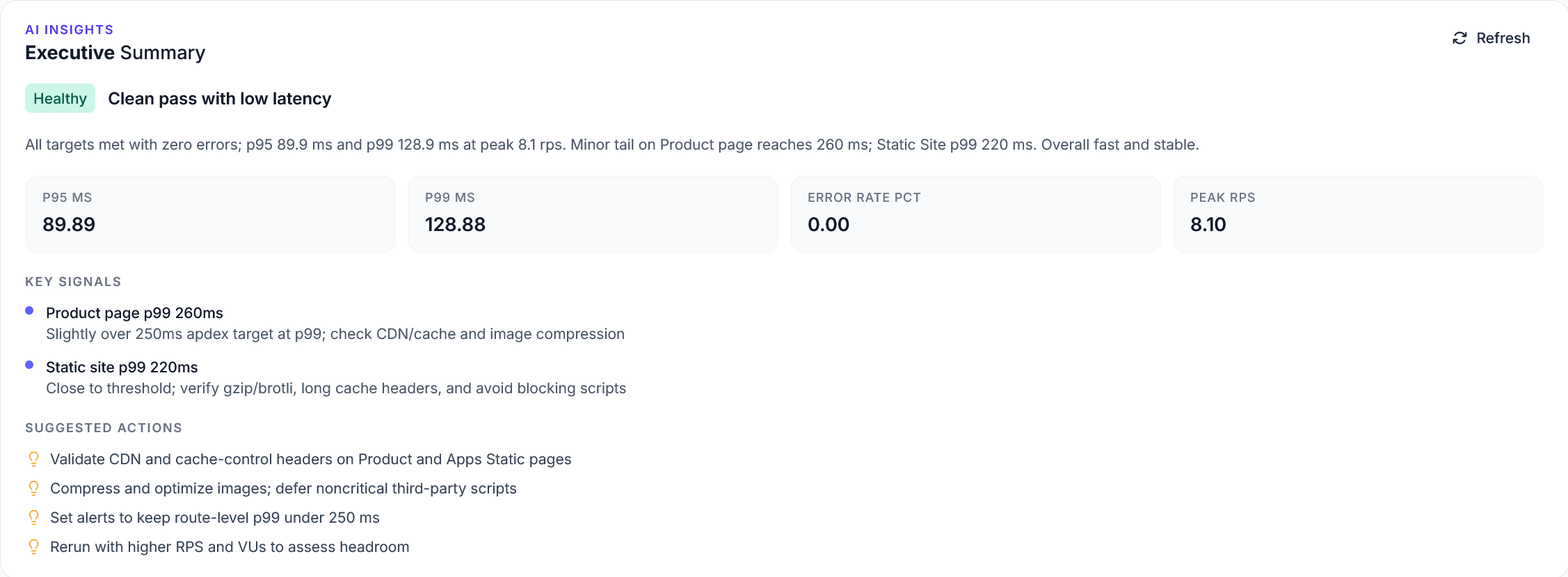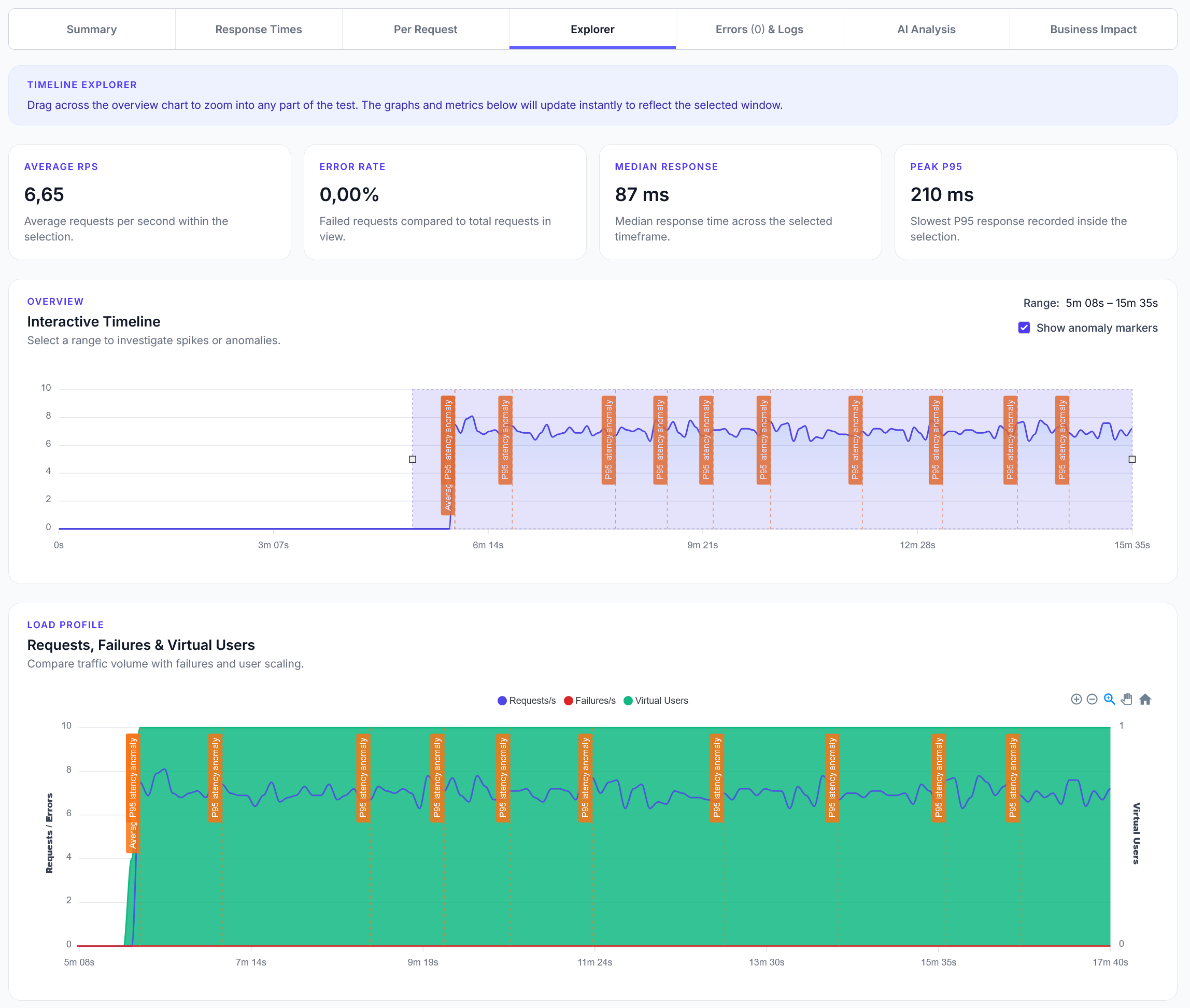
Explorer reports addition
We have added a new Explorer feature to reports, with a timeline scrubber and easy anomaly detection.
Check WCAG compliance and accessibility issues across your website
LoadForge can record your browser, graphically build tests, scan your site with a wizard and more. Sign up now to run your first test.
This guide demonstrates how to test website accessibility with LoadForge, checking for WCAG compliance issues and common accessibility problems.
from locust import HttpUser, task, between
import re
import time
class SimpleAccessibilityChecker(HttpUser):
wait_time = between(1, 2)
def on_start(self):
"""Initialize simple accessibility checking"""
self.accessibility_issues = []
self.pages_checked = 0
self.discovered_pages = []
self.current_page_issues = []
print("Starting simple accessibility check...")
@task(5)
def discover_and_check_accessibility(self):
"""Discover pages and check accessibility continuously"""
if self.pages_checked == 0:
# Start with homepage
self._check_page_accessibility('/')
elif len(self.discovered_pages) > 0:
# Keep cycling through discovered pages for continuous testing
self._cycle_through_pages()
def _check_page_accessibility(self, page_url):
"""Check accessibility on a single page"""
self.current_page_issues = [] # Reset issues for this page
with self.client.get(page_url, name=f"ACCESSIBILITY: {page_url}", catch_response=True) as response:
if response.status_code == 200:
self._check_basic_accessibility(page_url, response.text)
# Only increment pages_checked during initial discovery phase
if page_url == '/' and self.pages_checked == 0:
self.pages_checked += 1
self._find_internal_pages(response.text)
elif page_url in self.discovered_pages and self.pages_checked == 1:
# We're in the continuous testing phase, don't increment counter
pass
else:
# Still in discovery mode
self.pages_checked += 1
# Report page result based on issues found
if self.current_page_issues:
high_issues = [i for i in self.current_page_issues if i['severity'] == 'HIGH']
medium_issues = [i for i in self.current_page_issues if i['severity'] == 'MEDIUM']
failure_msg = f"❌ {len(self.current_page_issues)} accessibility issues ({len(high_issues)} high, {len(medium_issues)} medium)"
response.failure(failure_msg)
else:
response.success()
else:
response.failure(f"Could not access page: HTTP {response.status_code}")
def _find_internal_pages(self, html_content):
"""Find internal pages from homepage links"""
# Find internal links
links = re.findall(r'<a[^>]+href=["\']([^"\']+)["\']', html_content, re.IGNORECASE)
for link in links:
if self._is_internal_page_link(link):
normalized_link = self._normalize_link(link)
if normalized_link and normalized_link not in self.discovered_pages and normalized_link != '/':
self.discovered_pages.append(normalized_link)
if len(self.discovered_pages) >= 100: # Discover up to 100 pages
break
print(f"Discovered {len(self.discovered_pages)} internal pages to check")
def _cycle_through_pages(self):
"""Continuously cycle through discovered pages for accessibility testing"""
if not self.discovered_pages:
return
# Pick a random page from discovered pages to check
import random
page_to_check = random.choice(self.discovered_pages)
# Check accessibility on this page (this creates continuous load testing)
self._check_page_accessibility(page_to_check)
def _is_internal_page_link(self, link):
"""Check if link is an internal page (not resource)"""
# Skip anchors, external protocols, and resources
if any(skip in link.lower() for skip in ['#', 'mailto:', 'tel:', 'javascript:']):
return False
# Skip common resource extensions
resource_extensions = ['.css', '.js', '.jpg', '.jpeg', '.png', '.gif', '.pdf', '.zip']
if any(link.lower().endswith(ext) for ext in resource_extensions):
return False
# Must be internal (relative or same domain)
if link.startswith('/') or not link.startswith('http'):
return True
return False
def _normalize_link(self, link):
"""Normalize link for checking"""
try:
if link.startswith('/'):
return link.split('#')[0] # Remove fragment
elif not link.startswith('http'):
return '/' + link.lstrip('./')
return None
except:
return None
def _check_basic_accessibility(self, page_url, html_content):
"""Check basic accessibility issues on a page"""
print(f"Checking accessibility for: {page_url}")
# Check images for alt text
self._check_image_alt_text(page_url, html_content)
# Check form labels
self._check_form_labels(page_url, html_content)
# Check heading structure
self._check_heading_structure(page_url, html_content)
# Check link text
self._check_link_text(page_url, html_content)
def _check_image_alt_text(self, page_url, html_content):
"""Check images for alt text"""
img_tags = re.findall(r'<img[^>]*>', html_content, re.IGNORECASE)
for img_tag in img_tags:
if 'alt=' not in img_tag.lower():
self._log_issue(page_url, 'HIGH', 'Image missing alt attribute', img_tag[:80])
