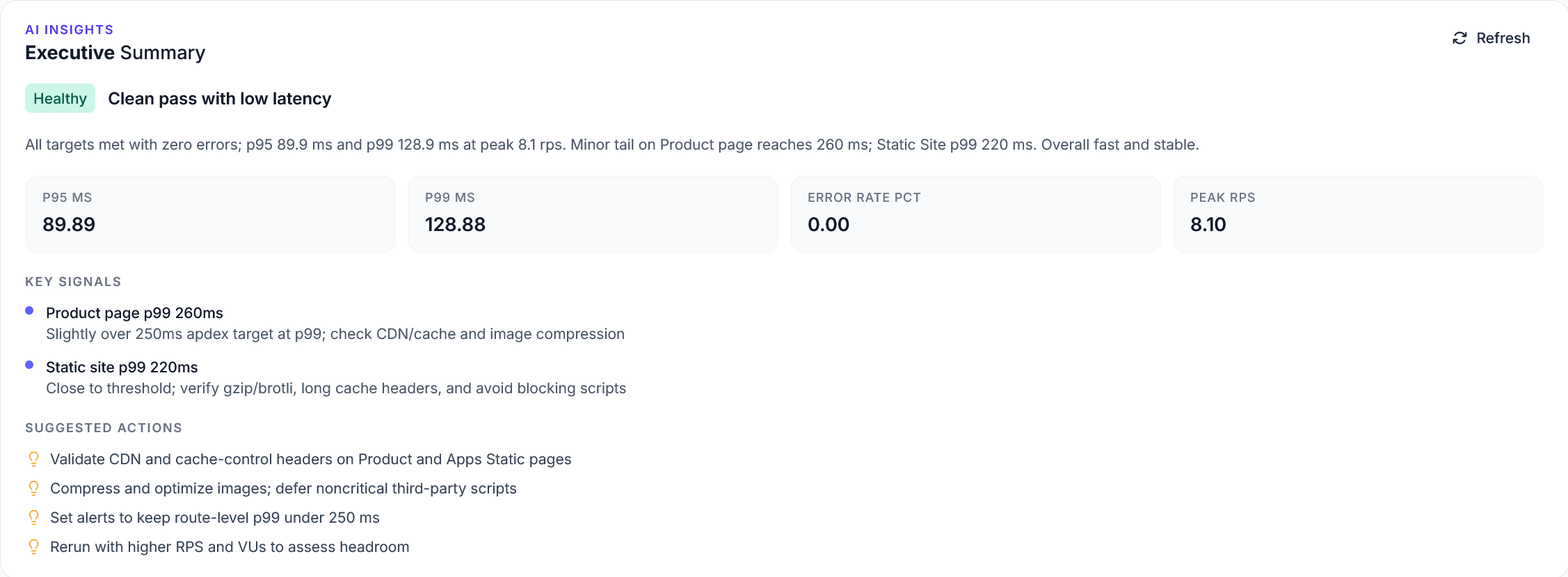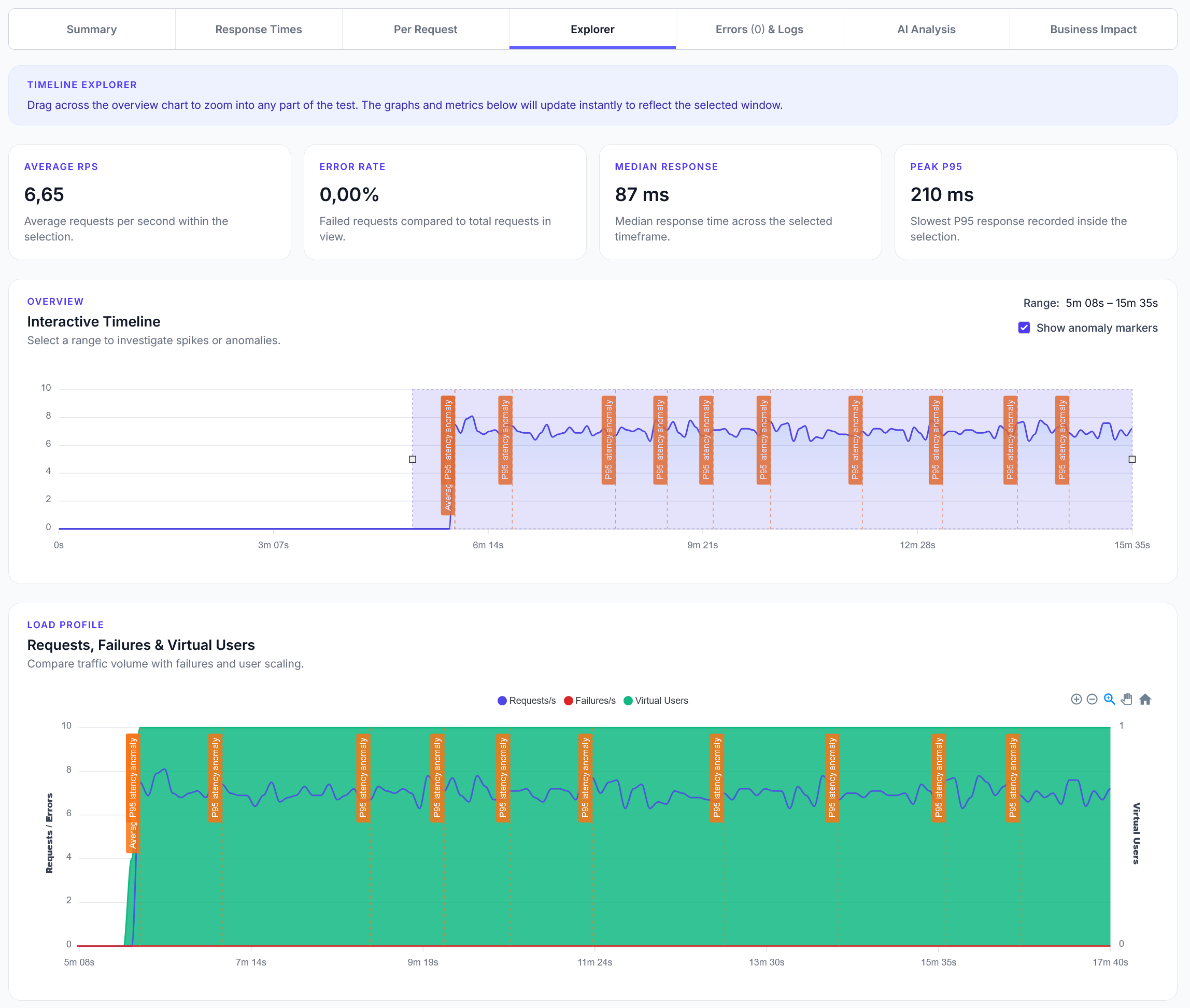
Explorer reports addition
We have added a new Explorer feature to reports, with a timeline scrubber and easy anomaly detection.
Crawl your entire website and validate security headers implementation across all pages
LoadForge can record your browser, graphically build tests, scan your site with a wizard and more. Sign up now to run your first test.
This guide demonstrates how to crawl your entire website and validate security headers implementation across all discovered pages, ensuring consistent security controls throughout your site.
from locust import HttpUser, task, between
import re
import time
from urllib.parse import urlparse
from collections import deque
# CONFIGURATION - Edit these settings for your requirements
REQUIRED_HEADERS = {
'Strict-Transport-Security': True, # HSTS - highly recommended
'X-Frame-Options': True, # Clickjacking protection
'X-Content-Type-Options': True, # MIME type sniffing protection
'Referrer-Policy': True, # Referrer information control
'Content-Security-Policy': False, # CSP - optional by default (can be complex)
'X-XSS-Protection': False, # Deprecated but still useful
}
# Optional: Validate specific header values
HEADER_VALUES = {
'X-Content-Type-Options': ['nosniff'],
'X-Frame-Options': ['DENY', 'SAMEORIGIN'],
'Referrer-Policy': ['strict-origin-when-cross-origin', 'same-origin', 'no-referrer', 'strict-origin']
}
class SecurityHeadersCrawler(HttpUser):
wait_time = between(1, 2)
def on_start(self):
"""Initialize security headers crawling"""
self.visited_pages = set()
self.pages_to_check = deque(['/'])
self.security_issues = []
self.pages_checked = 0
self.base_domain = None
print("Starting security headers validation...")
