'),
username: env('DATABASE_USERNAME', 'strapi'),
password: env('DATABASE_PASSWORD', 'strapiPassword'),
ssl: env.bool('DATABASE_SSL', false),
},
options: {},
},
},
});
Factors to Consider
When choosing the right database for your Strapi project, consider the following factors:
- Data Model: Determine if your data is relational or document-based to choose between SQL (PostgreSQL, MySQL) and NoSQL (MongoDB) databases.
- Scalability Requirements: Assess the scalability needs of your project. Choose PostgreSQL or MySQL for vertical scalability and MongoDB for horizontal scalability.
- Performance Needs: Evaluate your application’s read/write performance needs. PostgreSQL and MySQL are excellent for read-heavy operations, while MongoDB excels in write-heavy scenarios.
- Community and Support: Ensure that the database you choose has good community support and resources, which can be critical for troubleshooting and long-term maintenance.
Choosing the right database is a foundational decision that will influence the performance and scalability of your Strapi application. Carefully assessing your project requirements and understanding the strengths and limitations of each database will help you make an informed choice.
Indexing for Faster Queries
Efficient querying is crucial for maintaining high performance in any application that relies heavily on database interactions. Indexing is a powerful technique to expedite data retrieval by minimizing the amount of data the database engine needs to scan. In this section, we'll delve into how indexing works, best practices for creating and managing indexes, and provide examples specific to popular databases used with Strapi.
Understanding Indexes
A database index is a data structure that improves the speed of data retrieval operations on a database table at the cost of additional writes and storage space. Indexes allow the database to find data more quickly by providing a sorted list of key values.
Why Indexing Matters
Indexes are critical for read-heavy applications, like many Strapi implementations, where users frequently query data. Without proper indexing, query times can become prohibitively long as datasets grow. By optimizing your database schema with indexes, you ensure swift data access, enhancing the overall user experience.
Best Practices for Creating Indexes
-
Index Columns Used in WHERE Clauses:
When a query searches for records based on specific column values, index those columns to speed up the search.
-
Use Composite Indexes for Multi-Column Searches:
If your queries often filter using multiple columns, consider creating composite indexes that include all relevant columns.
-
Index Frequently Joined Columns:
Index columns that are frequently used in JOIN operations to speed up multi-table queries.
-
Avoid Over-Indexing:
While indexing improves read performance, it can slow down write operations and increase storage requirements. Index only when necessary.
-
Regularly Update Statistics:
Ensure that database statistics are up-to-date to help the query optimizer make better decisions.
Indexing Example for Popular Databases
PostgreSQL
PostgreSQL is a popular choice for Strapi projects. Here's how you can add indexes in PostgreSQL:
-- Indexing a single column
CREATE INDEX idx_users_last_name ON users(last_name);
-- Composite index
CREATE INDEX idx_users_last_name_first_name ON users(last_name, first_name);
-- Index for JOIN operation
CREATE INDEX idx_posts_author_id ON posts(author_id);
MongoDB
For MongoDB, indexing can be done using the following commands:
// Single field index
db.users.createIndex({ last_name: 1 });
// Compound index
db.users.createIndex({ last_name: 1, first_name: 1 });
// Indexes for references in joins
db.posts.createIndex({ author_id: 1 });
MySQL
In MySQL, indexing is straightforward and can be done using the following SQL commands:
-- Indexing a single column
CREATE INDEX idx_users_last_name ON users(last_name);
-- Composite index
CREATE INDEX idx_users_last_name_first_name ON users(last_name, first_name);
-- Index for JOIN operation
CREATE INDEX idx_posts_author_id ON posts(author_id);
Monitoring and Maintaining Indexes
Regularly monitor the performance of your indexes. Over time, usage patterns might change, making some indexes less effective. Tools like pg_stat_user_indexes in PostgreSQL, explain plan in MySQL, and the getIndexes method in MongoDB can help you analyze and optimize your indexing strategy.
Conclusion
Effective indexing is one of the most impactful strategies you can employ to boost your Strapi application's database performance. By carefully choosing which columns to index, understanding the trade-offs involved, and continuously monitoring their effectiveness, you can ensure that your application remains responsive as your data grows.
In the next section, we'll explore techniques for optimizing your database schemas to further enhance performance.
Optimizing Database Schemas
Database schema design is foundational to the performance and efficiency of any application, including those built with Strapi. A well-designed schema not only speeds up data retrieval but also reduces redundancy and enhances maintainability. In this section, we'll explore the significance of optimized database schemas and provide practical tips on how to achieve this in your Strapi project.
Understand Your Data and Relationships
Before diving into schema optimization, it's crucial to thoroughly understand your data and how different entities relate to one another. Strapi uses a flexible content-type system, allowing you to define various data models and their relationships, such as one-to-one, one-to-many, and many-to-many.
Normalize Your Database
Normalization involves structuring your database to reduce redundancy and improve data integrity. The first three normal forms (1NF, 2NF, and 3NF) are generally sufficient for most applications:
- First Normal Form (1NF): Ensure that each table cell contains only one value and that each record is unique.
- Second Normal Form (2NF): Ensure that all non-key attributes are fully dependent on the primary key.
- Third Normal Form (3NF): Ensure that all attributes are directly dependent on the primary key and not on other non-key attributes.
Denormalization for Performance
While normalization reduces redundancy, it may sometimes lead to complex queries that can affect performance. In such cases, strategic denormalization—where you deliberately introduce redundancy—can improve query performance. For example, including frequently accessed data in a primary table instead of joining multiple tables.