else:
# Check for generic alt text
alt_match = re.search(r'alt=["\']([^"\']*)["\']', img_tag, re.IGNORECASE)
if alt_match:
alt_text = alt_match.group(1).strip()
if alt_text.lower() in ['image', 'picture', 'photo', 'img']:
self._log_issue(page_url, 'MEDIUM', f'Generic alt text: "{alt_text}"', img_tag[:80])
def _check_form_labels(self, page_url, html_content):
"""Check form elements for labels"""
form_elements = re.findall(r'<(input|textarea|select)[^>]*>', html_content, re.IGNORECASE)
for element in form_elements:
# Skip hidden inputs and buttons
if 'type="hidden"' in element.lower() or 'type="submit"' in element.lower():
continue
# Check for id and corresponding label
id_match = re.search(r'id=["\']([^"\']*)["\']', element, re.IGNORECASE)
if id_match:
element_id = id_match.group(1)
label_pattern = f'<label[^>]*for=["\']?{re.escape(element_id)}["\']?[^>]*>'
if not re.search(label_pattern, html_content, re.IGNORECASE):
# Check for aria-label as alternative
if 'aria-label=' not in element.lower():
self._log_issue(page_url, 'HIGH', f'Form element missing label: {element_id}', element[:80])
def _check_heading_structure(self, page_url, html_content):
"""Check heading structure"""
headings = re.findall(r'<(h[1-6])[^>]*>(.*?)</\1>', html_content, re.IGNORECASE | re.DOTALL)
if not headings:
self._log_issue(page_url, 'HIGH', 'Page has no headings', '')
return
# Check if page starts with h1
heading_levels = [int(h[0][1]) for h in headings]
if heading_levels[0] != 1:
self._log_issue(page_url, 'MEDIUM', f'Page does not start with h1 (starts with h{heading_levels[0]})', '')
# Check for empty headings
for heading_tag, heading_text in headings:
clean_text = re.sub(r'<[^>]+>', '', heading_text).strip()
if not clean_text:
self._log_issue(page_url, 'HIGH', f'Empty {heading_tag.upper()} heading', '')
def _check_link_text(self, page_url, html_content):
"""Check link text for accessibility"""
links = re.finditer(r'<a[^>]*>(.*?)</a>', html_content, re.IGNORECASE | re.DOTALL)
for link_match in links:
link_text = link_match.group(1).strip()
clean_link_text = re.sub(r'<[^>]+>', '', link_text).strip()
# Check for empty link text
if not clean_link_text:
self._log_issue(page_url, 'HIGH', 'Link has no text', link_match.group(0)[:80])
elif clean_link_text.lower() in ['click here', 'read more', 'more', 'here', 'link']:
self._log_issue(page_url, 'MEDIUM', f'Generic link text: "{clean_link_text}"', link_match.group(0)[:80])
def _log_issue(self, page_url, severity, description, element):
"""Log accessibility issue"""
issue = {
'page': page_url,
'severity': severity,
'description': description,
'element': element,
'timestamp': time.time()
}
self.accessibility_issues.append(issue)
self.current_page_issues.append(issue) # Track issues for current page
print(f"ACCESSIBILITY ISSUE [{severity}]: {description} on {page_url}")
@task(1)
def report_accessibility_status(self):
"""Report current accessibility status"""
if len(self.discovered_pages) == 0:
return
high_issues = [issue for issue in self.accessibility_issues if issue['severity'] == 'HIGH']
medium_issues = [issue for issue in self.accessibility_issues if issue['severity'] == 'MEDIUM']
total_pages_in_scope = len(self.discovered_pages) + 1 # +1 for homepage
print(f"ACCESSIBILITY LOAD TEST: {len(self.accessibility_issues)} total issues "
f"({len(high_issues)} high, {len(medium_issues)} medium) "
f"found across {total_pages_in_scope} pages (continuously testing)")
def on_stop(self):
"""Final accessibility report"""
print("\n" + "="*50)
print("ACCESSIBILITY LOAD TEST COMPLETE")
print("="*50)
total_pages_in_scope = len(self.discovered_pages) + 1 # +1 for homepage
print(f"Pages in test scope: {total_pages_in_scope}")
print(f"Total accessibility issues found: {len(self.accessibility_issues)}")
if self.accessibility_issues:
print(f"\nTOP ACCESSIBILITY ISSUES:")
for issue in self.accessibility_issues[:5]:
print(f"❌ [{issue['severity']}] {issue['description']}")
print(f" Page: {issue['page']}")
else:
print("✅ No accessibility issues found!")
from locust import HttpUser, task, between
import json
import time
import re
from urllib.parse import urlparse
from collections import defaultdict, deque
class ComprehensiveAccessibilityTester(HttpUser):
wait_time = between(1, 3)
def on_start(self):
"""Initialize comprehensive accessibility testing"""
self.visited_pages = set()
self.pages_to_check = deque(['/'])
self.accessibility_issues = []
self.accessibility_stats = defaultdict(int)
self.wcag_violations = []
self.base_domain = None
# Initialize crawler
self._initialize_crawler()
def _initialize_crawler(self):
"""Initialize the accessibility crawler"""
response = self.client.get('/', name="INIT: Homepage accessibility check")
if response.status_code == 200:
self.base_domain = urlparse(self.client.base_url).netloc
print(f"Starting comprehensive accessibility testing for: {self.base_domain}")
else:
print(f"Failed to access homepage: {response.status_code}")
@task(5)
def crawl_and_test_accessibility(self):
"""Main crawling task to test accessibility"""
if not self.pages_to_check:
return
current_page = self.pages_to_check.popleft()
if current_page in self.visited_pages:
return
self.visited_pages.add(current_page)
response = self.client.get(current_page, name=f"CRAWL: {current_page}")
if response.status_code == 200:
self._test_page_accessibility(current_page, response.text)
self._find_more_pages(response.text)
else:
print(f"Cannot access page for accessibility testing: {current_page}")
def _test_page_accessibility(self, page_url, html_content):
"""Test comprehensive accessibility on a page"""
self.accessibility_stats['total_pages'] += 1
# Run all accessibility tests
self._test_images(page_url, html_content)
self._test_forms(page_url, html_content)
self._test_headings(page_url, html_content)
self._test_links(page_url, html_content)
self._test_aria(page_url, html_content)
self._test_semantic_html(page_url, html_content)
def _test_images(self, page_url, html_content):
"""Test image accessibility"""
img_tags = re.findall(r'<img[^>]*>', html_content, re.IGNORECASE)
for img_tag in img_tags:
self.accessibility_stats['total_images'] += 1
if 'alt=' not in img_tag.lower():
self._record_issue(page_url, 'HIGH', 'Image missing alt attribute', 'WCAG 1.1.1', img_tag[:100])
else:
alt_match = re.search(r'alt=["\']([^"\']*)["\']', img_tag, re.IGNORECASE)
if alt_match:
alt_text = alt_match.group(1).strip()
if not alt_text and 'role="presentation"' not in img_tag.lower():
self._record_issue(page_url, 'MEDIUM', 'Image has empty alt text', 'WCAG 1.1.1', img_tag[:100])
elif alt_text.lower() in ['image', 'picture', 'photo', 'img']:
self._record_issue(page_url, 'MEDIUM', f'Generic alt text: "{alt_text}"', 'WCAG 1.1.1', img_tag[:100])
def _test_forms(self, page_url, html_content):
"""Test form accessibility"""
form_elements = re.findall(r'<(input|textarea|select)[^>]*>', html_content, re.IGNORECASE)
for element in form_elements:
self.accessibility_stats['total_form_elements'] += 1
# Skip certain input types
if any(t in element.lower() for t in ['type="hidden"', 'type="submit"', 'type="button"']):
continue
id_match = re.search(r'id=["\']([^"\']*)["\']', element, re.IGNORECASE)
if id_match:
element_id = id_match.group(1)
label_pattern = f'<label[^>]*for=["\']?{re.escape(element_id)}["\']?[^>]*>'
if not re.search(label_pattern, html_content, re.IGNORECASE):
if 'aria-label=' not in element.lower() and 'aria-labelledby=' not in element.lower():
self._record_issue(page_url, 'HIGH', f'Form element missing label: {element_id}', 'WCAG 1.3.1', element[:100])
# Check required fields
if 'required' in element.lower() and 'aria-required=' not in element.lower():
self._record_issue(page_url, 'MEDIUM', 'Required field missing aria-required', 'WCAG 3.3.2', element[:100])
def _test_headings(self, page_url, html_content):
"""Test heading structure"""
headings = re.findall(r'<(h[1-6])[^>]*>(.*?)</\1>', html_content, re.IGNORECASE | re.DOTALL)
if not headings:
self._record_issue(page_url, 'HIGH', 'Page has no heading structure', 'WCAG 1.3.1', '')
return
heading_levels = [int(h[0][1]) for h in headings]
# Check if starts with h1
if heading_levels[0] != 1:
self._record_issue(page_url, 'MEDIUM', f'Page does not start with h1', 'WCAG 1.3.1', '')
# Check for heading level skips
for i in range(1, len(heading_levels)):
if heading_levels[i] > heading_levels[i-1] + 1:
self._record_issue(page_url, 'MEDIUM', f'Heading level skip: h{heading_levels[i-1]} to h{heading_levels[i]}', 'WCAG 1.3.1', '')
# Check for empty headings
for heading_tag, heading_text in headings:
clean_text = re.sub(r'<[^>]+>', '', heading_text).strip()
if not clean_text:
self._record_issue(page_url, 'HIGH', f'Empty {heading_tag.upper()} heading', 'WCAG 2.4.6', '')
def _test_links(self, page_url, html_content):
"""Test link accessibility"""
for link_match in re.finditer(r'<a[^>]*>(.*?)</a>', html_content, re.IGNORECASE | re.DOTALL):
link_tag = link_match.group(0)
link_text = link_match.group(1).strip()
clean_link_text = re.sub(r'<[^>]+>', '', link_text).strip()
self.accessibility_stats['total_links'] += 1
if not clean_link_text:
if 'aria-label=' not in link_tag.lower() and 'title=' not in link_tag.lower():
self._record_issue(page_url, 'HIGH', 'Link has no accessible text', 'WCAG 2.4.4', link_tag[:100])
elif clean_link_text.lower() in ['click here', 'read more', 'more', 'link', 'here']:
self._record_issue(page_url, 'MEDIUM', f'Generic link text: "{clean_link_text}"', 'WCAG 2.4.4', link_tag[:100])
def _test_aria(self, page_url, html_content):
"""Test ARIA implementation"""
# Check for main landmark
if 'role="main"' not in html_content.lower() and '<main' not in html_content.lower():
self._record_issue(page_url, 'MEDIUM', 'Page missing main landmark', 'WCAG 1.3.1', '')
# Check for invalid ARIA attributes (basic check)
aria_attributes = re.findall(r'aria-([a-zA-Z-]+)=', html_content, re.IGNORECASE)
valid_aria = ['label', 'labelledby', 'describedby', 'hidden', 'expanded', 'controls', 'live', 'required']
for attr in aria_attributes:
if attr not in valid_aria:
self._record_issue(page_url, 'LOW', f'Unknown ARIA attribute: aria-{attr}', 'WCAG 4.1.2', '')
def _test_semantic_html(self, page_url, html_content):
"""Test semantic HTML usage"""
semantic_elements = ['header', 'nav', 'main', 'article', 'section', 'aside', 'footer']
found_semantic = []
for element in semantic_elements:
if f'<{element}' in html_content.lower():
found_semantic.append(element)
if len(found_semantic) < 2:
self._record_issue(page_url, 'LOW', f'Limited semantic HTML (found: {", ".join(found_semantic)})', 'WCAG 1.3.1', '')
def _find_more_pages(self, html_content):
"""Find more internal pages to test"""
if len(self.pages_to_check) > 20: # Limit crawling
return
links = re.findall(r'<a[^>]+href=["\']([^"\']+)["\']', html_content, re.IGNORECASE)
for link in links:
if self._is_internal_link(link) and link not in self.visited_pages:
normalized_link = self._normalize_url(link)
if normalized_link:
self.pages_to_check.append(normalized_link)
def _is_internal_link(self, link):
"""Check if link is internal"""
if link.startswith('/'):
return True
if link.startswith('http'):
return urlparse(link).netloc == self.base_domain
return not link.startswith(('mailto:', 'tel:', 'javascript:', '#'))
def _normalize_url(self, link):
"""Normalize URL for consistency"""
try:
if link.startswith('/'):
return link.split('#')[0] # Remove fragments
elif link.startswith('http'):
parsed = urlparse(link)
if parsed.netloc == self.base_domain:
return parsed.path
return None
except:
return None
def _record_issue(self, page_url, severity, description, wcag_guideline, element):
"""Record accessibility issue"""
issue = {
'page': page_url,
'severity': severity,
'description': description,
'wcag_guideline': wcag_guideline,
'element': element[:200] if element else '',
'timestamp': time.time()
}