print(f"Required headers: {[h for h, required in REQUIRED_HEADERS.items() if required]}")
@task(5)
def crawl_and_validate_headers(self):
"""Main crawling task to validate security headers"""
if not self.pages_to_check:
return
current_page = self.pages_to_check.popleft()
if current_page in self.visited_pages:
return
self.visited_pages.add(current_page)
self.pages_checked += 1
with self.client.get(current_page, name=f"SECURITY: {current_page}", catch_response=True) as response:
if response.status_code == 200:
# Set base domain on first successful request
if not self.base_domain:
self.base_domain = urlparse(self.client.base_url).netloc
# Validate security headers
missing_headers, invalid_headers = self._validate_security_headers(current_page, response.headers)
# Find more pages to crawl
self._find_internal_pages(response.text)
# Report results
if missing_headers or invalid_headers:
issues = missing_headers + invalid_headers
failure_msg = f"❌ Security issues: {', '.join(issues)}"
response.failure(failure_msg)
else:
response.success()
else:
response.failure(f"Could not access page: HTTP {response.status_code}")
def _validate_security_headers(self, page_url, headers):
"""Validate security headers for a page"""
missing_headers = []
invalid_headers = []
for header_name, is_required in REQUIRED_HEADERS.items():
if is_required:
if header_name not in headers:
missing_headers.append(f"Missing {header_name}")
self._log_security_issue(page_url, 'HIGH', f'Missing required header: {header_name}')
else:
# Check header value if validation rules exist
if header_name in HEADER_VALUES:
header_value = headers[header_name]
valid_values = HEADER_VALUES[header_name]
# For some headers, check if value contains any of the valid options
if header_name == 'Referrer-Policy':
if not any(valid_val in header_value for valid_val in valid_values):
invalid_headers.append(f"Invalid {header_name}")
self._log_security_issue(page_url, 'MEDIUM', f'Invalid {header_name}: {header_value}')
else:
if header_value not in valid_values:
invalid_headers.append(f"Invalid {header_name}")
self._log_security_issue(page_url, 'MEDIUM', f'Invalid {header_name}: {header_value}')
elif header_name in headers:
# Optional header is present - validate it
if header_name in HEADER_VALUES:
header_value = headers[header_name]
valid_values = HEADER_VALUES[header_name]
if header_name == 'Referrer-Policy':
if not any(valid_val in header_value for valid_val in valid_values):
invalid_headers.append(f"Invalid {header_name}")
self._log_security_issue(page_url, 'MEDIUM', f'Invalid optional {header_name}: {header_value}')
else:
if header_value not in valid_values:
invalid_headers.append(f"Invalid {header_name}")
self._log_security_issue(page_url, 'MEDIUM', f'Invalid optional {header_name}: {header_value}')
return missing_headers, invalid_headers
def _find_internal_pages(self, html_content):
"""Find internal pages from current page links"""
if len(self.pages_to_check) > 50: # Limit crawling depth
return
# Find internal links
links = re.findall(r'<a[^>]+href=["\']([^"\']+)["\']', html_content, re.IGNORECASE)
for link in links:
if self._is_internal_page_link(link):
normalized_link = self._normalize_link(link)
if normalized_link and normalized_link not in self.visited_pages:
if normalized_link not in self.pages_to_check:
self.pages_to_check.append(normalized_link)
def _is_internal_page_link(self, link):
"""Check if link is an internal page (not resource)"""
# Skip anchors, external protocols, and resources
if any(skip in link.lower() for skip in ['#', 'mailto:', 'tel:', 'javascript:']):
return False