Use Appropriate Data Types
Choosing the right data types for your fields is crucial:
- Use integer types for IDs and other numerical data.
- Use VARCHAR or TEXT for strings, but avoid overly large types unless necessary.
- Use DATE, TIME, and TIMESTAMP for date and time fields.
Indexing for Speed
Indexes play a significant role in speeding up query performance. Identifying the right fields to index can drastically reduce query times. Common candidates for indexing include:
- Primary Keys and Foreign Keys
- Columns frequently used in WHERE clauses
- Columns frequently used in JOIN operations
For example, in PostgreSQL, you can create an index using the following SQL:
CREATE INDEX idx_user_email ON users(email);
Optimize Relationships
Properly defining relationships can optimize query performance. Strapi allows you to establish relationships at the model definition level in the models directory. Here’s an example of a one-to-many relationship:
// models/user.settings.json
{
"kind": "collectionType",
"connection": "default",
"collectionName": "users",
"attributes": {
"username": {
"type": "string"
},
"posts": {
"collection": "post",
"via": "author"
}
}
}
And the corresponding post.settings.json:
// models/post.settings.json
{
"kind": "collectionType",
"connection": "default",
"collectionName": "posts",
"attributes": {
"title": {
"type": "string"
},
"content": {
"type": "text"
},
"author": {
"model": "user"
}
}
}
Avoid Large Text Fields in Main Tables
Large text fields can slow down operations on a table. Separate such fields into different tables or use text search solutions for better performance. For example, instead of storing an article's content directly in the main articles table, you can use a separate content table linked by a foreign key.
Regular Schema Reviews
Schema requirements can evolve as your application grows. Regular reviews and updates to your schema based on actual usage patterns can ensure it remains optimized. Use schema migration tools to manage changes efficiently and keep your database in top shape.
Monitoring and Analyzing Query Performance
Finally, employ database monitoring tools to continuously analyze query performance. Identify slow queries and refactor them as needed. Tools like PgAdmin for PostgreSQL, MySQL Workbench, and MongoDB Compass can be invaluable for this purpose.
By following these tips, you can ensure that your Strapi application's database schema is well-optimized, reducing redundancy and improving data retrieval times, ultimately leading to a more performant and scalable application.
Caching Strategies
Caching is an essential technique for improving the performance of your Strapi application by reducing the load on the database. By storing frequently accessed data in a cache, you can serve requests more quickly without hitting the database each time. This section explores different caching strategies, including in-memory caching, server-side caching with Redis or Memcached, and browser-side caching.
In-Memory Caching
In-memory caching stores data in the server's RAM, which allows for super-fast data retrieval. Strapi can take advantage of in-memory caching to store the results of frequently accessed queries.
Here's an example of how you might implement in-memory caching in your Strapi application using the node-cache package:
npm install node-cache
const NodeCache = require("node-cache");
const myCache = new NodeCache({ stdTTL: 100, checkperiod: 120 });
async function getCachedData(key, dataFetcher) {
let value = myCache.get(key);
if (value === undefined) {
// Key does not exist in cache
value = await dataFetcher();
myCache.set(key, value);
}
return value;
}
This simple caching mechanism allows you to cache frequently accessed data, reducing the need to query the database repeatedly.
Server-Side Caching with Redis or Memcached
For more robust server-side caching, Redis and Memcached are two of the most popular solutions. Both are in-memory key-value stores that can greatly enhance the performance of your Strapi application.
Redis
Redis is an open-source, in-memory data structure store that offers high performance and rich features like persistence, replication, and pub/sub messaging.
To integrate Redis with Strapi, you need to install the Redis client:
npm install redis
Then, you can configure and use Redis in your Strapi service:
const redis = require("redis");
const client = redis.createClient();
client.on("error", (err) => {
console.log("Redis error: ", err);
});
async function getCachedData(key, dataFetcher) {
return new Promise((resolve, reject) => {
client.get(key, async (err, result) => {
if (err) return reject(err);
if (result) {
resolve(JSON.parse(result));
} else {
const data = await dataFetcher();
client.set(key, JSON.stringify(data));
resolve(data);
}
});
});
}
Memcached
Memcached is another high-performance, distributed memory caching system. It is simple, easy to deploy, and effective for speeding up dynamic web applications by alleviating database load.
To use Memcached with Strapi, first install the Memcached client:
npm install memjs
Then, configure and implement caching in your Strapi service:
const Memcached = require("memjs");
const client = Memcached.Client.create();
async function getCachedData(key, dataFetcher) {
return new Promise((resolve, reject) => {
client.get(key, async (err, result) => {
if (err) return reject(err);
if (result) {
resolve(JSON.parse(result));
} else {
const data = await dataFetcher();
client.set(key, JSON.stringify(data));
resolve(data);
}
});
});
}
Browser-Side Caching
Browser-side caching can also play a role in reducing database load by leveraging the client's web browser to cache static assets and API responses. This can be achieved through HTTP headers and techniques like Service Workers.
HTTP Headers
Setting proper caching HTTP headers on your API responses can help the browser cache results locally. You can configure these headers in your Strapi middleware:
module.exports = {
load: {
before: [],
after: [],
order: [
"Define the middlewares' load order by putting their name in this array in the desired order"
],
settings: {
poweredBy: {
enabled: true,
value: 'Strapi <your application>'
},
cacheControl: {
maxAge: 3600,
mustRevalidate: true
},
},
},
};
Service Workers
Service Workers offer more fine-grained control over browser caching. With Service Workers, you can intercept network requests and serve responses from a local cache.
Here's a basic Service Worker example:
self.addEventListener('install', (event) => {
event.waitUntil(
caches.open('my-cache').then((cache) => {
return cache.addAll(['/api/content']);
})
);
});
self.addEventListener('fetch', (event) => {
event.respondWith(
caches.match(event.request).then((response) => {
return response || fetch(event.request);
})
);
});
Conclusion
By implementing these caching strategies, you can significantly reduce the load on your Strapi application's database, resulting in faster response times and improved scalability. Whether you opt for in-memory caching, server-side solutions like Redis or Memcached, or utilize browser-side caching techniques, these optimizations will enhance the performance and responsiveness of your Strapi-based project.
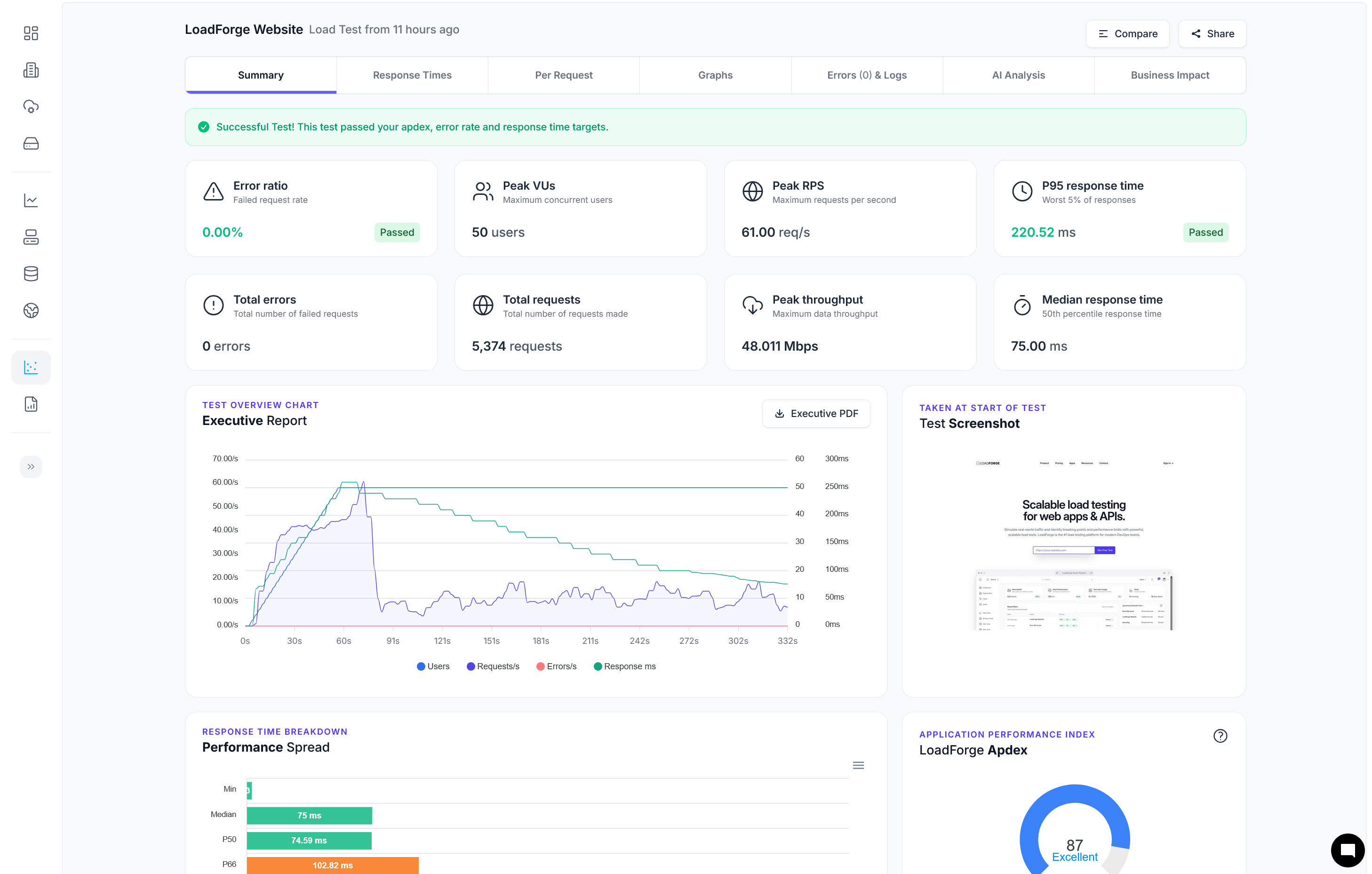
Load Testing with LoadForge
Load testing is a crucial step in ensuring your Strapi application and its database can handle various levels of traffic without compromising performance. In this section, we will introduce LoadForge, a powerful tool for load testing, and guide you through the process of performing load tests on your Strapi application. We will also emphasize the importance of testing under different load scenarios to understand the database performance under stress.
What is LoadForge?
LoadForge is a comprehensive load testing platform designed to simulate real-world traffic to your application. It helps you identify performance bottlenecks and understand how your Strapi application behaves under different loads. With LoadForge, you can create complex load scenarios, simulate thousands of concurrent users, and gain valuable insights into your application's performance.
Setting Up LoadForge for Strapi
To get started with LoadForge, you need to sign up for an account and create a new project for your Strapi application. Follow these steps to set up LoadForge for load testing your Strapi project:
-
Sign Up and Create a Project:
- Visit the LoadForge website and sign up for an account.
