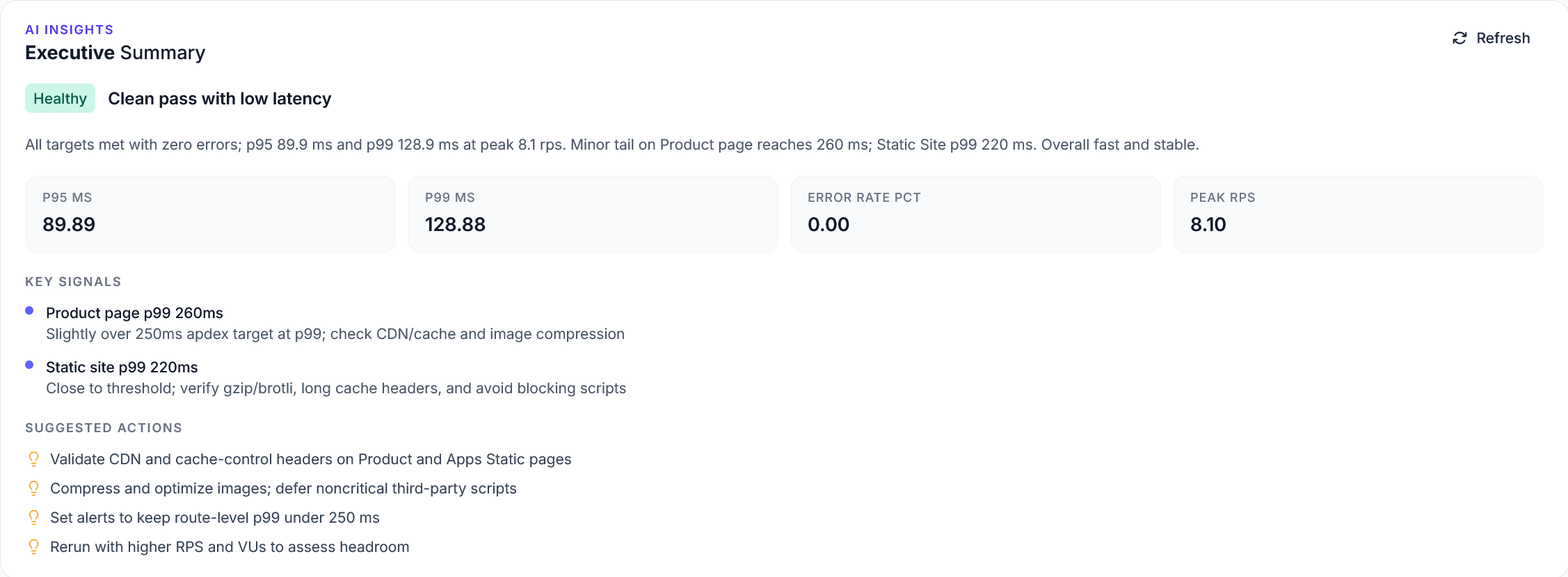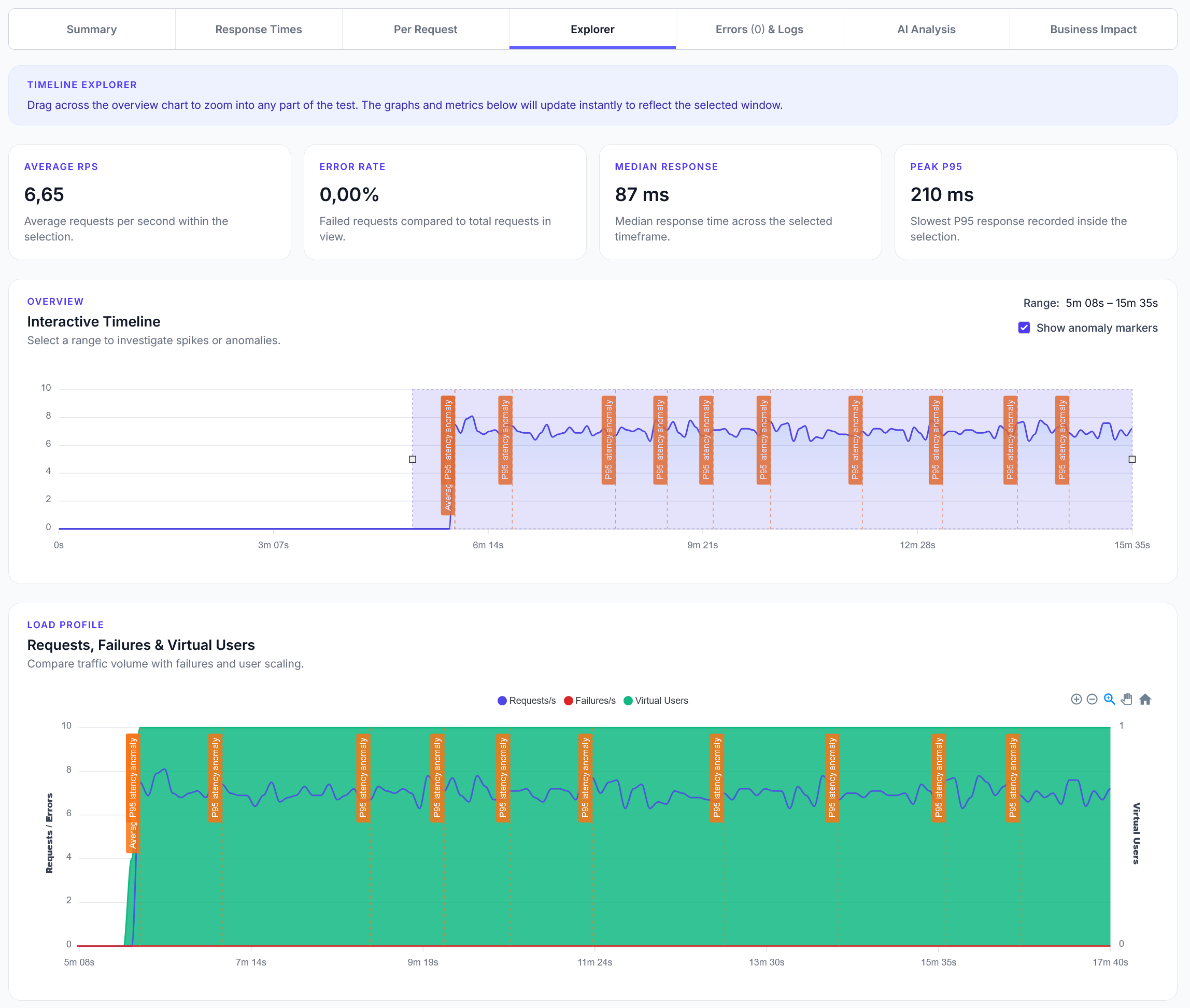
Explorer reports addition
We have added a new Explorer feature to reports, with a timeline scrubber and easy anomaly detection.
An example guide on how to effectively load test your ReactJS application utilizing Locust and LoadForge.
LoadForge can record your browser, graphically build tests, scan your site with a wizard and more. Sign up now to run your first test.
In this guide, we shall explore the process of creating a load test for a React.js website using Locust, and executing it via LoadForge. This particular test can be applied to any JavaScript-based site (React, Next, Nuxt, etc) as it automatically crawls URLs on the site and uses those in the load test.
LoadForge provides a wealth of additional features like authentication, session maintenance, and more. Navigate through the documentation for specifics on your testing needs, or use the LoadForge account's wizard or AI test generator to set up the test for you.
Before starting, ensure you:
LoadForge instances are outfitted with several useful tools, one of which is beautifulsoup4, utilized for parsing HTML content in this test. To install it locally for test development, use the following command:
pip install locust beautifulsoup4
The following example illustrates a user that crawls a webpage, identifies and loads linked pages and static content (like images, CSS, JS files). You can insert this locustfile directly into LoadForge to test your React.js website.
from bs4 import BeautifulSoup
from locust import HttpUser, task, between
