Introduction to FastAPI Performance
FastAPI is an increasingly popular web framework for building APIs with Python 3.7+ based on standard Python type hints. The key feature of FastAPI is its speed and performance, which stems primarily from its starlette framework for the web parts and its use of Pydantic for the data parts. This combination makes FastAPI one of the fastest frameworks available for Python, highly efficient at handling parallel requests and scalable operations.
Why Focus on Performance?
In the context of modern web applications, performance is not just about speed; it’s about resource optimization, scalability, and providing a seamless user experience. As web applications grow and traffic increases, efficiently managing resources becomes crucial. Applications must handle requests swiftly and provide responses without delay, even under heavy load.
Asynchronous Capabilities
FastAPI's real standout feature is its built-in support for asynchronous request handling. This means that the server can handle multiple requests at the same time, enabling it to perform other tasks between request calls. This is particularly beneficial for IO-bound and high-level parallel execution operations. Here's a simple example of an asynchronous route in FastAPI:
from fastapi import FastAPI
import asyncio
app = FastAPI()
@app.get("/")
async def read_root():
await asyncio.sleep(1) # simulate a database read or an API call
return {"Hello": "World"}
In this code, asyncio.sleep simulates an asynchronous operation, such as querying a database or calling an external API, which would allow the FastAPI server to handle other requests while waiting for the operation to complete.
Importance of Performance Tuning
Despite its naturally efficient architecture, there is a still need for performance tuning in FastAPI applications. Optimizing performance can involve various strategies, from refining database interactions to streamlining asynchronous code. Such tuning ensures your application can handle higher loads, process larger volumes of data, and respond quicker to user requests, all while using fewer server resources.
In this guide, we will explore several tactics to boost your FastAPI application's performance, ensuring it runs optimally in dynamic and demanding production environments. By implementing these strategies, we aim for not only fast execution but also efficient resource utilization, providing a sturdy foundation for scaling applications as demands increase.
Database Interaction Optimization
Optimizing database interactions is crucial for enhancing the performance of FastAPI applications. Efficient database access patterns can drastically reduce latency, increase throughput, and minimize the server load. This section will cover techniques such as using asynchronous database drivers, employing connection pooling, and leveraging ORM caching effectively.
Using Asynchronous Database Drivers
FastAPI is an asynchronous framework, which means it can handle many requests concurrently. To fully leverage this feature, it's essential to use asynchronous database drivers. These drivers operate non-blockingly, enabling FastAPI to keep handling other requests while waiting for database operations to complete. For SQL databases, popular asynchronous drivers include asyncpg for PostgreSQL and aiomysql for MySQL.
Example: Using asyncpg with FastAPI
from fastapi import FastAPI
import asyncpg
from pydantic import BaseModel
class Record(BaseModel):
id: int
name: str
app = FastAPI()
async def get_pg_connection():
return await asyncpg.connect('postgresql://user:password@localhost/dbname')
@app.get("/items/{item_id}", response_model=Record)
async def read_item(item_id: int):
conn = await get_pg_connection()
record = await conn.fetchrow('SELECT * FROM records WHERE id=$1', item_id)
await conn.close()
return record
Connection Pooling
Connection pooling is another vital aspect of database interaction optimization. It refers to the method of creating and maintaining a pool of database connections that can be reused for multiple requests instead of establishing a new connection each time a database query is made. This reduces connection overhead and significantly improves application performance. Asynchronous libraries like asyncpg come with built-in support for connection pooling.
Example: Implementing Connection Pooling with asyncpg
import asyncpg
from fastapi import FastAPI
app = FastAPI()
async def create_pool():
return await asyncpg.create_pool('postgresql://user:password@localhost/dbname')
pool = await create_pool()
@app.on_event("startup")
async def startup_event():
global pool
pool = await create_pool()
@app.on_event("shutdown")
async def shutdown_event():
await pool.close()
@app.get("/items/{item_id}")
async def read_item(item_id: int):
async with pool.acquire() as connection:
record = await connection.fetchrow('SELECT * FROM records WHERE id=$1', item_id)
return record
Effective Use of ORM Caching
Object-Relational Mapping (ORM) caching is a technique to cache the results of database queries so that subsequent requests for the same data are served from the cache, reducing the number of queries to the database. This is particularly beneficial for read-heavy applications. Libraries such as SQLAlchemy (for synchronous ORM) and databases (for asynchronous ORM) offer caching mechanisms that can be configured for optimal performance.