- Create a new project and provide a name and description for your Strapi application.
-
Configure Load Scenarios:
- Define the load scenarios you want to test. This could include different levels of concurrent users, varying request rates, and specific endpoints to test.
- Configure the HTTP methods (GET, POST, PUT, DELETE) and include any necessary request headers or payloads.
-
Set Up Test Environment:
- Ensure your Strapi application is deployed and accessible. You may want to use a staging environment to avoid impacting your production data.
- Configure LoadForge to point to your Strapi application's base URL.
Performing Load Tests
Once your LoadForge project is set up, you can start performing load tests to evaluate your Strapi application's database performance. Here is a basic example of how to set up a load test scenario:
{
"scenarioName": "Strapi Load Test",
"endpoints": [
{
"url": "/articles",
"method": "GET",
"weight": 70
},
{
"url": "/comments",
"method": "POST",
"body": {
"articleId": "12345",
"content": "This is a test comment."
},
"weight": 30
}
],
"concurrentUsers": 100,
"duration": 600
}
In this example:
- We test two endpoints: fetching articles (
GET /articles) and submitting comments (POST /comments).
- The
weight parameter specifies the probability of each request type within the test. Here, 70% of the requests will be for fetching articles, and 30% will be for posting comments.
- We simulate 100 concurrent users for a duration of 600 seconds (10 minutes).
Analyzing Load Test Results
After running your load tests, LoadForge provides detailed reports and metrics to help you understand the performance of your Strapi application. The key metrics to pay attention to include:
- Response Time: Measure the time taken for the database to respond to various queries.
- Error Rate: Identify any errors that occurred during the test, such as timeouts or database connection issues.
- Throughput: Assess the number of requests processed per second.
- CPU and Memory Usage: Monitor the resource usage of your database server under load.
By analyzing these metrics, you can pinpoint performance bottlenecks and identify areas for optimization.
Importance of Testing Under Different Loads
Testing under different loads is essential to understanding how your Strapi application's database performs under various traffic conditions. Here are a few scenarios to consider:
- Low Load: Simulate a minimal number of concurrent users to establish a baseline for performance.
- Moderate Load: Gradually increase the number of concurrent users to observe how the application scales.
- High Load: Push the system to its limits to identify potential breaking points and stress test the database.
By performing load tests under these scenarios, you can ensure your Strapi application remains performant and reliable, even as traffic increases.
Overall, LoadForge is an invaluable tool for load testing your Strapi application, helping you understand and optimize database performance to handle real-world traffic efficiently.
Data Purging and Archiving
Managing the data lifecycle is crucial for maintaining optimal database performance in Strapi. Over time, your database can accumulate a significant amount of old or unused data, which can slow down queries and degrade performance. This section discusses the practice of purging and archiving data to keep your database lean and efficient, while ensuring that important data is not lost.
The Importance of Data Purging
Data purging involves removing outdated or irrelevant data from your database. By doing this, you can:
- Improve Query Performance: With less data to scan, queries execute faster.
- Reduce Storage Costs: Smaller databases require less storage, which can reduce costs.
- Save on Backup and Recovery Times: Smaller databases are quicker to backup and restore.
Identifying Data for Purging
To effectively purge data, you need to identify what data can be safely removed. Common candidates for purging include:
- Logs and Audit Trails: Old log entries and audit trails that are no longer needed.
- Temporary Data: Data used for temporary purposes that are no longer relevant.
- Soft-Deleted Records: Items that have been marked for deletion but are still stored in the database.
Example: Purging Old Log Entries
Here’s an example SQL query to delete log entries older than a specific date:
DELETE FROM logs WHERE createdAt < NOW() - INTERVAL '6 months';
Archiving Strategies
Archiving involves moving old data to a secondary storage for long-term retention. This way, you keep your main database lean without losing historical data. Common archiving strategies include:
- Cold Storage: Move old data to a less costly, less performant storage solution.
- Data Warehousing: Transfer historical data to a data warehouse designed for analytical queries.
- Export Files: Regularly back up and export old data to CSV, JSON, or other file formats for archival.
Example: Archiving Data to a Data Warehouse
You can create a script to move data from your primary database to an archival database. Here's a pseudocode example:
-- Insert old data into archive table
INSERT INTO archived_orders SELECT * FROM orders WHERE createdAt < NOW() - INTERVAL '1 year';
-- Delete old data from primary table
DELETE FROM orders WHERE createdAt < NOW() - INTERVAL '1 year';
Automation of Purging and Archiving
Automate the purging and archiving processes using scheduled jobs or cron tasks. This ensures that your database maintenance is consistent and does not depend on manual intervention.
Example: Setting Up a Cron Job
In a Unix-like system, you can set up a cron job to run your purging script regularly. Here’s an example crontab entry to run a purging script every month:
0 0 1 * * /path/to/purging-script.sh
Best Practices for Data Purging and Archiving
- Regular Maintenance: Schedule regular purging and archiving to prevent data bloat.
- Monitoring: Monitor your database growth and performance to adjust your purging and archiving strategy as needed.
- Compliance: Ensure that your data retention and purging policies comply with relevant regulations and industry standards.
Conclusion
Periodic data purging and archiving play a critical role in maintaining database performance in Strapi. By identifying old or unused data and implementing efficient purging and archiving strategies, you can significantly improve query performance, reduce storage costs, and streamline your backup and recovery processes. Stay proactive with automated scripts and regular maintenance to keep your Strapi database running smoothly.