# Skip common resource extensions
resource_extensions = ['.css', '.js', '.jpg', '.jpeg', '.png', '.gif', '.pdf', '.zip',
'.svg', '.ico', '.mp4', '.mp3', '.woff', '.woff2', '.ttf', '.eot']
if any(link.lower().endswith(ext) for ext in resource_extensions):
return False
# Must be internal (relative or same domain)
if link.startswith('/') or not link.startswith('http'):
return True
if link.startswith('http') and self.base_domain:
return urlparse(link).netloc == self.base_domain
return False
def _normalize_link(self, link):
"""Normalize link for checking"""
try:
if link.startswith('/'):
return link.split('#')[0] # Remove fragment
elif not link.startswith('http'):
return '/' + link.lstrip('./')
elif self.base_domain and link.startswith('http'):
parsed = urlparse(link)
if parsed.netloc == self.base_domain:
return parsed.path
return None
except:
return None
def _log_security_issue(self, page_url, severity, description):
"""Log security header issue"""
issue = {
'page': page_url,
'severity': severity,
'description': description,
'timestamp': time.time()
}
self.security_issues.append(issue)
print(f"SECURITY ISSUE [{severity}]: {description} on {page_url}")
@task(1)
def report_security_status(self):
"""Report current security validation status"""
if self.pages_checked < 3:
return
high_issues = [issue for issue in self.security_issues if issue['severity'] == 'HIGH']
medium_issues = [issue for issue in self.security_issues if issue['severity'] == 'MEDIUM']
print(f"SECURITY HEADERS STATUS: {len(self.security_issues)} total issues "
f"({len(high_issues)} high, {len(medium_issues)} medium) "
f"across {self.pages_checked} pages")
def on_stop(self):
"""Final security headers report"""
print("\n" + "="*50)
print("SECURITY HEADERS VALIDATION COMPLETE")
print("="*50)
print(f"Pages checked: {self.pages_checked}")
print(f"Total security issues: {len(self.security_issues)}")
if self.security_issues:
print(f"\nTOP SECURITY ISSUES:")
for issue in self.security_issues[:10]:
print(f"❌ [{issue['severity']}] {issue['description']}")
print(f" Page: {issue['page']}")
else:
print("✅ All pages have proper security headers!")
from locust import HttpUser, task, between
import re
import time
from urllib.parse import urlparse
from collections import deque, defaultdict
# COMPREHENSIVE CONFIGURATION
SECURITY_HEADERS_CONFIG = {
'required_headers': {
'Strict-Transport-Security': {
'required': True,
'min_max_age': 31536000, # 1 year minimum
'should_include_subdomains': True
},
'X-Frame-Options': {
'required': True,
'valid_values': ['DENY', 'SAMEORIGIN']
},
'X-Content-Type-Options': {
'required': True,
'valid_values': ['nosniff']
},
'Referrer-Policy': {
'required': True,
'valid_values': ['strict-origin-when-cross-origin', 'same-origin', 'no-referrer', 'strict-origin']
},
'Content-Security-Policy': {
'required': False, # Optional but recommended
'check_unsafe_directives': True
},
'Permissions-Policy': {
'required': False, # Modern replacement for Feature-Policy
}
},
'page_type_requirements': {
'login_pages': ['X-Frame-Options', 'Strict-Transport-Security'],
'api_endpoints': ['X-Content-Type-Options', 'Strict-Transport-Security'],
'admin_pages': ['X-Frame-Options', 'Strict-Transport-Security', 'Content-Security-Policy']
}
}
class ComprehensiveSecurityValidator(HttpUser):
wait_time = between(1, 3)
def on_start(self):
"""Initialize comprehensive security validation"""
self.visited_pages = set()
self.pages_to_check = deque(['/'])
self.security_issues = []
self.page_classifications = defaultdict(list)
self.header_stats = defaultdict(int)
self.base_domain = None
print("Starting comprehensive security headers validation...")
@task(5)
def crawl_and_validate_comprehensive(self):
"""Comprehensive security headers validation"""
if not self.pages_to_check:
return
current_page = self.pages_to_check.popleft()
if current_page in self.visited_pages:
return
self.visited_pages.add(current_page)
with self.client.get(current_page, name=f"SECURITY: {current_page}", catch_response=True) as response:
if response.status_code == 200:
if not self.base_domain:
self.base_domain = urlparse(self.client.base_url).netloc
# Classify page type
page_type = self._classify_page_type(current_page, response.text)
# Validate headers based on page type and general requirements
issues = self._comprehensive_header_validation(current_page, response.headers, page_type)
# Find more pages
self._find_internal_pages(response.text)
# Report results
if issues:
failure_msg = f"❌ {len(issues)} security issues found"
response.failure(failure_msg)
else:
response.success()
else:
response.failure(f"Could not access page: HTTP {response.status_code}")
def _classify_page_type(self, page_url, html_content):
"""Classify page type for specific security requirements"""
page_type = 'general'
# Check for login/auth pages
if any(keyword in page_url.lower() for keyword in ['/login', '/signin', '/auth', '/register']):
page_type = 'login_pages'
elif any(keyword in html_content.lower() for keyword in ['<input type="password"', 'login', 'sign in']):
page_type = 'login_pages'
# Check for API endpoints
elif '/api/' in page_url.lower() or page_url.startswith('/api'):
page_type = 'api_endpoints'
# Check for admin pages
elif any(keyword in page_url.lower() for keyword in ['/admin', '/dashboard', '/manage']):
page_type = 'admin_pages'
self.page_classifications[page_type].append(page_url)
return page_type
def _comprehensive_header_validation(self, page_url, headers, page_type):
"""Comprehensive validation of security headers"""
issues = []
config = SECURITY_HEADERS_CONFIG
# Check general required headers
for header_name, header_config in config['required_headers'].items():
if header_config.get('required', False):
if header_name not in headers:
issues.append(f"Missing {header_name}")
self._log_security_issue(page_url, 'HIGH', f'Missing required header: {header_name}')
else:
# Validate specific header requirements
header_value = headers[header_name]
header_issues = self._validate_header_value(header_name, header_value, header_config)
issues.extend(header_issues)
for issue in header_issues:
self._log_security_issue(page_url, 'MEDIUM', f'{header_name}: {issue}')
# Check page-type specific requirements
if page_type in config['page_type_requirements']:
required_for_type = config['page_type_requirements'][page_type]
for required_header in required_for_type:
if required_header not in headers:
issues.append(f"Missing {required_header} (required for {page_type})")
self._log_security_issue(page_url, 'HIGH',
f'Missing {required_header} required for {page_type}')
# Update statistics
for header_name in config['required_headers'].keys():
if header_name in headers:
self.header_stats[f'{header_name}_present'] += 1
else:
self.header_stats[f'{header_name}_missing'] += 1
return issues
def _validate_header_value(self, header_name, header_value, config):
"""Validate specific header value requirements"""
issues = []
if header_name == 'Strict-Transport-Security':
# Check max-age
max_age_match = re.search(r'max-age=(\d+)', header_value)
if max_age_match:
max_age = int(max_age_match.group(1))
min_age = config.get('min_max_age', 31536000)
if max_age < min_age:
issues.append(f'max-age too short: {max_age} (minimum: {min_age})')
else:
issues.append('missing max-age directive')
# Check includeSubDomains
if config.get('should_include_subdomains', False):
if 'includeSubDomains' not in header_value:
issues.append('missing includeSubDomains')
elif header_name == 'Content-Security-Policy' and config.get('check_unsafe_directives', False):
# Check for unsafe CSP directives
unsafe_patterns = ["'unsafe-inline'", "'unsafe-eval'"]