Configuring Cache with SQLAlchemy
from sqlalchemy.orm import scoped_session, sessionmaker
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine
from sqlalchemy.orm import relationship, backref, session
DB_URL = "sqlite:///./test.db"
engine = create_engine(DB_URL, echo=True)
session_factory = sessionmaker(bind=engine)
Session = scoped_session(session_factory)
Base = declarative_base()
# Utilize the Session for ORM operations
session = Session()
Each of these approaches—using asynchronous database drivers, employing connection pooling, and leveraging ORM caching—plays an integral role in optimizing database interactions in FastAPI applications. By implementing these strategies, developers can ensure their applications are not only performant but also scalable and efficient.
Code Profiling and Optimization
Performance tuning is an essential step towards creating a scalable and efficient FastAPI application. This section explores how the use of profiling tools can help identify bottlenecks and improve the performance of your FastAPI applications by fine-tuning both the code and its asynchronous operations.
Identifying Bottlenecks with Profiling Tools
Profiling is the process of measuring the resource usage of various parts of your program, identifying sections of code that could slow down execution. For a FastAPI application, you might use profiling tools like cProfile for synchronous code and aiohttp-devtools for asynchronous code to get detailed reports on CPU time and function call frequency.
Here’s a basic example of how to implement cProfile in a FastAPI application:
import cProfile
import pstats
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
async def read_root():
pr = cProfile.Profile()
pr.enable()
# Simulated API operation
response = compute_heavy_operation()
pr.disable()
stats = pstats.Stats(pr).sort_stats('cumtime')
stats.print_stats()
return response
def compute_heavy_operation():
return {"Hello": "World"}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
In the example above, cProfile is used to profile a simulated heavy operation within a FastAPI route to ascertain time-consuming functions.
Best Practices for Efficient Async Code
Writing efficient asynchronous code in FastAPI involves not only proper async-await usage but also adhering to certain best practices:
-
Avoid Blocking Operations: Ensure that I/O operations like reading from the database or sending network requests are performed asynchronously. Utilizing synchronous code within an asynchronous path can lead to significant performance downgrades.
-
Use Fast Async Libraries: Utilize libraries that support asynchronous operations (e.g., httpx for HTTP requests, aioredis for Redis operations) to keep your API non-blocking and faster.
-
Optimize Await Calls: Too many await calls can lead to context switching which might slow down your application. Group await calls or use asyncio.gather to run multiple tasks concurrently.
-
Concurrency vs. Parallelism: Understand when to use concurrency (cooperative multitasking with async and await) and when to use parallelism (using threads or multiple processes) to handle different parts of your application workload effectively.
Avoiding Common Pitfalls
Common pitfalls in asynchronous FastAPI applications often involve mismanagement of asynchronous contexts and resource handling:
-
Starvation: Occurs when long-running tasks do not yield control over the event loop, thus blocking other operations. It's crucial to split large tasks into smaller, manageable async functions.
-
Memory Leaks: Improper handling of resource management in asynchronous programming may lead to memory leaks. Always ensure that database connections and file handles are properly closed after operations.
-
Error Handling: Asynchronous applications should have robust error handling to prevent unexpected failures from cascading and impacting user experience. Utilize FastAPI’s exception handlers to manage anticipated and unanticipated errors gracefully.
By implementing the profiling techniques and adapting the best practices outlined in this section, you can significantly optimize the performance of your FastAPI applications. This optimization not only enhances the responsiveness of your APIs but also provides a more scalable platform to handle growing user demands efficiently.
Dependency Management and Reduction
In the development of web applications with FastAPI, managing and reducing dependencies is a critical factor in optimizing both load times and overall application efficiency. Dependencies are external libraries or frameworks that your application uses to function. While they can provide valuable functionality, each added dependency increases the complexity and the size of your application, which can, in turn, affect startup time and resource usage.
Why Reduce Dependencies?
- Faster Application Startup: Fewer dependencies mean there's less load time and quicker startup, which is particularly important in environments where scalability and responsiveness are key.
- Reduced Memory Usage: Each dependency might consume memory, which can add up and affect the overall performance of the application.
- Simpler Maintenance and Upgrades: With fewer packages to manage, the maintenance becomes simpler. It also reduces the risk of conflicts between dependencies and can make the upgrade process smoother.
- Increased Security: Every additional dependency is a potential entry point for security vulnerabilities. By minimizing dependencies, you reduce the attack surface of your application.