self.accessibility_issues.append(issue)
self.accessibility_stats['total_issues'] += 1
if wcag_guideline:
self.wcag_violations.append(wcag_guideline)
print(f"ACCESSIBILITY ISSUE [{severity}]: {description} ({wcag_guideline}) on {page_url}")
@task(1)
def generate_accessibility_report(self):
"""Generate accessibility report"""
if len(self.visited_pages) < 3:
return
high_issues = [i for i in self.accessibility_issues if i['severity'] == 'HIGH']
medium_issues = [i for i in self.accessibility_issues if i['severity'] == 'MEDIUM']
print(f"ACCESSIBILITY REPORT: {len(self.accessibility_issues)} total issues "
f"({len(high_issues)} high, {len(medium_issues)} medium) "
f"across {len(self.visited_pages)} pages")
def on_stop(self):
"""Final accessibility report"""
print("\n=== COMPREHENSIVE ACCESSIBILITY TEST COMPLETE ===")
print(f"Pages tested: {len(self.visited_pages)}")
print(f"Total accessibility issues: {len(self.accessibility_issues)}")
print(f"WCAG violations: {len(set(self.wcag_violations))}")
if self.accessibility_issues:
print("\nTOP ACCESSIBILITY ISSUES:")
for issue in self.accessibility_issues[:5]:
print(f" - [{issue['severity']}] {issue['description']} ({issue['wcag_guideline']})")
from locust import HttpUser, task, between
import json
import time
import re
class AdvancedWCAGTester(HttpUser):
wait_time = between(2, 4)
@task(3)
def test_wcag_aa_compliance(self):
"""Test specific WCAG AA compliance requirements"""
pages = ['/', '/about', '/contact', '/services']
for page in pages:
response = self.client.get(page, name=f"WCAG AA: {page}")
if response.status_code == 200:
self._test_color_contrast_requirements(page, response.text)
self._test_focus_management(page, response.text)
self._test_keyboard_navigation(page, response.text)
def _test_color_contrast_requirements(self, page_url, html_content):
"""Test color contrast indicators"""
# Look for potential low contrast in inline styles
styles = re.findall(r'style=["\']([^"\']*)["\']', html_content, re.IGNORECASE)
for style in styles:
if 'color:' in style.lower() and 'background' in style.lower():
# Basic check for obvious low contrast patterns
if '#fff' in style.lower() and any(c in style.lower() for c in ['#f', '#e']):
print(f"POTENTIAL LOW CONTRAST: {style[:50]} on {page_url}")
def _test_focus_management(self, page_url, html_content):
"""Test focus management elements"""
# Check for skip links
if not re.search(r'<a[^>]*href=["\']#[^"\']*["\'][^>]*>.*?skip.*?</a>', html_content, re.IGNORECASE):
print(f"MISSING SKIP LINK: {page_url}")
# Check for positive tabindex (anti-pattern)
positive_tabindex = re.findall(r'tabindex=["\']([1-9][0-9]*)["\']', html_content)
if positive_tabindex:
print(f"POSITIVE TABINDEX FOUND: {positive_tabindex} on {page_url}")
def _test_keyboard_navigation(self, page_url, html_content):
"""Test keyboard navigation support"""
# Check interactive elements for keyboard support
interactive_elements = re.findall(r'<(button|a|input|select|textarea)[^>]*>', html_content, re.IGNORECASE)
for element in interactive_elements:
if 'onclick=' in element.lower() and element.lower().startswith('<div'):
print(f"NON-SEMANTIC INTERACTIVE ELEMENT: {element[:50]} on {page_url}")
@task(1)
def validate_html_semantics(self):
"""Validate HTML semantic structure"""
response = self.client.get('/', name="HTML Semantics Validation")
if response.status_code == 200:
# Check document structure
html = response.text.lower()
required_elements = ['<title', '<main', '<h1']
for element in required_elements:
if element not in html:
print(f"MISSING REQUIRED ELEMENT: {element}")
# Check for proper landmark structure
landmarks = ['header', 'nav', 'main', 'footer']
found_landmarks = [l for l in landmarks if f'<{l}' in html]
if len(found_landmarks) < 3:
print(f"INSUFFICIENT LANDMARKS: Only found {found_landmarks}")
This guide provides three levels of accessibility testing to match different user needs and expertise levels.