In the next sections, we will discuss more advanced techniques to continue optimizing your Strapi database for top-notch performance.
Feel free to copy this markdown content directly into your guide. This section emphasizes the importance of data purging and archiving, provides practical examples, and offers best practices to ensure your Strapi database remains efficient and performant.
Query Optimization
Optimizing queries is a fundamental step in enhancing the performance of your Strapi application. Efficient queries not only fetch data quicker but also reduce the load on your database, resulting in faster response times and improved user experiences. Here, we explore techniques and best practices for writing optimized queries, while identifying common pitfalls and showing how to avoid them.
Understanding Query Optimization
Before diving into specific techniques, it’s essential to understand the basics of query optimization:
- Minimize Data Retrieval: Only fetch the data you need.
- Use Simple Queries: Avoid overly complex queries that can slow down execution.
- Monitor and Analyze: Use tools to analyze and monitor query performance.
Best Practices for Writing Optimized Queries
1. Select Only Necessary Columns
Fetching unnecessary columns consumes additional memory and processing power. Instead of using SELECT *, specify only the columns needed.
Inefficient Query:
SELECT * FROM users;
Optimized Query:
SELECT id, username, email FROM users;
2. Avoid N+1 Query Problem
The N+1 query problem occurs when a query is made to retrieve a list of items (N) and then N individual queries are made to retrieve additional details. Use JOINs or eager loading to mitigate this issue.
Example with N+1 Problem:
// Assume this is a simplified pseudocode to represent the problem
const posts = await strapi.services.posts.find();
for (let post of posts) {
post.author = await strapi.services.users.findOne({ id: post.authorId });
}
Optimized Query:
// Using populate to retrieve related data in one go
const posts = await strapi.services.posts.find({ _populate: 'author' });
3. Use Proper Filtering and Pagination
Fetching large datasets can be costly. Use filters and pagination to limit the number of records returned.
Inefficient Query:
SELECT id, username FROM users;
Optimized Query with Filtering and Pagination:
SELECT id, username FROM users WHERE status = 'active' LIMIT 10 OFFSET 20;
4. Use Indexes Wisely
Indexes speed up data retrieval but slow down insert and update operations. Ensure indexes are used on columns frequently queried but balance their usage to avoid performance degradation during writes.
Example of Creating an Index:
CREATE INDEX idx_user_email ON users(email);
5. Avoid Using Functions in Predicates
Using functions on indexed columns in predicates can negate the advantages of indexing.
Inefficient Query:
SELECT id FROM users WHERE LOWER(email) = 'user@example.com';
Optimized Query:
Ensure the column data is stored in a consistent case format, eliminating the need for functions in the query predicate:
SELECT id FROM users WHERE email = 'user@example.com';
Common Pitfalls and How to Avoid Them
1. Overusing Subqueries
Subqueries can be expensive and sometimes a JOIN or a UNION operation can achieve the same goal more efficiently.
2. Ignoring Query Execution Plans
Database management systems (DBMS) provide query execution plans that help understand how queries are executed. Analyzing execution plans can reveal inefficiencies.
3. Skipping Batch Processing
Instead of inserting or updating rows one at a time, use batch processing to handle multiple rows in a single transaction.
Example of Batch Insertion:
INSERT INTO users (id, username, email) VALUES
(1, 'user1', 'user1@example.com'),
(2, 'user2', 'user2@example.com');
Tools for Query Optimization
Utilize database-specific tools to analyze and optimize your queries. Here are some popular ones:
- PostgreSQL:
EXPLAIN ANALYZE for execution plans.
- MySQL:
EXPLAIN for query profiling.
- MongoDB:
.explain("executionStats") to get execution statistics.
Conclusion
Efficient query writing is a mix of art and science that requires understanding both the applications' needs and the database's workings. By following these best practices and being aware of common pitfalls, you can significantly enhance the performance of your Strapi application. Regularly monitor your queries and refine them to ensure sustained performance improvements.
Connection Pooling
Connection pooling is a critical technique for managing database connections more efficiently in any application, including those built with Strapi. By reusing a set of established connections rather than opening new ones for each request, connection pooling reduces the overhead associated with database connectivity and improves overall application performance.
What is Connection Pooling?
Connection pooling maintains a cache of database connections that can be reused for future requests, rather than creating a new one each time a request is made. This reuse drastically reduces the time spent on establishing and tearing down connections, leading to faster query executions and reduced resource consumption on both the application and database servers.
Benefits of Connection Pooling
- Reduced Latency: By reusing connections, the time-consuming process of establishing new connections is avoided, reducing the latency of database interactions.
- Resource Efficiency: Connection pooling conserves server resources by maintaining a fixed number of open connections, minimizing the overhead associated with creating and destroying connections.
- Improved Throughput: Efficient connection management allows the application to handle more concurrent requests, increasing its throughput and scalability.
- Enhanced Stability: Properly managed connection pools help maintain a stable and predictable database load, reducing the risk of connection exhaustion and related errors.
Configuration Tips for Connection Pooling in Strapi
Configuring connection pooling in Strapi involves setting up your database connector to use a pool of reusable connections. Below are some best practices and configuration examples to help you get started.
Example with PostgreSQL and knex
Strapi uses knex as the query builder under the hood for SQL-based databases like PostgreSQL, MySQL, and SQLite. Here's how you can configure connection pooling with a PostgreSQL database in Strapi.
-
Locate Your Database Configuration:
Your database configuration can be found in config/database.js.
