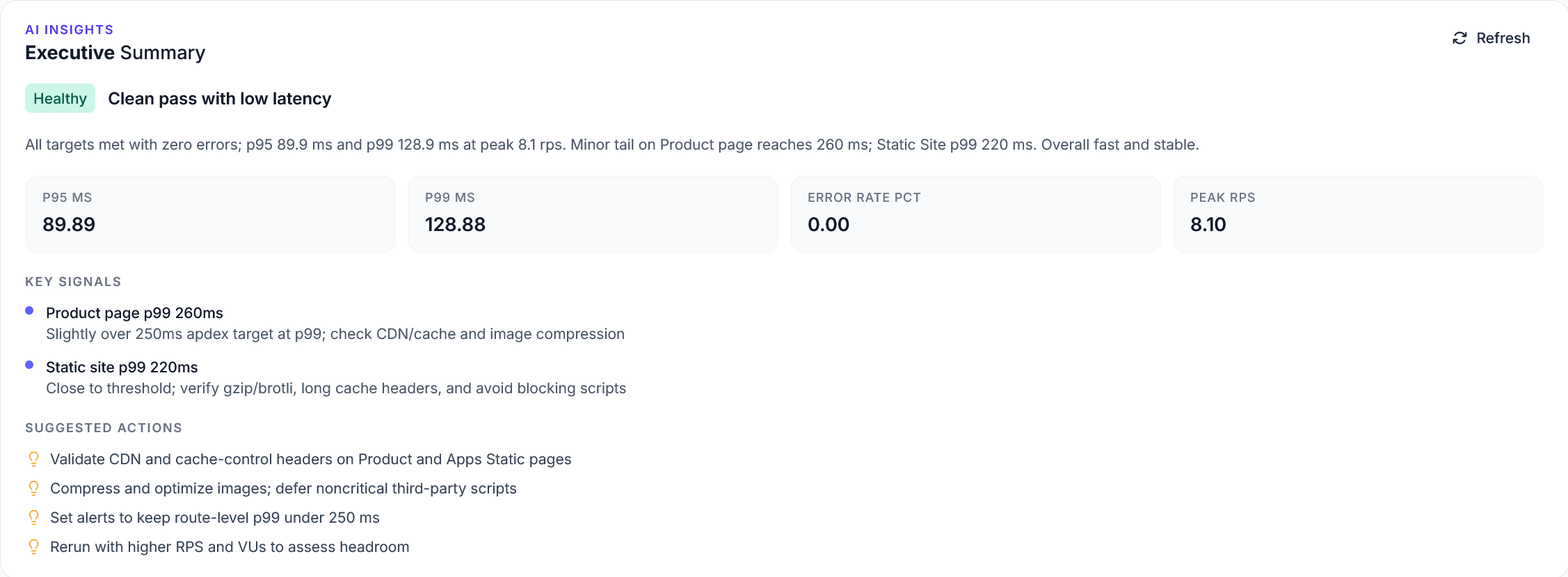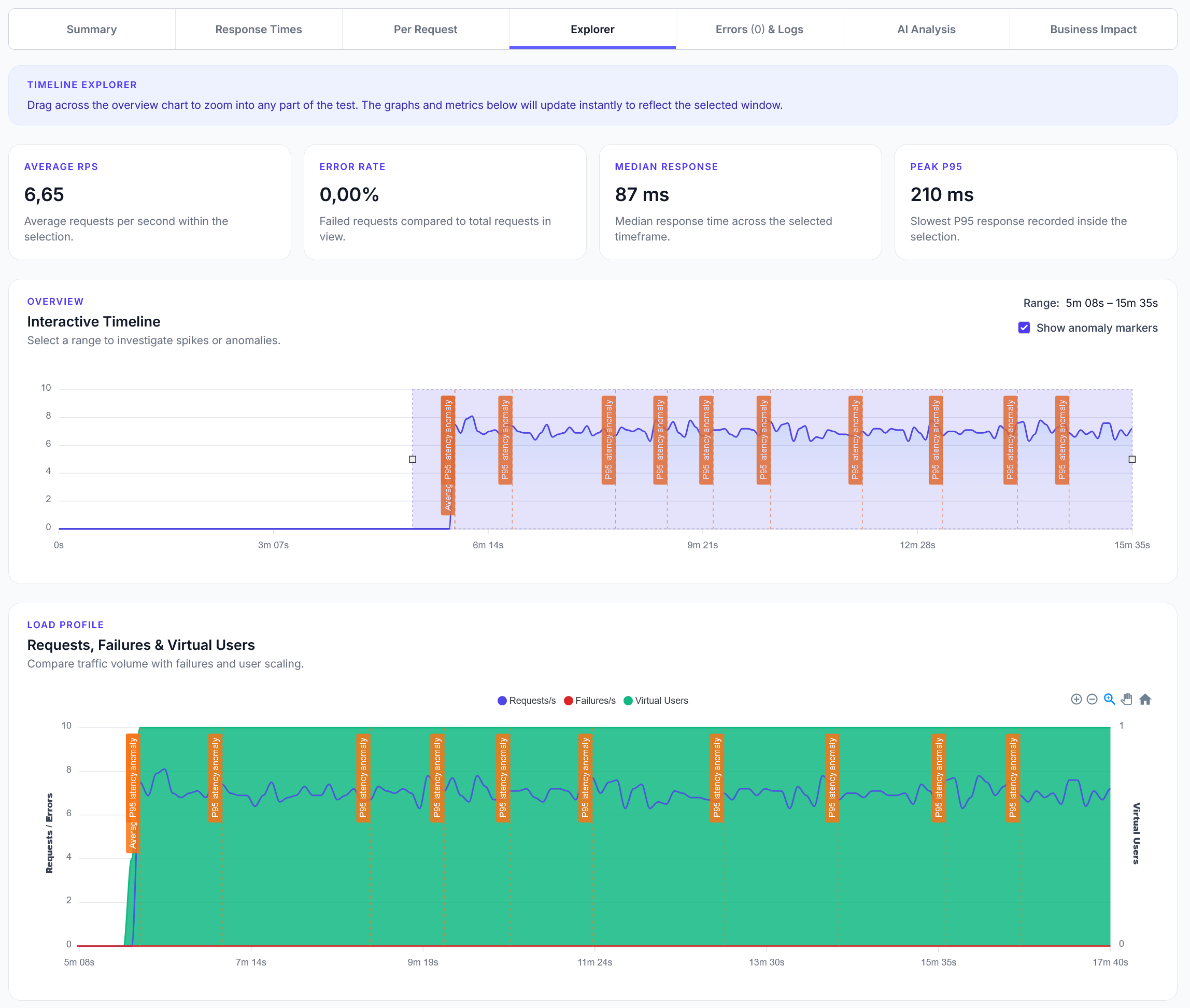
Explorer reports addition
We have added a new Explorer feature to reports, with a timeline scrubber and easy anomaly detection.
Basic SEO and meta tag validation testing for web pages and content
LoadForge can record your browser, graphically build tests, scan your site with a wizard and more. Sign up now to run your first test.
This guide shows how to test basic SEO elements like page titles, meta descriptions, and essential SEO tags. Perfect for validating SEO implementation.
from locust import task, HttpUser
import re
import random
class SEOTestUser(HttpUser):
def on_start(self):
# Pages to test for SEO
self.test_pages = [
"/",
"/about",
"/products",
"/contact",
"/blog"
]
@task(4)
def test_page_titles(self):
"""Test that pages have proper titles"""
page = random.choice(self.test_pages)
with self.client.get(page, name="SEO Title Test") as response:
if response.status_code == 200:
html = response.text
# Check for title tag
title_match = re.search(r'<title[^>]*>(.*?)</title>', html, re.IGNORECASE | re.DOTALL)
if title_match:
title = title_match.group(1).strip()
title_length = len(title)
print(f"Page {page}: Title '{title}' ({title_length} chars)")
# Check title length (SEO best practice: 50-60 chars)
if title_length == 0:
response.failure(f"Empty title on {page}")
elif title_length > 60:
print(f"WARNING: Title too long on {page} ({title_length} chars)")
elif title_length < 30:
print(f"WARNING: Title too short on {page} ({title_length} chars)")