Strategies for Dependency Management
1. Evaluate and Prioritize Dependencies
Before integrating an external library, evaluate if it is necessary. For every feature or problem, consider these points:
- Can this functionality be implemented easily without a third-party library?
- Is the dependency well-maintained and widely used, or could it become a liability?
2. Use Lightweight Libraries
Where dependencies are necessary, opt for libraries that are lightweight and focused on performing only what you need them to do.
3. Regularly Review and Update Dependencies
Keep your dependencies up-to-date and periodically review them to ensure they are still needed and that no better alternatives have emerged. Use tools like pip-audit or safety to identify and resolve security vulnerabilities within your dependencies.
4. Virtual Environments
Use virtual environments to isolate your application's dependencies from system-wide Python packages. This helps in managing dependencies in a contained scope, making your application less prone to conflicts with other Python applications running on the same system.
5. Dependency Reduction in Docker Environments
When deploying FastAPI applications using containers, optimizing your Dockerfile can significantly enhance your build times and reduce image size:
# Use official Python slim-buster image
FROM python:3.8-slim-buster
# Set work directory
WORKDIR /app
# Copy only the necessary files
COPY ./requirements.txt /app/
COPY ./main.py /app/
# Install dependencies
RUN pip install --no-cache-dir -r requirements.txt
# Run the application
CMD ["python", "main.py"]
Here, using python:3.8-slim-buster instead of a full-fledged Python image and installing dependencies with --no-cache-dir helps reduce the Docker image size. Additionally, copying only necessary files before running the installation (to leverage Docker cache) prevents unnecessary re-installation of libraries.
Conclusion
Managing and minimizing dependencies not only helps in keeping the application lightweight but also enhances security, simplifies maintenance, and can significantly improve performance. A well-thought-out approach to dependency management will ensure that your FastAPI applications remain efficient, scalable, and easy to maintain.
Response Compression and Caching Techniques
In the high-paced world of web applications, reducing latency and server load is crucial for maintaining a smooth user experience. Using FastAPI, a robust framework for building APIs, implementing response compression and employing caching techniques can drastically enhance your application's performance. This section will delve into how these strategies can be applied to FastAPI applications to achieve more efficient data transfer rates and reduced server load.
Implementing Response Compression with Gzip
Response compression is a technique where the data sent from server to client is compressed, minimizing the size of the response body. This leads to faster transmission speeds and reduced bandwidth usage. In FastAPI, you can facilely incorporate response compression using middleware like GZipMiddleware from Starlette:
from fastapi import FastAPI
from starlette.middleware.gzip import GZipMiddleware
app = FastAPI()
# Add GZip middleware to enable response compression
app.add_middleware(GZipMiddleware, minimum_size=1000)
Here, minimum_size indicates the minimum byte size of the response before GZip compression is applied. This prevents overhead from compressing very small responses. Note that while GZip is quite effective for text data, it may not be beneficial for binary data types or already compressed files such as images or zip files.
Leveraging Caching Strategies
Caching can significantly reduce the load on your application by avoiding repetitive computation or database queries by storing results of requests. FastAPI doesn't come with built-in caching, but you can implement caching using various libraries designed for ASGI applications, such as aiocache.
-
Set Up a Basic Cache with aiocache
A simple example with aiocache shows integrating a cache decorator for a typical API route:
from fastapi import FastAPI
from aiocache import Cache
from aiocache.decorators import cached
from aiocache.serializers import JsonSerializer
app = FastAPI()
cache = Cache(Cache.REDIS, endpoint="127.0.0.1", port=6379, serializer=JsonSerializer())
@app.get("/data")
@cached(key="data_key", ttl=10, cache=cache)
async def get_data():
result = compute_expensive_operation()
return result
def compute_expensive_operation():
# Time-consuming computation or DB queries
return {"data": "Expensive Data"}
In this example, results are cached for 10 seconds under the key data_key. The @cached decorator helps avoid recomputation of the get_data function results within this period, unless invalidated.
-
Cache Configuration Tips
When implementing caching, consider the following to optimize performance:
- Pick the Right TTL (Time to Live): Analyze the nature of your data to set appropriate TTL values. Static data can have longer TTLs, while frequently updated data needs shorter TTLs.
- Invalidate Cache Properly: Ensure proper cache invalidation strategies are in place to avoid outdated information being served.
- Opt for Distributed Caching for Scalability: For scalable applications, consider using a distributed caching solution like Redis, which
aiocache supports.