-
Add Connection Pool Settings:
You can add the pool settings within your database configuration as shown below:
module.exports = ({ env }) => ({
connection: {
client: 'postgres',
connection: {
host: env('DATABASE_HOST', '127.0.0.1'),
port: env.int('DATABASE_PORT', 5432),
database: env('DATABASE_NAME', 'strapi'),
user: env('DATABASE_USERNAME', 'strapi'),
password: env('DATABASE_PASSWORD', 'strapi'),
ssl: env.bool('DATABASE_SSL', false),
},
pool: {
min: 2,
max: 10,
},
},
});
In the example above, the pool object specifies that the minimum number of connections in the pool is 2, and the maximum number of connections is 10. These parameters can be adjusted based on your application's needs and the capacity of your database server.
Best Practices for Connection Pooling
- Determine Optimal Pool Size: Start with a modest pool size and monitor your database performance. Increase the pool size incrementally while observing the impact on latency, throughput, and resource utilization until you find an optimal configuration.
- Set Connection Timeouts: Ensure that your connection pool has timeouts set to close idle connections after a certain period. This helps in freeing up resources and avoiding unnecessary open connections.
- Monitor Pool Performance: Use database monitoring tools to keep track of connection pool metrics like open connections, idle connections, and request queues. This information can help you identify and resolve connection-related performance bottlenecks.
- Optimize Query Performance: Even with an efficient connection pool, poorly optimized queries can lead to performance degradation. Ensure your queries are well-indexed and optimized to make the best use of pooled connections.
- Leverage Load Testing: Use LoadForge to simulate different load scenarios and understand how your connection pool performs under stress. This will help you tweak your pool settings to handle peak loads efficiently.
By following these tips and best practices, you can effectively use connection pooling in Strapi to enhance your database performance and ensure your application can handle increased loads gracefully.
Conclusion
Connection pooling is a vital aspect of managing database connections in Strapi applications. With the right configuration and best practices, you can significantly improve database interaction efficiency, leading to better overall application performance. In the next sections, we will explore more optimization techniques such as query optimization, caching strategies, and load testing to ensure your Strapi application runs at peak performance.
This section covers the concept, benefits, and best practices of connection pooling in Strapi, providing a detailed configuration example and emphasizing the importance of ongoing monitoring and optimization. The guide will continue with further techniques to ensure overall optimal database performance for Strapi applications.
## Database Monitoring Tools
Effective database monitoring is a critical aspect of maintaining optimal performance in your Strapi application. By utilizing the right tools, you can gain valuable insights into performance metrics, identify bottlenecks, and troubleshoot issues proactively. In this section, we'll highlight various database monitoring tools that can help you track performance metrics and optimize your Strapi database.
### Popular Database Monitoring Tools
#### 1. **New Relic**
New Relic is a comprehensive monitoring tool that provides real-time insights into your database performance. It offers detailed analytics, transaction tracing, and custom dashboards, making it easier to pinpoint and resolve performance issues.
**Key Features:**
- Real-time database monitoring
- Detailed transaction traces
- Anomaly detection
- Customizable dashboards
**Using New Relic with Strapi:**
To integrate New Relic with Strapi, you would typically install the New Relic APM (Application Performance Monitoring) agent in your Node.js environment. Here is a basic example:
<pre><code>
// Install New Relic
npm install newrelic --save
// Create a newrelic.js file in the root directory
// Add the required configuration settings in the new relic.js file
</code></pre>
#### 2. **Prometheus and Grafana**
Prometheus, when combined with Grafana, provides a powerful open-source solution for monitoring and alerting. Prometheus is used to scrape and store metrics, while Grafana visualizes these metrics through customizable dashboards.
**Key Features:**
- Metric scraping and storage with Prometheus
- Customizable and interactive dashboards with Grafana
- Powerful query language (PromQL)
- Alerting and notification capabilities
**Using Prometheus and Grafana with Strapi:**
To monitor a Strapi database with Prometheus and Grafana, you would need to set up Prometheus to scrape metrics from your database and configure Grafana to display these metrics. An example configuration might look like this:
<pre><code>
// Prometheus configuration
scrape_configs:
- job_name: 'my-database'
static_configs:
- targets: ['localhost:5432']
</code></pre>
#### 3. **Datadog**
Datadog provides end-to-end monitoring with support for numerous integrations, including databases like PostgreSQL, MongoDB, and MySQL. It offers rich visualizations, alerting, and advanced analytics to help you monitor and optimize your database performance.
**Key Features:**
- Integration with a wide range of databases
- Real-time performance monitoring
- Advanced analytics and visualizations
- Customizable alerting system
**Using Datadog with Strapi:**
To get started with Datadog, you need to install and configure the Datadog Agent in your environment. Here's a basic setup example:
<pre><code>
// Install Datadog Agent
DD_AGENT_MAJOR_VERSION=7 DD_API_KEY=your_api_key DD_SITE="datadoghq.com" bash -c "$(curl -L https://s3.amazonaws.com/dd-agent/scripts/install_script.sh)"
// Configure the Datadog Agent for your database (e.g., PostgreSQL)
sudo vim /etc/datadog-agent/conf.d/postgres.d/conf.yaml
// Example configuration:
init_config:
instances:
- host: localhost
port: 5432
username: datadog
password: your_password
dbname: strapi_database
</code></pre>
### Identifying and Troubleshooting Performance Bottlenecks
Once you have set up your preferred monitoring tool, the next step is to use the gathered data to identify and troubleshoot performance bottlenecks. Here are some tips on what to look for:
1. **Slow Queries:** Identify slow SQL queries that may be impacting performance. Use the monitoring tool's query analytics feature to examine execution times and optimize these queries.
