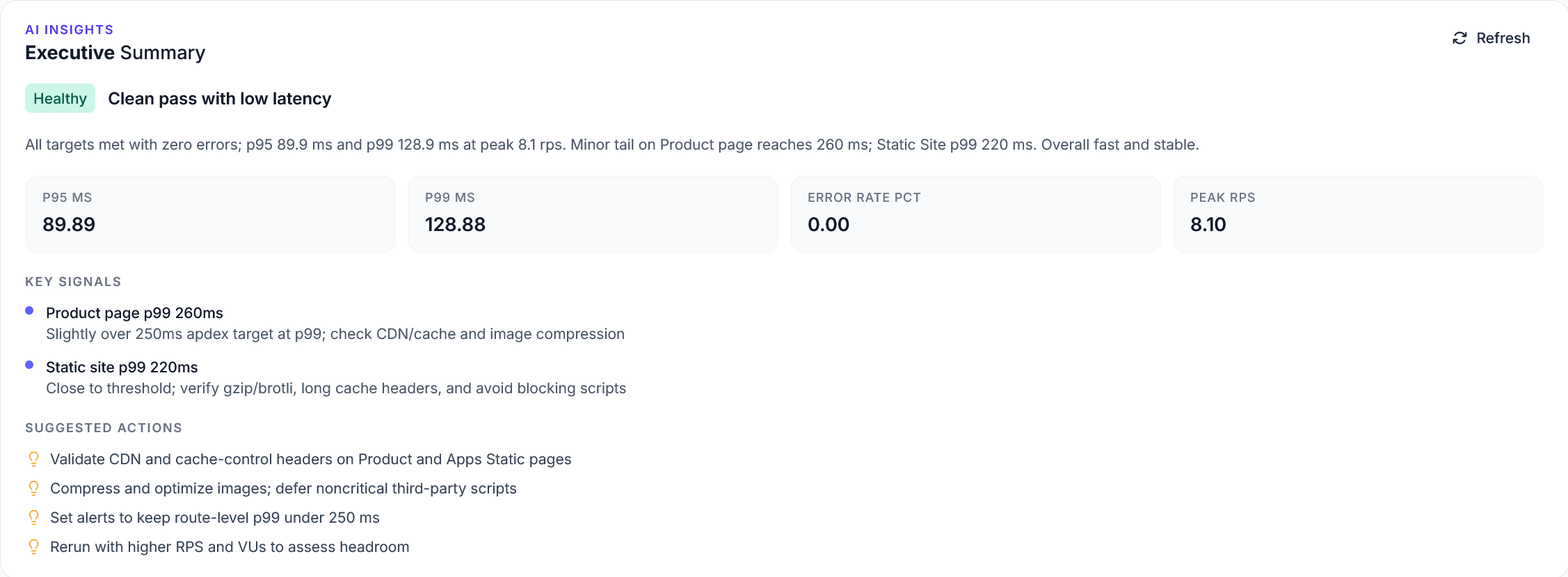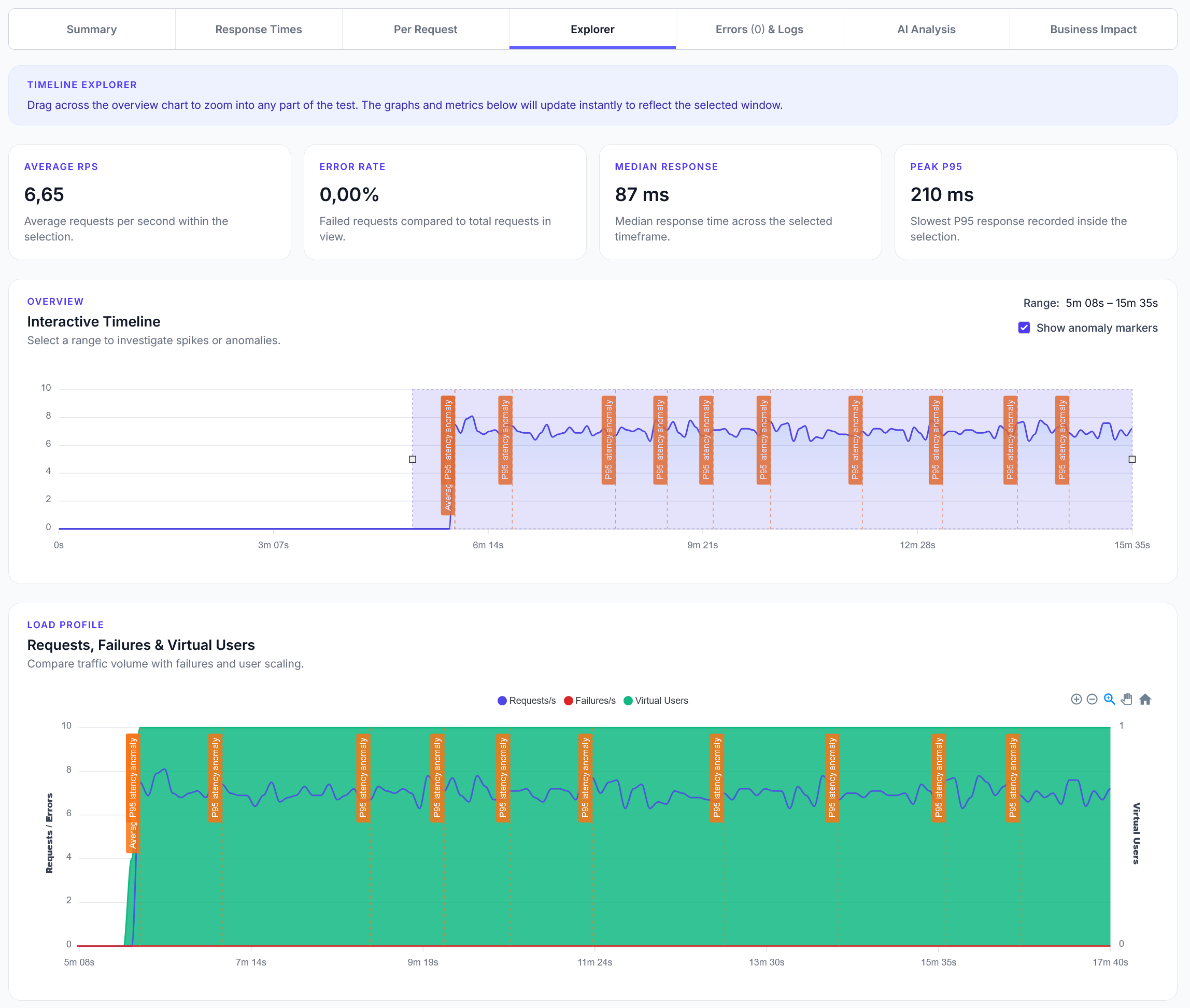
Explorer reports addition
We have added a new Explorer feature to reports, with a timeline scrubber and easy anomaly detection.
Load testing DigitalOcean's AI platform with Llama3 models to measure response times and reliability
LoadForge can record your browser, graphically build tests, scan your site with a wizard and more. Sign up now to run your first test.
This guide shows how to performance test DigitalOcean's AI platform using Locust. Perfect for testing response times, reliability, and capacity planning for AI workloads on DigitalOcean.
import random
from locust import HttpUser, task, between
class Llama3ChatUser(HttpUser):
wait_time = between(1, 5)
QUESTIONS = [
"What is the capital of France?",
"Translate 'Hello, how are you?' into Spanish.",
"Who wrote 'Pride and Prejudice'?",
"What's 13 multiplied by 17?",
"Name three benefits of a vegan diet.",
"Give me a quick summary of the plot of '1984'.",
"Explain the concept of machine learning in simple terms.",
"What are the main differences between Python and JavaScript?",
"How does photosynthesis work?",
"What are some tips for effective time management?"
]
@task
def chat_completion(self):
question = random.choice(self.QUESTIONS)
# Used to show a preview of the question in LF
preview = (question[:20] + "...") if len(question) > 20 else question
payload = {
"model": "llama3.3-70b-instruct",
"messages": [{"role": "user", "content": question}],
"stream": False,
"include_functions_info": False,
"include_retrieval_info": False,
"include_guardrails_info": False
}
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {self.api_token}"
}
with self.client.post(
"/api/v1/chat/completions",
json=payload,
headers=headers,
name=f"chat: {preview}",
catch_response=True
) as response:
if response.status_code == 200:
response.success()
else:
response.failure(f"Status {response.status_code}")
def on_start(self):
# Set your DigitalOcean AI API token here
self.api_token = "your-digitalocean-ai-token"
Get DigitalOcean AI Access:
Configure the Script in LoadForge:
your-digitalocean-ai-token with your actual API tokenConfigure Load Test Settings:
Typical results for Llama 3.3 70B on DigitalOcean AI: