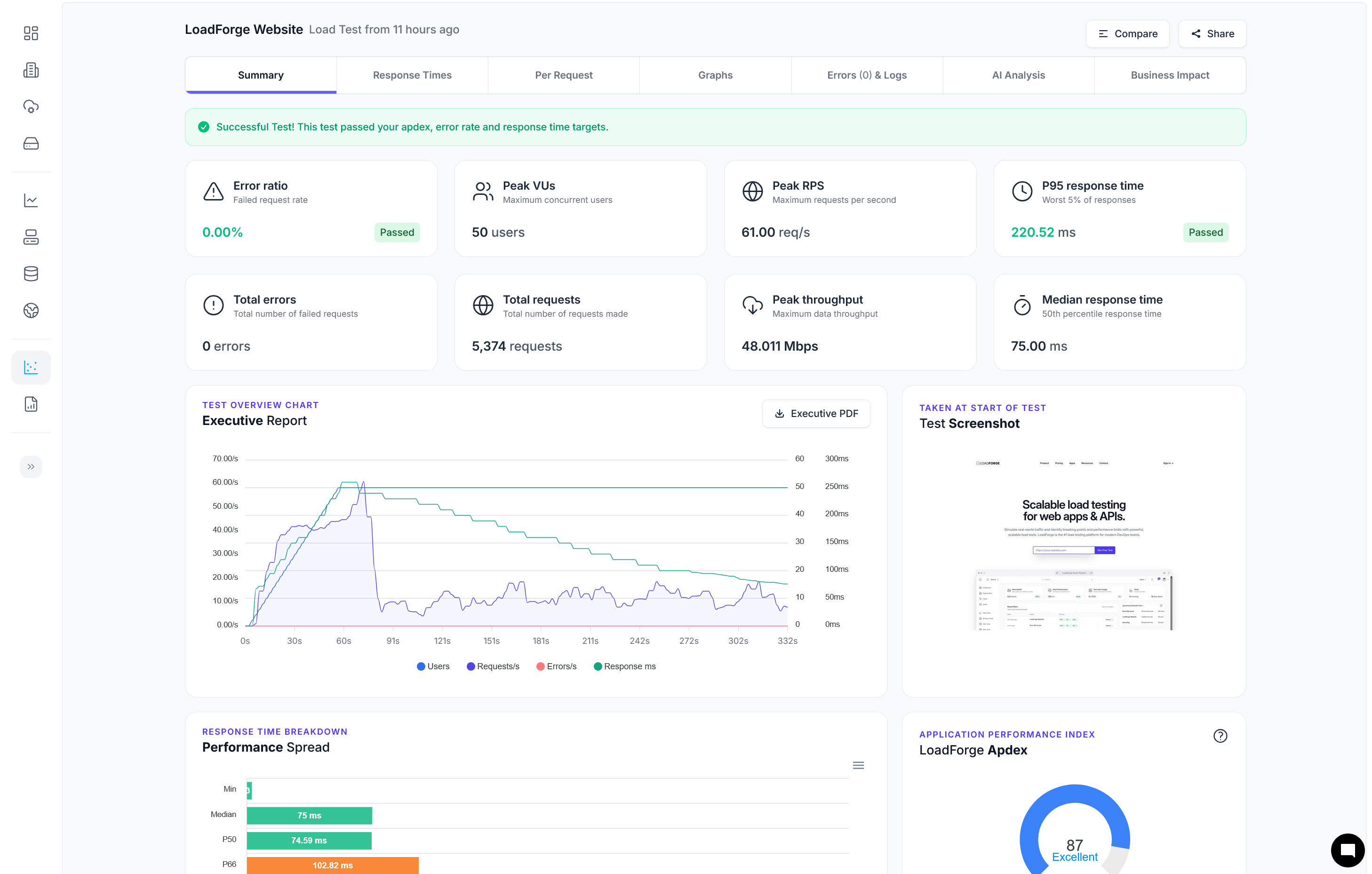
Introduction to Database Indexing
In the realm of database management, performance optimization is a continual priority. One of the most effective tools at our disposal for enhancing query speed and overall database performance is indexing. This section will delve into what database indexes are, how they function, and their critical role in database performance optimization.
What are Database Indexes?
Database indexes are specialized data structures that improve the speed of data retrieval operations on a database table at the cost of additional writes and storage space to maintain them. Indexes can be likened to the index in a book, which allows you to quickly find the necessary information without flipping through each page. In database terms, an index allows the database server to find and retrieve specific rows much faster than without an index.
How Do Indexes Work?
An index is created on a column (or a set of columns) in a database table. When an index is created, the database management system (DBMS) sorts the values of the specified column(s) and links them with the corresponding row identifiers (row IDs). This sorted list of column values allows the DBMS to perform binary searches to quickly locate the row IDs associated with the column value being sought.
Consider this simple SQL command that creates an index on the lastname column in a customers database table:
CREATE INDEX idx_lastname ON customers (lastname);
When this index is in place, a query searching for a specific last name, such as:
SELECT * FROM customers WHERE lastname = 'Doe';
will run significantly faster compared to the same query on a table without an index. The DBMS can use the index to directly locate all entries under 'Doe', bypassing the need to scan every row in the table.
Why are Indexes Crucial?
Indexes are crucial for several reasons:
- Speed: Indexes provide a fast-access path to data in database tables, significantly reducing the time it takes to fetch data based on the indexed column(s).
- Efficiency: They make database operations more efficient, allowing systems to handle larger volumes of transactions and queries.
- Scalability: Properly indexed databases scale better, handling an increased load of data retrieval requests without a substantial dip in performance.
However, indexes need to be used wisely. They come at the cost of additional storage and overhead on write operations (INSERT, UPDATE, DELETE). Every time data is added, deleted, or modified, every index on the table needs to be updated. Therefore, it's crucial to implement indexes strategically, optimizing the balance between query speed and update cost.
In the following sections, we will explore different types of indexes, how to select proper columns for indexing, balancing the number of indexes, and more advanced indexing techniques. By the end of this guide, you’ll have a solid understanding of how to optimize database indexes for maximum performance.
Understanding Index Types
In the realm of databases, indexes are powerful tools designed to speed up the retrieval of records, enhancing the performance of queries. Understanding the different types of indexes can help you design a database that responds efficiently to various query demands. Below, we explore the primary types of indexes used in most databases and discuss when each type is best utilized.
Primary Indexes
Primary indexes are created on a primary key column, which uniquely identifies each row in a database table. The primary key index is crucial for efficiently finding rows based on primary key values and is automatically created when you designate a column as the primary key.
Usage: Employ primary indexes when you need fast lookup capabilities on a column that uniquely identifies records. For instance, retrieving customer information based on a unique customer ID.
Secondary Indexes
Secondary indexes, also known as non-clustered indexes, do not have to be unique and can be created on columns other than the primary key. These indexes are beneficial for speeding up access to data that isn't necessarily unique, allowing more flexible query possibilities.
Usage: Use secondary indexes for columns frequently used in query conditions (WHERE clauses) but are not the primary key, like indexing a 'last_name' column in a customer database to quickly find all customers with a certain last name.
Unique Indexes
A unique index ensures that all the values in a column are distinct, preventing duplicate values in the indexed column. This index not only improves retrieval efficiency but also enforces data integrity by ensuring uniqueness.
Usage: Essential when you need to guarantee uniqueness in a column that isn't a primary key, such as an email address or username in a user account table.
Full-Text Indexes
Full-text indexes cater to unstructured text data. They allow for the efficient querying of text columns for comprehensive text-based searches, supporting the searching of words and phrases within strings of text.
Usage: Implement full-text indexes on large text fields when applications require robust search capabilities, like searching for articles or blog posts based on keywords or phrases contained within their content.
Composite Indexes
Composite indexes involve more than one column, constructed to speed up data retrieval that involves multiple columns. This type of index should be considered when query conditions regularly involve several columns.
Usage: Perfect for querying on multiple columns, such as fetching records from a log file where both the event date and event type might be specified in the WHERE clause.
Choosing the Right Index Type
Selecting the appropriate index type requires a careful analysis of query needs and understanding of how each index works. Here are general guidelines to help decide:
- Uniqueness Required: Choose unique indexes.
- Speed Up Text Searches: Full-text indexes are your go-to options.
- Frequent Retrieval by Composite Conditions: Consider composite indexes.
- Main Identifier for Rows: Primary indexes are necessary.
- Commonly Referenced Non-Key Data: Secondary indexes will enhance performance.
The effective use of these indexes plays a pivotal role in the optimization of database performance, making an understanding of their characteristics and application essential for any database administrator or developer.
The Right Choice: Selecting Appropriate Index Columns
Choosing the correct columns to index is pivotal in enhancing query performance and overall database efficiency. This decision should be informed by a thorough analysis of your database's query patterns. This section details key considerations that should guide your selection of index columns, primarily focusing on query analysis and the identification of columns most frequently used in WHERE clauses.
Analyzing Query Patterns
Before diving into indexing, it's crucial to understand how your database is queried. Start by collecting and analyzing query logs over a significant period to capture peak and typical usage scenarios. Look for:
- Frequency of Queries: Identify the queries executed most frequently.
- Query Types: Distinguish between read-heavy versus write-heavy query operations.
- Columns in WHERE Clauses: Pinpoint which columns are commonly used in
WHERE clauses, as they are prime candidates for indexing.
- Join Conditions: Note columns used in
JOIN conditions, which might also benefit from indexing.
This analysis provides a foundational understanding necessary for effective index planning.
Identifying Key Columns
With insights from your query analysis, you can identify which columns are the best candidates for indexing. Here are some criteria to assist in making these choices:
- High Query Volume: Columns that appear often in queries are typically prime candidates for indexing.
- Filtering and Sorting: Columns used to filter (
WHERE clause) or sort (ORDER BY clause) results often yield the greatest impact when indexed.
- Cardinality: Columns with a high number of unique values (high cardinality) generally provide more efficient indexing than columns with few unique values.
Consider the following SQL example that frequently appears in your logs:
SELECT username, email FROM users WHERE last_login > '2023-01-01' AND status = 'active';
In this query, indexing last_login and status might improve performance since they are used directly in filtering the data.
Balance and Practicality
While it’s tempting to index many columns, this approach can lead to increased storage and slower write operations. Always weigh the read performance improvement against the potential write performance cost. Practical indexing involves:
- Selecting a few high-impact columns rather than many with marginal benefits.
- Using composite indexes judiciously, where appropriate. For example, if a query filters by
customer_id and sorts by date, a composite index on (customer_id, date) might be effective.
Tools and Techniques for Decision Making
Several database management tools provide features to help identify potentially beneficial index columns based on query logs. For example, SQL Server’s Query Store and Oracle’s Automatic Workload Repository (AWR) collect performance data that can be analyzed to suggest optimal indexing strategies.
Using these tools, coupled with a deep understanding of your application’s data access patterns, will guide you in making informed decisions about which columns to index. This strategic approach ensures that your database is optimized for both current and future performance needs.
Balancing Indexes: More Isn't Always Better
When optimizing a database, indexes are powerful tools that enhance read performance by reducing the time it takes to locate and retrieve data. However, it's essential to understand that the benefits of indexes come at a cost, and more isn’t always better. In this section, we will explore the trade-offs associated with excessive indexing and how to strike the right balance between read and write performance.
The Costs of Over-Indexing
Increased Storage Requirements
Each index you create consumes additional storage space. This not only affects the cost associated with disk space but also increases the backup size and time needed to complete database backups.
Slower Write Operations
Inserts, updates, and deletes become slower with more indexes. Whenever data is modified, each index must also be updated, which can lead to significant performance degradation in write-intensive applications.
Complexity and Maintenance Overhead
Managing a large number of indexes can become a complex task. More indexes mean more maintenance work, such as rebuilding and reorganizing to maintain performance, which adds to the administrative overhead.
Balancing the Trade-Offs
To effectively balance the trade-offs, consider the following strategies:
-
Analyze Query Performance
Begin by analyzing your most common queries and their execution plans. Understand which queries are benefitting from existing indexes and identify slow operations that might require indexing.
-
Use the Right Indexes
Not all indexes are created equal. Choose the type of index that best suits the needs of your queries:
- Use primary indexes for frequently queried columns.
- Implement secondary indexes only when they provide substantial performance improvements to read operations.
-
Index Selective Columns
Focus on indexing columns used in WHERE clauses, JOIN conditions, or as part of an ORDER BY. Avoid indexing columns with high cardinality or frequent modifications.
-
Monitor Index Usage
Regularly monitor index usage and performance. Remove or adjust indexes that are not providing performance benefits. Tools like SQL Server's Dynamic Management Views (DMVs) or MySQL's Performance Schema can be invaluable here.
-
Consider Write-Read Ratio
Evaluate the ratio of write operations to read operations. High write environments might suffer from too many indexes, while read-heavy environments could benefit more from additional indexes.
-
Implement Index Maintenance Plans
Regular index maintenance, such as reorganizing and rebuilding indexes, helps in keeping them efficient and reducing bloat.
By understanding the implications of over-indexing and applying these balancing techniques, you can optimize both sides of the performance coin—ensuring that your database environment supports rapid read operations without compromising the efficiency of write operations. Effective index management is not about having the most indexes, but about having the right indexes configured and maintained properly.
Index Configuration Settings
Proper configuration of database indexes is crucial for enhancing performance and ensuring efficient resource usage. In this section, we will discuss critical index configuration settings that can be finely tuned to maximize your database's performance. The focus will be predominantly on fill factors and buffer configurations.
Fill Factor
The fill factor is a configuration setting that determines the percentage of space on each leaf-level page to be filled with data, reserving the rest as free space for future growth. This setting is crucial because it directly affects the database's insertion and update operations. Setting an optimal fill factor can help in reducing page splits, which occur when there is not enough free space to insert new data, leading to increased fragmentation and, consequently, poorer performance.
Here’s how you can set the fill factor in SQL Server:
ALTER INDEX [YourIndexName] ON [YourTableName]
REBUILD WITH (FILLFACTOR = 80);
In the above example, 80 signifies that 80% of the space on each page will be filled with data, leaving 20% free for future inserts. This setting should be decided based on the nature of the data usage. Static tables, where updates and inserts are rare, can have a higher fill factor, close to 100%. In contrast, highly volatile tables benefit from a lower fill factor.
Buffer Configurations
Buffer pool configuration is another critical aspect of index performance tuning. The buffer pool is a memory pool that stores copies of data pages, including index pages, reducing the number of disk reads by serving data requests from memory, which is significantly faster.
The size of the buffer pool should be configured based on the system's total memory and the database's workload characteristics. A larger buffer pool can increase the cache hit ratio, but it must be balanced with other memory demands of the system.
Here's an example of configuring the buffer pool size in MySQL:
SET GLOBAL innodb_buffer_pool_size = 134217728; -- size in bytes
Considerations for Configuration
When configuring indexes, consider the following:
- Workload Type: Read-heavy versus write-heavy workloads may require different settings for optimal performance.
- Hardware Specifications: Faster disks and more memory can influence decisions on fill factor and buffer sizes.
- Database Size and Growth: Larger databases or those expected to grow quickly might need dynamic adjustments in their configuration.
Lastly, always ensure that changes to index configurations are monitored and tested comprehensively to validate their impact on performance. Regularly reviewing and adjusting these settings as your database evolves is essential to maintain optimal performance.
Index Maintenance Strategies
Effective database performance heavily depends on not just how well indexes are set up but also how they are maintained over time. As your database evolves with changes in the data structure, query patterns, and volume of data, indexes can become fragmented and outdated. This can significantly deteriorate the performance of your database queries, leading to longer processing times and increased load. Regular maintenance tasks like index rebuilding and reorganizing are vital in preventing such performance degradation.
Understanding Index Fragmentation
Over time, as data is updated, inserted, or deleted from your database, the physical order of data records becomes scattered, causing fragmentation. This fragmentation leads to inefficient disk I/O as the query engine struggles to locate all the data points necessary to fulfill a query. To measure how fragmented an index is, you can often use system-specific functions. For SQL Server, for instance, this can be assessed using the sys.dm_db_index_physical_stats dynamic management view:
SELECT index_id, avg_fragmentation_in_percent
FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, 'SAMPLED');
Rebuilding vs. Reorganizing Indexes
Rebuilding Indexes: Rebuilding an index essentially recreates the index from scratch. It is a more thorough process than reorganization and is beneficial because it also updates index statistics, which can lead to improved query performance. However, it requires more system resources and can lock the table this index belongs to during the operation, which might not be acceptable in high-availability environments.
Reorganizing Indexes: Reorganizing an index defragments the leaf level of clustered and non-clustered indexes on tables and views by physically reordering the pages to match the logical order. It is a less resource-intensive process compared to rebuilding and generally does not require table locking, making it suitable for more frequent maintenance schedules.
Use the following SQL Server commands to handle these tasks:
-- Rebuild index
ALTER INDEX ALL ON YourTableName REBUILD;
-- Reorganize index
ALTER INDEX ALL ON YourTableName REORGANIZE;
Choosing Between Rebuild and Reorganize
Selecting between rebuilding or reorganizing indexes depends on the level of fragmentation. As a rule of thumb, if the fragmentation is above 30%, a rebuild might be more effective. For fragmentation between 5% and 30%, reorganizing the indexes could be beneficial. Remember, these thresholds can vary based on your specific database workload and environment.
Automating Index Maintenance
Given the importance and repetitive nature of index maintenance, automating this process can help ensure it's done consistently and without human error. Most modern database management systems (DBMS) allow for the scheduling of such tasks. For instance, in SQL Server, you can use SQL Server Agent to schedule and automate these tasks:
USE msdb ;
GO
EXEC dbo.sp_add_job
@job_name = N'Weekly Index Reorganize';
-- Add steps, schedules, and targets for the job
Regular Monitoring and Adjustments
While automating is helpful, it's essential to continuously monitor the performance of your indexes to optimize the maintenance strategy. This includes altering the frequency of maintenance operations and adjusting the rebuild or reorganize thresholds as necessary based on performance metrics and business requirements.
In conclusion, regular and proactive index maintenance is a critical aspect of database management that helps preserve and enhance performance. By understanding when and how to effectively rebuild or reorganize indexes, and by leveraging automation, you can maintain optimal database efficiency and ensure that your applications continue to perform well under varying loads and data volumes.
Monitoring Index Performance
Effective monitoring of index usage and performance is essential for maintaining the overall health and efficiency of your database systems. The aim is to identify indices that are either underperforming or not being used, and to determine when to optimize or remove them. This section delves into the various tools and methodologies for monitoring index performance, interpreting the data collected, and making informed decisions based on these insights.
Tools for Monitoring Indexes
Several database management systems offer built-in tools for index monitoring, which can be supplemented with third-party solutions for deeper insights. Here are some of the commonly used tools:
-
Database Management System (DBMS) Tools: Most DBMS like MySQL, PostgreSQL, and SQL Server provide native tools or views that can show index usage statistics. For example, SQL Server provides Dynamic Management Views (DMV) such as sys.dm_db_index_usage_stats which gives information about how often the index is read from or written to.
SELECT OBJECT_NAME(S.[OBJECT_ID]) AS [OBJECT NAME],
I.[NAME] AS [INDEX NAME],
USER_SEEKS,
USER_SCANS,
USER_LOOKUPS,
USER_UPDATES
FROM SYS.DM_DB_INDEX_USAGE_STATS AS S
INNER JOIN SYS.INDEXES AS I ON I.[OBJECT_ID] = S.[OBJECT_ID]
AND I.INDEX_ID = S.INDEX_ID
WHERE OBJECTPROPERTY(S.[OBJECT_ID],'IsUserTable') = 1;
-
Performance Monitoring Tools: Tools like Prometheus, Nagios, or Grafana can be configured to capture and visualize database metrics, including those related to index performance.
-
Custom Scripts and Queries: Depending on the database, custom scripts and queries can be written to monitor specific aspects of index performance that are critical to your environment.
Interpreting the Results
Monitoring tools will provide a wealth of data, which must be interpreted correctly to make effective decisions. Key metrics to pay attention to include:
-
Index Usage Statistics: How frequently an index is accessed for reads versus how much it is affected by writes. A highly accessed index for reads is a good candidate for optimization.
-
Index Operational Metrics: Measures like index seek time and scan time can provide insights into the performance of indexes under different workloads.
-
Missing Indexes: Some tools suggest missing indexes that could potentially improve performance based on the current workload analysis.
When to Act on the Monitoring Data
Decision-making based on index monitoring should consider the following:
-
High Write-to-Read Ratio: If an index is rarely used but frequently updated, it might be a candidate for removal to speed up write operations.
-
Unused Indexes: Indexes that are not used at all should be removed to free up resources.
-
Frequent Reads and Slow Performance: If an index is heavily used but performs poorly, consider optimizing it by looking at configuration settings or reconstructing it.
-
Suggested Indexes: Implement suggested indexes in a controlled environment to measure performance improvements before deploying them in production.
-
Regular Reviews: Index usage patterns can change as application usage evolves. Regularly reviewing and adjusting indexes is crucial for maintaining optimal performance.
Conclusion
Continuous monitoring and proactive management of indexes are crucial for database efficiency. By leveraging the right tools to gather data and developing a nuanced understanding of that data, database administrators can substantially enhance query performance, leading to faster and more reliable applications.
Advanced Indexing Techniques
In the realm of database optimization, advanced indexing techniques can provide significant advantages in managing complex queries and large volumes of data. This section delves into several sophisticated indexing strategies such as partial indexing, functional or indexed computed columns, and the strategic use of index hints. Each technique has distinct applications and benefits that can help fine-tune query performance.
Partial Indexing
Partial indexing involves creating indexes on a subset of a table's data, particularly useful when queries frequently target only a fraction of the records. This approach can reduce the size of the index and improve write performance by limiting the number of index updates. It is particularly effective in scenarios where data distribution is uneven or when only a small segment of data meets certain criteria.
Example Usage:
CREATE INDEX idx_partial_active_users ON users (last_login)
WHERE active = TRUE;
In this example, the index is created only for active users, making the query faster when filtering on active users and last_login.
Indexed Computed Columns
Indexed computed columns allow you to create an index on a result of a calculation or function, rather than directly on a column. This is particularly valuable when you frequently need to query computed values. By indexing the result, you avoid the overhead of recalculating the value each time the query runs.
Example Usage:
ALTER TABLE orders
ADD total_cost AS (quantity * price) PERSISTED;
CREATE INDEX idx_total_cost ON orders (total_cost);
Here, total_cost is a computed column which is persisted and indexed, ensuring that any queries filtering or sorting by total_cost are much quicker.
Index Hints
Index hints provide a way to suggest to the SQL query engine which index to use for a particular query. This can be crucial in optimizing performance, especially in complex queries where the query planner might not choose the most efficient index. However, use hints cautiously, as incorrect hints can degrade performance.
Example Usage:
SELECT * FROM users USE INDEX (idx_last_login)
WHERE last_login >= '2023-01-01';
This SQL command uses an index hint (USE INDEX) to explicitly dictate which index to use, bypassing the database engine's default index selection mechanism.
Conclusion on Advanced Techniques
These advanced techniques showcase the flexibility and depth available in modern databases for optimizing query performance. Partial indexing is excellent for targeting specific segments of data, while indexed computed columns can drastically reduce on-the-fly computation costs. Index hints offer a manual override that can be beneficial in complex querying scenarios. Implementing these advanced strategies requires a thorough understanding of both the data and the queries that are common to your application to ensure they lead to actual performance improvements rather than inadvertent complications.
Handling Large Scale Indexes
When managing databases, especially in large-scale environments, the complexity and size of data can introduce significant challenges in index management. Efficient handling of these indexes is crucial to maintaining high performance and scalability. This section dives into effective strategies for managing large-scale indexes, focusing particularly on partitioning and addressing scalability concerns.
Index Partitioning
Partitioning is a powerful technique to manage large indexes by dividing them into smaller, more manageable pieces, often called partitions. This approach not only enhances query performance but also improves maintenance operations by allowing actions on these partitions independently. There are several strategies to consider:
-
Range Partitioning: This involves dividing an index based on a range of values in a particular column. It is ideal for ordered data, such as dates.
CREATE INDEX idx_orderdate ON Orders(OrderDate)
PARTITION BY RANGE (OrderDate) (
PARTITION p0 VALUES LESS THAN ('2022-01-01'),
PARTITION p1 VALUES LESS THAN ('2023-01-01'),
PARTITION p2 VALUES LESS THAN (MAXVALUE)
);
-
List Partitioning: Useful for categorizing non-sequential and discrete values, such as status codes or regions.
CREATE INDEX idx_status ON Orders(Status)
PARTITION BY LIST (Status) (
PARTITION p_open VALUES IN ('Open', 'Pending', 'Confirmed'),
PARTITION p_closed VALUES IN ('Closed', 'Cancelled')
);
-
Hash Partitioning: This method distributes data based on a hash key derived from one of the columns, suitable for achieving uniform data distribution.
CREATE INDEX idx_customer_id ON Orders(CustomerID)
PARTITION BY HASH (CustomerID)
PARTITIONS 4;
Scalability Concerns
As data grows, indexing strategies need to adapt to maintain performance and efficiency. Consider these scalability strategies:
-
Dynamic Indexing: Implement automation in your indexing strategy where new indexes are created or dropped based on the evolving access patterns and query performance. This requires continuous monitoring and adjustment.
-
Distributed Indexing: In distributed database systems, consider using distributed indexes that can span multiple instances or nodes. This reduces the load on any single machine and improves query response times across the network.
-
Use of Materialized Views: For frequently accessed query results, consider using materialized views that store the query result as a physical table and indexing it, thereby speeding up read operations significantly.
Monitoring and Optimizing Large Scale Indexes
Regular monitoring of index performance and usage is critical in large-scale environments. Tools like Oracle's AWR or PostgreSQL's pg_stat_user_indexes provide valuable insights into index utilization and effectiveness. Key metrics to watch include:
- Index hit rate
- Index scan frequency
- Query response times
Based on these insights, perform regular index optimizations:
-
Rebuilding Indexes: Over time, indexes can become fragmented. Regularly rebuilding indexes can consolidate index pages and free up disk space. This is particularly beneficial in OLTP systems.
-
Fine-Tuning Index Attributes: Adjusting attributes like fill factor or buffer sizes can fine-tune the performance of your indexes according to the specific workload and usage patterns.
Handling large-scale indexes effectively demands an understanding of both the technical aspects of indexing and the specific characteristics of your database workload. By employing strategies like partitioning and regularly monitoring index performance, you can ensure that your database environment remains scalable and performs optimally.
Case Studies and Real-World Examples
In this section, we explore compelling case studies and real-world examples that demonstrate the effectiveness of thoughtful index optimization in various database environments. These examples underscore the tangible benefits that can be achieved through strategic indexing practices.
Case Study 1: E-Commerce Platform Scaling
Background: A fast-growing e-commerce platform was experiencing slow response times during peak shopping periods, which were traced back to database queries taking excessive time due to a lack of appropriate indexing.
Problem: The product search functionality, which was critical for customer experience, was bogged down by queries scanning full tables to retrieve information.
Solution: The database team implemented a combination of multi-column indexes on frequently searched fields like product name, category, and price range. They also introduced index hints to optimize the execution plans generated by the SQL server.
Outcome: The indexing adjustments led to a 70% reduction in query response time and a significant drop in CPU usage during peak times.
CREATE INDEX idx_product_search ON Products (ProductName, CategoryID, Price)
Case Study 2: Financial Services Report Optimization
Background: A financial services company needed to generate complex reports involving multiple joins and aggregations, which were initially taking an unacceptable amount of time to run.
Problem: Reports were constructed from large tables with millions of rows, but without efficient indexes, leading to full table scans.
Solution: After reviewing the query patterns, the team decided to implement indexed views for the most computationally heavy queries and used unique indexes to ensure data integrity while speeding up lookup times.
Outcome: Reports that previously took over an hour to generate were now completed in less than ten minutes, markedly improving the operational efficiency of the team.
CREATE UNIQUE INDEX idx_transaction_summary ON TransactionSummary (TransactionDate, UserID)
Case Study 3: Social Media Platform User Experience Enhancement
Background: A popular social media platform was struggling with slow load times for user timelines, which were impacting user engagement and satisfaction.
Problem: The timeline feature relied heavily on a complicated query that involved sorting and filtering through millions of posts based on user connections, which didn't utilize indices efficiently.
Solution: The database engineers introduced composite indexes on columns that were frequently accessed together and used partial indexes for commonly filtered statuses.
Outcome: The refinement of indices led to a 50% improvement in timeline loading times and enhanced user experience.
CREATE INDEX idx_user_posts ON Posts (UserID, PostDate)
WHERE Status = 'Active'
These examples illustrate that while indexing is a powerful tool for improving database performance, the key lies in identifying which queries need optimization and understanding how different types of indexes can be applied effectively. By examining these real-world scenarios, organizations can gain insights into strategic index usage that aligns with their specific performance goals.