Conclusion
Applying response compression and caching in your FastAPI application can significantly reduce response times and server load. While compression is readily applied via middleware, choosing an efficient caching strategy requires consideration of your application’s specific data and load characteristics. By implementing these strategies, you can ensure a faster, more scalable API service.
Utilizing Background Tasks
In the world of high-performing web applications, efficiently managing time-consuming tasks without blocking the main application flow is crucial. FastAPI, built on top of Starlette, provides a powerful feature called Background Tasks, which are designed for exactly this purpose. This section delves into how to effectively use background tasks in FastAPI to offload non-critical operations, thereby enhancing the capacity to handle more concurrent API requests.
Overview of Background Tasks
Background tasks in FastAPI allow functions to be executed after a response has been sent to the client. Thus, they are extremely useful for operations such as sending emails, processing data, or carrying out time-intensive logging that you don't want to delay the response times of your main application routes.
Setting Up a Background Task
To utilize a background task within FastAPI, you can import BackgroundTasks from fastapi, and add tasks to it that will run after the response has been sent. Here’s a simple example:
from fastapi import FastAPI, BackgroundTasks
app = FastAPI()
def write_log(message: str):
with open("log.txt", "a") as file:
file.write(message)
@app.post("/send/")
async def send_notification(message: str, background_tasks: BackgroundTasks):
background_tasks.add_task(write_log, message=f"Notification sent: {message}")
return {"message": "Notification sent in the background"}
In the example above, write_log is a function that writes a log message to a file. This function is added to the background tasks using background_tasks.add_task(). The API route returns a response immediately after scheduling this task, thus freeing up the server to handle other requests.
Best Practices for Background Tasks
While background tasks are incredibly useful for improving the responsiveness and scalability of your API, it's important to use them judiciously. Here are some best practices:
- Identify Suitable Tasks: Choose non-critical, time-consuming tasks that do not affect the immediate response to the user.
- Error Handling: Implement robust error handling within your background tasks, as the execution of these tasks does not affect the response, errors could go unnoticed.
- Resource Management: Be aware of the resources that your background tasks use. Too many intensive tasks could impact the overall performance of your server.
Monitoring and Limits
It's essential to monitor the performance and impact of your background tasks. Overutilizing background tasks can lead to server strain and decreased overall performance. Tools like Prometheus and Grafana can be instrumental in monitoring task loads and execution times.
Furthermore, setting practical limits on the number and type of operations executed as background tasks can prevent resource overuse. For instance, if using background tasks for sending emails, consider implementing a queue with rate limiting to avoid overloading mail servers or hitting sending limits.
Conclusion
Properly leveraging background tasks in FastAPI can dramatically increase the efficiency of web applications. By offloading non-critical, long-running processes to the background, you free up API routes to handle more concurrent requests. This not only improves the user experience by decreasing response times but also enhances the overall scalability of the application. When used correctly and monitored effectively, background tasks can be a powerful tool in optimizing your FastAPI applications.
Implementing Effective Logging
Effective logging is a cornerstone of successful application performance monitoring and troubleshooting. In FastAPI applications, the implementation of logging not only helps in understanding the flow and state of applications but also becomes crucial when diagnosing issues and optimizing performance. Given FastAPI's asynchronous nature, adopting asynchronous logging solutions is essential to prevent logging mechanisms from becoming a bottleneck themselves.
Importance of Logging in FastAPI Applications
Logging in FastAPI provides insights into the application's operational state by recording events and data at run time. This information is critical for:
- Debugging: Identify and fix bugs or unexpected behavior observed in production.
- Performance Monitoring: Measure how well different parts of your application perform.
- Security Auditing: Keep track of security events to detect and respond to breaches.
Asynchronous Logging Solutions
Traditional synchronous logging can significantly impact the performance of asynchronous applications by introducing blocking I/O operations. To leverage the full potential of FastAPI's asynchronous capabilities, it's advisable to integrate asynchronous logging libraries.
One popular choice for asynchronous logging in Python is aiologger, which is designed for use with asynchronous applications. aiologger allows for non-blocking logging, ensuring that your application's performance remains unhampered. Here is a simple example of how to set up aiologger in a FastAPI application:
from aiologger import Logger
from fastapi import FastAPI
app = FastAPI()
logger = Logger.with_default_handlers()
@app.get('/')
async def home():
await logger.info("Home page accessed")
return {"message": "Hello World"}
In this setup, aiologger handles log messages asynchronously, ensuring that the API's performance isn't negatively impacted by the logging process.
Log Levels and Granularity
Configuring the appropriate log level is important for effective logging. Here's a quick overview of log levels that you might consider:
- DEBUG: Detailed information, typically of interest only when diagnosing problems.
- INFO: Confirmation that things are working as expected.
- WARNING: An indication that something unexpected happened, or indicative of some problem in the near future.
- ERROR: Due to a more serious problem, the software has not been able to perform some function.
- CRITICAL: A serious error, indicating that the program itself may be unable to continue running.
As a best practice, deploy your application in production with a log level of INFO or higher, and reserve the DEBUG level for troubleshooting in development environments.
Handling Logs
How you handle and store logs is just as crucial as how you generate them. Consider forwarding logs to an external system or service designed for log analysis and monitoring, such as ELK Stack (Elasticsearch, Logstash, Kibana) or Splunk. This approach offers several advantages:
- Scalability: These systems are designed to handle large volumes of data efficiently.
- Searchability: Facilitates expedient searching through large datasets, helping you uncover valuable insights quickly.
- Analysis: Advanced data analysis and visualization tools help identify trends and patterns in log data.
Conclusion
Implementing effective logging in your FastAPI application is essential for operational transparency, performance monitoring, and troubleshooting. By choosing asynchronous logging mechanisms, such as aiologger, you can ensure that logging does not adversely affect the application’s performance. Efficient log management and analysis, enabled by tools like ELK Stack or Splunk, further empower developers and administrators to maintain high-performing and reliable FastAPI applications.
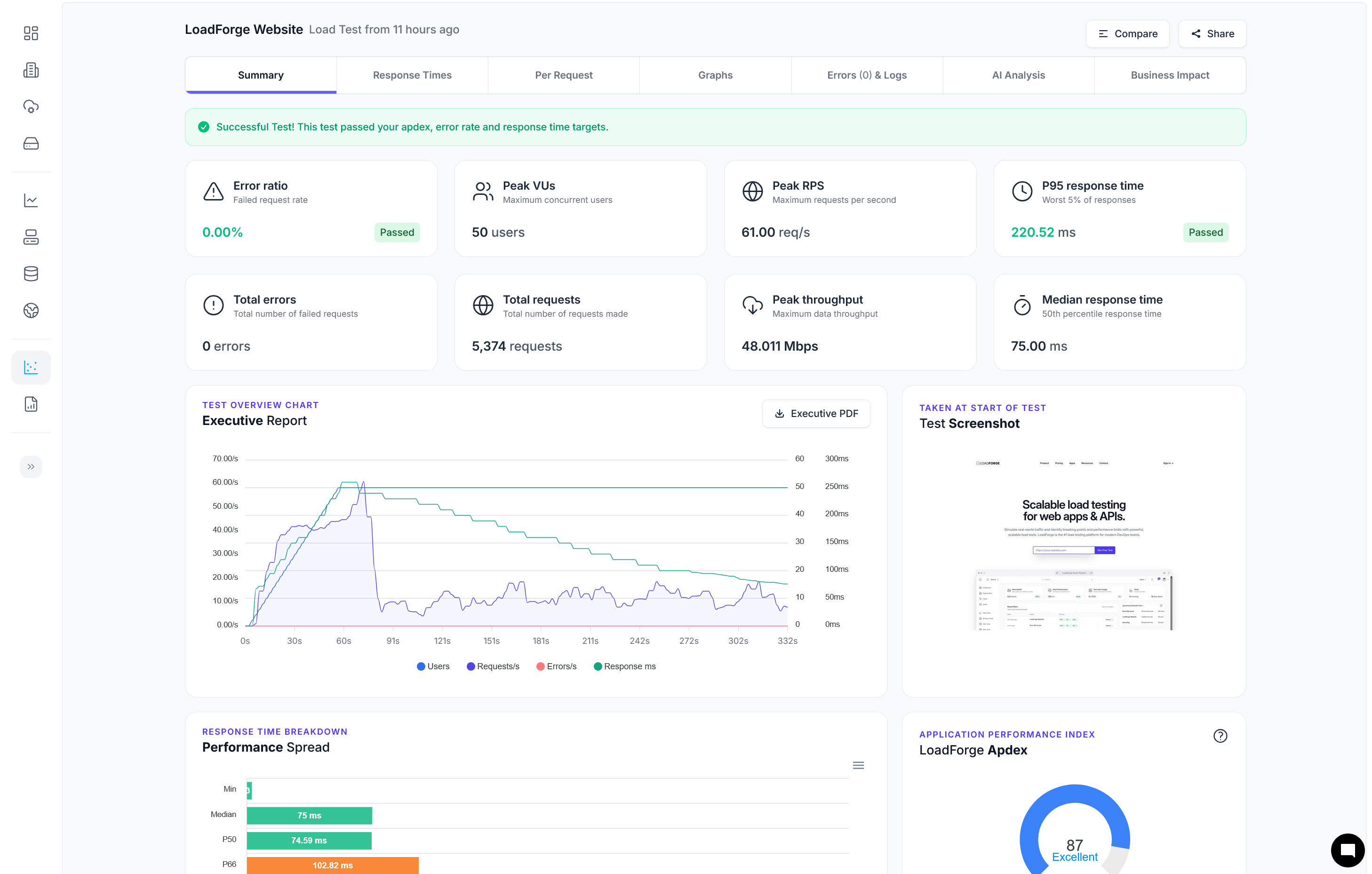
Conducting Load Testing with LoadForge
Load testing is an essential component of performance optimization for any web application, including those built with FastAPI. Utilizing a powerful tool such as LoadForge allows you to simulate high traffic, analyze the application’s responsiveness under stress, and identify any potential scalability issues.
Designing Effective Load Tests
The first step in conducting load tests with LoadForge is designing a test that mimics realistic usage scenarios as closely as possible. Here’s how you can accomplish this:
-
Define User Behavior: Model the actions that the most common users perform on your application. This could range from simple get requests to complex multi-step transactions.
-
Script Creation: Use LoadForge's easy-to-use scripting to define the steps involved in each user interaction. You can write scripts in Python, leveraging the locust.io framework underpinning LoadForge's operations. For example:
from locust import HttpUser, task, between
class QuickstartUser(HttpUser):
wait_time = between(1, 5)
@task
def read_item(self):
self.client.get("/items/1")