else:
print(f"Title length OK on {page}")
else:
print(f"ERROR: No title tag found on {page}")
response.failure(f"Missing title tag on {page}")
else:
response.failure(f"Page {page} failed to load: {response.status_code}")
@task(3)
def test_meta_descriptions(self):
"""Test that pages have meta descriptions"""
page = random.choice(self.test_pages)
with self.client.get(page, name="SEO Meta Description Test") as response:
if response.status_code == 200:
html = response.text
# Check for meta description
desc_pattern = r'<meta[^>]*name=["\']description["\'][^>]*content=["\']([^"\']*)["\'][^>]*>'
desc_match = re.search(desc_pattern, html, re.IGNORECASE)
if desc_match:
description = desc_match.group(1).strip()
desc_length = len(description)
print(f"Page {page}: Meta description ({desc_length} chars)")
# Check description length (SEO best practice: 150-160 chars)
if desc_length == 0:
response.failure(f"Empty meta description on {page}")
elif desc_length > 160:
print(f"WARNING: Meta description too long on {page} ({desc_length} chars)")
elif desc_length < 120:
print(f"WARNING: Meta description too short on {page} ({desc_length} chars)")
else:
print(f"Meta description length OK on {page}")
else:
print(f"ERROR: No meta description found on {page}")
response.failure(f"Missing meta description on {page}")
else:
response.failure(f"Page {page} failed to load: {response.status_code}")
@task(2)
def test_heading_structure(self):
"""Test page heading structure (H1, H2, etc.)"""
page = random.choice(self.test_pages)
with self.client.get(page, name="SEO Heading Test") as response:
if response.status_code == 200:
html = response.text
# Check for H1 tags
h1_matches = re.findall(r'<h1[^>]*>(.*?)</h1>', html, re.IGNORECASE | re.DOTALL)
h1_count = len(h1_matches)
print(f"Page {page}: Found {h1_count} H1 tags")
if h1_count == 0:
print(f"WARNING: No H1 tag found on {page}")
elif h1_count > 1:
print(f"WARNING: Multiple H1 tags on {page} ({h1_count})")
else:
h1_text = h1_matches[0].strip()
print(f"H1 on {page}: '{h1_text}'")
# Check for H2 tags
h2_matches = re.findall(r'<h2[^>]*>', html, re.IGNORECASE)
h2_count = len(h2_matches)
print(f"Page {page}: Found {h2_count} H2 tags")
else:
response.failure(f"Page {page} failed to load: {response.status_code}")
@task(2)
def test_meta_viewport(self):
"""Test for mobile viewport meta tag"""
page = random.choice(self.test_pages)
with self.client.get(page, name="SEO Viewport Test") as response:
if response.status_code == 200:
html = response.text
# Check for viewport meta tag
viewport_pattern = r'<meta[^>]*name=["\']viewport["\'][^>]*>'
viewport_match = re.search(viewport_pattern, html, re.IGNORECASE)
if viewport_match:
print(f"Page {page}: Viewport meta tag found")
# Check if it includes width=device-width
if 'width=device-width' in viewport_match.group(0).lower():
print(f"Viewport includes device-width on {page}")
else:
print(f"WARNING: Viewport missing device-width on {page}")
else:
print(f"WARNING: No viewport meta tag on {page}")
response.failure(f"Missing viewport meta tag on {page}")
else:
response.failure(f"Page {page} failed to load: {response.status_code}")
@task(1)
def test_canonical_urls(self):
"""Test for canonical URL tags"""
page = random.choice(self.test_pages)
with self.client.get(page, name="SEO Canonical Test") as response:
if response.status_code == 200:
html = response.text
# Check for canonical link
canonical_pattern = r'<link[^>]*rel=["\']canonical["\'][^>]*href=["\']([^"\']*)["\'][^>]*>'
canonical_match = re.search(canonical_pattern, html, re.IGNORECASE)
if canonical_match:
canonical_url = canonical_match.group(1)
print(f"Page {page}: Canonical URL found - {canonical_url}")
else:
print(f"INFO: No canonical URL on {page} (may be optional)")
else:
response.failure(f"Page {page} failed to load: {response.status_code}")
@task(1)
def test_open_graph_tags(self):
"""Test for basic Open Graph tags"""
page = random.choice(self.test_pages)
with self.client.get(page, name="SEO Open Graph Test") as response:
if response.status_code == 200:
html = response.text
# Check for og:title
og_title_pattern = r'<meta[^>]*property=["\']og:title["\'][^>]*content=["\']([^"\']*)["\'][^>]*>'
og_title_match = re.search(og_title_pattern, html, re.IGNORECASE)
# Check for og:description
og_desc_pattern = r'<meta[^>]*property=["\']og:description["\'][^>]*content=["\']([^"\']*)["\'][^>]*>'
og_desc_match = re.search(og_desc_pattern, html, re.IGNORECASE)
og_tags_found = 0
if og_title_match:
og_tags_found += 1
print(f"Page {page}: og:title found")
if og_desc_match:
og_tags_found += 1
print(f"Page {page}: og:description found")
if og_tags_found == 0:
print(f"INFO: No Open Graph tags on {page}")
else:
print(f"Page {page}: {og_tags_found} Open Graph tags found")
else:
response.failure(f"Page {page} failed to load: {response.status_code}")
@task(1)
def test_robots_meta(self):
"""Test for robots meta tags"""
page = random.choice(self.test_pages)
with self.client.get(page, name="SEO Robots Test") as response:
if response.status_code == 200:
html = response.text
# Check for robots meta tag
robots_pattern = r'<meta[^>]*name=["\']robots["\'][^>]*content=["\']([^"\']*)["\'][^>]*>'
robots_match = re.search(robots_pattern, html, re.IGNORECASE)
if robots_match:
robots_content = robots_match.group(1).lower()
print(f"Page {page}: Robots directive - {robots_content}")
# Check for noindex (might be intentional)
if 'noindex' in robots_content:
print(f"WARNING: Page {page} has noindex directive")
else:
print(f"INFO: No robots meta tag on {page} (using defaults)")
else:
response.failure(f"Page {page} failed to load: {response.status_code}")
@task(1)
def test_page_load_speed(self):
"""Test page load speed (basic SEO factor)"""
page = random.choice(self.test_pages)
import time
start_time = time.time()
with self.client.get(page, name="SEO Speed Test") as response:
load_time = time.time() - start_time
if response.status_code == 200:
print(f"Page {page}: Load time {load_time:.2f}s")
# Basic speed thresholds
if load_time > 3.0:
print(f"WARNING: Slow page load on {page} ({load_time:.2f}s)")
elif load_time > 1.5:
print(f"MODERATE: Page load time on {page} ({load_time:.2f}s)")
else:
print(f"GOOD: Fast page load on {page} ({load_time:.2f}s)")
else:
response.failure(f"Page {page} failed to load: {response.status_code}")
test_pages list with your actual website pages