2. **High Resource Consumption:** Monitor CPU, memory, and I/O usage. Excessive consumption in any of these areas can lead to performance issues. Investigate the root cause and consider optimizing your database schema or adding indexes.
3. **Connection Issues:** Track the number of active connections and look for connection spikes or errors. Consider implementing connection pooling to manage connections efficiently.
4. **Cache Efficiency:** If you're using caching solutions like Redis or Memcached, monitor cache hit and miss rates. A high miss rate may indicate that your cache strategy needs adjustment.
### Conclusion
Database monitoring tools are essential for maintaining and optimizing the performance of your Strapi applications. By leveraging tools like New Relic, Prometheus & Grafana, and Datadog, you can gain actionable insights into your database performance, identify bottlenecks, and ensure your application runs smoothly. Regular monitoring and proactive troubleshooting will help you maintain a high-performance, reliable Strapi application.
## Backup and Recovery Plans
In any database-centric application, having a robust backup and recovery plan is non-negotiable. A good backup plan ensures that your data is safe from accidental deletions, hardware failures, and other unforeseen incidents, while an efficient recovery strategy ensures that downtime is minimized and data integrity is maintained. This section will guide you through setting up regular backups and quick restoration processes for your Strapi-driven database.
### Importance of Backup and Recovery
The value of your data cannot be overstated. Reliable backups and recovery plans help you:
- **Prevent Data Loss:** Safeguard critical data from being permanently lost.
- **Minimize Downtime:** Quickly restore services and reduce business disruption.
- **Ensure Data Integrity:** Maintain the accuracy and completeness of your data.
- **Comply with Regulations:** Meet legal and compliance requirements regarding data retention.
### Setting Up Regular Backups
Regular backups are the cornerstone of any disaster recovery plan. Here’s how you can set up automatic backups for some commonly used databases with Strapi.
#### PostgreSQL
For PostgreSQL, you can use the `pg_dump` tool to create backups. Here’s an example:
<pre><code>
pg_dump -U username -h hostname -F c -b -v -f /path/to/backup/file.backup database_name
</code></pre>
- `-U username`: Specifies the username to connect to the database.
- `-h hostname`: The database server's hostname.
- `-F c`: Outputs a custom-format archive suitable for large databases.
- `-b`: Includes large objects in the dump.
- `-v`: Provides verbose output.
- `-f /path/to/backup/file.backup`: Specifies the file path for storing the backup.
- `database_name`: The name of the database to back up.
You can automate this command using a cron job or a similar scheduling tool.
#### MongoDB
For MongoDB, the `mongodump` utility is used:
<pre><code>
mongodump --db database_name --out /path/to/backup/directory
</code></pre>
- `--db database_name`: Specifies the database name to be backed up.
- `--out /path/to/backup/directory`: The directory where the backup files will be stored.
#### MySQL
For MySQL, `mysqldump` is the go-to command:
<pre><code>
mysqldump -u username -p'password' database_name > /path/to/backup/file.sql
</code></pre>
- `-u username`: Username to connect with.
- `-p'password'`: Password for the user (note the no-space after `-p`).
- `database_name`: The name of the database.
- `/path/to/backup/file.sql`: The file path for storing the backup.
### Quick Restoration Processes
A backup is only as good as your ability to restore it. Here are the restoration commands for the databases we’ve discussed.
#### PostgreSQL
To restore a PostgreSQL backup created with `pg_dump`, use `pg_restore`:
<pre><code>
pg_restore -U username -d database_name -v /path/to/backup/file.backup
</code></pre>
- `-U username`: The username to connect as.
- `-d database_name`: The name of the database to restore.
- `-v`: Verbose mode.
- `/path/to/backup/file.backup`: Path to the backup file.
#### MongoDB
For MongoDB, the `mongorestore` command is used:
<pre><code>
mongorestore --db database_name /path/to/backup/directory/database_name
</code></pre>
- `--db database_name`: Specifies the database name.
- `/path/to/backup/directory/database_name`: The backup directory containing the dump.
#### MySQL
For MySQL, you can use the `mysql` command to restore a dump:
<pre><code>
mysql -u username -p'password' database_name < /path/to/backup/file.sql
</code></pre>
- `-u username`: Username to connect with.
- `-p'password'`: Password for the user.
- `database_name`: The database name.
- `/path/to/backup/file.sql`: Path to the SQL backup file.
### Best Practices for Backup and Recovery
- **Automate Backups:** Use cron jobs, systemd timers, or other scheduling tools to automate the backup process.
- **Test Restorations:** Regularly test your restoration process to ensure the backups are usable and the recovery steps are clear.
- **Offsite Storage:** Store backups in multiple locations, including offsite or cloud storage, to protect against physical damage or theft.
- **Monitor and Alert:** Set up monitoring and alerting for your backup processes to catch failures early.
- **Document Procedures:** Maintain clear, detailed documentation of your backup and recovery procedures for quick action during emergencies.
### Conclusion
Setting up and maintaining reliable backup and recovery plans is an essential task for any Strapi application. By following the guidelines and best practices outlined in this section, you can ensure that your data is secure, minimize potential downtime, and maintain the overall integrity of your application. Stay vigilant, and regularly review and update your backup strategies to adapt to any changes in your infrastructure or business needs.
## Maintaining Database Health
Ensuring the ongoing health of your database is critical for maintaining optimal performance in your Strapi application. Regular maintenance tasks and best practices will help you avoid performance bottlenecks, prevent data corruption, and extend the longevity of your database. Below, we outline key strategies and best practices for maintaining database health.
### Routine Maintenance Tasks
Performing routine maintenance tasks can significantly impact the efficiency and reliability of your database. Here are some essential maintenance activities:
1. **Database Vacuuming (for PostgreSQL):**
- Regularly vacuum your PostgreSQL database to reclaim storage, manage bloat, and update stale statistics. This can be automated using a scheduled job.
```sql
VACUUM FULL;
ANALYZE;
-
Index Rebuilding:
- Indexes can become fragmented over time, reducing their effectiveness. Periodically rebuild indexes to ensure they remain optimized.
REINDEX INDEX index_name;
-
Table Optimization (for MySQL):
- Run the
OPTIMIZE TABLE command to re-organize and defragment table data for improved performance.
OPTIMIZE TABLE table_name;
-
Consistency Checks:
- Regularly perform integrity checks to catch and address corruption or inconsistencies in your database.
CHECK TABLE table_name;
Best Practices for Long-Term Performance
Adopting the following best practices will ensure your database remains healthy over the long term:
-
Regular Backups:
- Schedule regular backups of your database to prevent data loss. Ensure backups are stored securely and tested periodically for restoreability.
-
Monitoring and Alerts:
- Implement monitoring tools to track key performance metrics such as CPU usage, memory usage, and I/O operations. Set up alerts to notify you of anomalies or thresholds being breached.
Tools like pgAdmin for PostgreSQL, MySQL Workbench for MySQL, or third-party solutions like DataDog can be very effective.
-
Security Best Practices:
- Regularly update database software and apply security patches.
- Perform security audits to identify and mitigate vulnerabilities.
- Use strong authentication and encryption for database connections.
-
Configuration Tuning:
- Review and tune database configurations to match the workload of your Strapi application. For example, adjust parameters related to connection limits, cache sizes, and memory allocation.
# example for PostgreSQL configuration tuning
shared_buffers = 256MB
work_mem = 64MB
-
Load Testing with LoadForge:
- Periodically perform load tests using LoadForge to understand how your database performs under various loads. Load testing helps identify performance bottlenecks before they impact your end-users.
Archiving Old Data
Archiving outdated or seldom-accessed data helps keep your database lean and responsive. Develop a strategy to move historical data to an archive, keeping only the most relevant and recent data in your primary database.
-- Example of archiving old data to a separate table
INSERT INTO archive_table
SELECT * FROM main_table
WHERE created_at < NOW() - INTERVAL '1 year';
DELETE FROM main_table
WHERE created_at < NOW() - INTERVAL '1 year';
Conclusion
Regular maintenance and adherence to best practices are essential for sustaining the health and performance of your database in a Strapi application. Through periodic vacuuming, indexing, consistent monitoring, and thoughtful configuration, you can ensure your database remains efficient and reliable.
For further reading on database optimization techniques, be sure to explore the additional resources provided in the concluding section of this guide.
Conclusion and Further Reading
In this guide, we have explored various database optimization techniques to enhance the performance of your Strapi application. Ensuring that your database is efficient and responsive is vital for the overall scalability and user experience of your Strapi-powered projects. Let's summarize the key points we've covered:
Summary of Key Points
-
Introduction to Strapi and Database Performance:
- Strapi's architecture and the importance of database performance were highlighted, setting the context for optimization.
-
Choosing the Right Database:
- Discussed options such as PostgreSQL, MongoDB, and MySQL, and their implications on performance. Emphasized the importance of selecting a database that aligns with your project's requirements.
-
Indexing for Faster Queries:
- The importance and methodology of creating indexes were elaborated with examples for popular databases to speed up query performance.
-
Optimizing Database Schemas:
- Tips for designing well-structured database schemas to reduce redundancy and improve data retrieval times.
-
Caching Strategies:
- Explored in-memory caching, server-side caching with Redis or Memcached, and browser-side caching to reduce database load.
-
Load Testing with LoadForge:
- Introduced LoadForge and demonstrated how to perform load testing to evaluate database performance under different loads.
-
Data Purging and Archiving:
- Discussed strategies for purging old or unused data and archiving to keep the database lean and efficient.
-
Query Optimization:
- Focused on writing efficient queries, avoiding common pitfalls, and examples to ensure faster execution times.
-
Connection Pooling:
- Explained how connection pooling can help manage database connections efficiently and provided configuration tips for Strapi.
-
Database Monitoring Tools:
- Highlighted various tools to monitor and track database performance metrics to identify and troubleshoot bottlenecks.
-
Backup and Recovery Plans:
- Emphasized the importance of regular backups and swift restoration processes in case of database failures.
-
Maintaining Database Health:
- Provided ongoing maintenance tips and best practices for long-term database health.
Further Reading
For those looking to delve deeper into Strapi and database optimization, here are some additional resources:
-
Strapi Documentation:
- Official documentation for comprehensive guides and pieces of information.
- Strapi Docs
-
Database Specific Optimization Guides:
-
Caching Techniques:
-
Load Testing with LoadForge:
- Learn how to effectively use LoadForge for load testing to simulate different user loads and understand performance impacts.
- LoadForge Home
-
Database Lifecycle Management:
In conclusion, adopting these database optimization techniques will significantly improve the performance and scalability of your Strapi applications. Regular monitoring and maintenance, coupled with strategic optimization practices, will ensure your database remains efficient and responsive under varying loads. Happy optimizing!