for pattern in unsafe_patterns:
if pattern in header_value:
issues.append(f'contains unsafe directive: {pattern}')
elif 'valid_values' in config:
valid_values = config['valid_values']
if header_name == 'Referrer-Policy':
# Referrer-Policy can have multiple values
if not any(valid_val in header_value for valid_val in valid_values):
issues.append(f'invalid value: {header_value}')
else:
if header_value not in valid_values:
issues.append(f'invalid value: {header_value} (expected: {valid_values})')
return issues
def _find_internal_pages(self, html_content):
"""Find internal pages from current page links"""
if len(self.pages_to_check) > 100: # Limit crawling depth
return
links = re.findall(r'<a[^>]+href=["\']([^"\']+)["\']', html_content, re.IGNORECASE)
for link in links:
if self._is_internal_page_link(link):
normalized_link = self._normalize_link(link)
if normalized_link and normalized_link not in self.visited_pages:
if normalized_link not in self.pages_to_check:
self.pages_to_check.append(normalized_link)
def _is_internal_page_link(self, link):
"""Check if link is an internal page"""
if any(skip in link.lower() for skip in ['#', 'mailto:', 'tel:', 'javascript:']):
return False
resource_extensions = ['.css', '.js', '.jpg', '.jpeg', '.png', '.gif', '.pdf', '.zip',
'.svg', '.ico', '.mp4', '.mp3', '.woff', '.woff2', '.ttf', '.eot']
if any(link.lower().endswith(ext) for ext in resource_extensions):
return False
if link.startswith('/') or not link.startswith('http'):
return True
if link.startswith('http') and self.base_domain:
return urlparse(link).netloc == self.base_domain
return False
def _normalize_link(self, link):
"""Normalize link for checking"""
try:
if link.startswith('/'):
return link.split('#')[0]
elif not link.startswith('http'):
return '/' + link.lstrip('./')
elif self.base_domain and link.startswith('http'):
parsed = urlparse(link)
if parsed.netloc == self.base_domain:
return parsed.path
return None
except:
return None
def _log_security_issue(self, page_url, severity, description):
"""Log security issue with details"""
issue = {
'page': page_url,
'severity': severity,
'description': description,
'timestamp': time.time()
}
self.security_issues.append(issue)
print(f"SECURITY ISSUE [{severity}]: {description} on {page_url}")
@task(1)
def generate_security_report(self):
"""Generate comprehensive security report"""
if len(self.visited_pages) < 5:
return
high_issues = [i for i in self.security_issues if i['severity'] == 'HIGH']
medium_issues = [i for i in self.security_issues if i['severity'] == 'MEDIUM']
print(f"SECURITY REPORT: {len(self.security_issues)} total issues "
f"({len(high_issues)} high, {len(medium_issues)} medium) "
f"across {len(self.visited_pages)} pages")
# Report page type distribution
for page_type, pages in self.page_classifications.items():
print(f" {page_type}: {len(pages)} pages")
def on_stop(self):
"""Final comprehensive security report"""
print("\n" + "="*60)
print("COMPREHENSIVE SECURITY HEADERS VALIDATION COMPLETE")
print("="*60)
print(f"Pages validated: {len(self.visited_pages)}")
print(f"Total security issues: {len(self.security_issues)}")
# Header statistics
print(f"\nHEADER STATISTICS:")
for header, count in self.header_stats.items():
print(f" {header}: {count}")
# Page type breakdown
print(f"\nPAGE TYPE BREAKDOWN:")
for page_type, pages in self.page_classifications.items():
print(f" {page_type}: {len(pages)} pages")
if self.security_issues:
print(f"\nTOP SECURITY ISSUES:")
for issue in self.security_issues[:10]:
print(f"❌ [{issue['severity']}] {issue['description']}")
print(f" Page: {issue['page']}")
else:
print("✅ All pages have proper security headers!")
Edit the configuration at the top of the script to match your security requirements:
True for headers that must be presentThis guide provides comprehensive security headers validation across your entire website with flexible configuration options.