class WebsiteUser(HttpUser):
wait_time = between(1, 2.5)
def on_start(self):
self.crawl("/")
def crawl(self, path):
response = self.client.get(path, name="[Page] "+path)
if response.status_code == 200:
soup = BeautifulSoup(response.text, "html.parser")
# Discover linked pages
links = [a["href"] for a in soup.find_all("a", href=True)]
for link in links:
self.crawl(link)
# Load static content (img, css, js)
resources = [(link["href"], "CSS") for link in soup.find_all("link", href=True)]
resources += [(script["src"], "JS") for script in soup.find_all("script", src=True)]
resources += [(img["src"], "IMG") for img in soup.find_all("img", src=True)]
for resource, res_type in resources:
self.client.get(resource, name=f"[{res_type}] {resource}")
@task(1)
def load_homepage(self):
self.client.get("/")
on_start: Triggers the crawling of the homepage once per simulated user.crawl: A recursive function performing GET requests to paths, discovering and loading other linked resources.@task(1): Imitates users perpetually loading the homepage.This guide has laid out a fundamental setup for load testing a React.js website, performing crawling, and discovering links/resources. Be sure to refine and modify your locustfile based on actual user interactions, website structure, and testing goals.
LoadForge builds upon the sturdy foundation offered by Locust, ensuring seamless adoption of scripts by users familiar with open-source Locust. If you're already using Locust, consider integrating your script with LoadForge to enhance your testing capabilities!