@task(3)
def write_item(self):
self.client.post("/items/", json={"name": "item", "description": "This is an item."})
-
Configure Test Parameters: Set the number of concurrent users, spawn rate, and test duration to mirror expected load conditions during peak traffic periods.
Executing Load Tests
Once your script is ready, executing the test is straightforward with LoadForge:
- Upload Your Script: Log into your LoadForge account and upload the script you have prepared.
- Set Up Test Details: Choose the number of users, the spawn rate, and test duration based on your earlier configuration.
- Run the Test: Launch the test from LoadForge’s dashboard. You can monitor the progress in real-time.
Analyzing Test Results
LoadForge provides detailed reports that can help you understand the performance of your FastAPI application under load. Key metrics to consider include:
- Response Times: Average, median, and the 95th percentile of response times, which can help identify latency issues.
- Request Failures: High failure rates may indicate stability or capacity issues under load.
- Resource Usage: Monitoring CPU, memory, and network usage during the test can indicate potential bottlenecks.
Identifying Scalability Issues
The insights gained from LoadForge tests can guide further optimization of your FastAPI application. Pay attention to:
- Performance Bottlenecks: Slow database queries, inefficient code paths, or inadequate asynchronous handling could be culprits.
- Resource Limitations: If hardware resources are consistently maxed out during tests, consider scaling your infrastructure either vertically (upgrading existing resources) or horizontally (adding more servers).
Continuous Improvement
Load testing is not a one-off task but a part of continuous performance improvement. Regular testing with LoadForge, especially after major changes to the application or its environment, ensures that your FastAPI app remains fast and resilient under varying load conditions.
By integrating LoadForge into your development lifecycle, you can continuously analyze and enhance the responsiveness and scalability of your application, ensuring an optimal experience for end users even at peak times.
Fine-tuning with Middleware and FastAPI Configuration
Fine-tuning a FastAPI application involves leveraging middleware and various configuration options to enhance performance, usability, and security. Middleware are functions that run before every request your application receives and can manipulate the request or response objects. In this section, we will explore how to use middleware for tasks like rate limiting and discuss critical configurations that can make your FastAPI app more efficient.
Utilizing Middleware for Rate Limiting
Rate limiting is crucial for protecting your API from overuse and abuse, which can lead to degraded service for all users. FastAPI does not include built-in rate limiting, but you can easily implement it using third-party packages like slowapi, which integrates seamlessly with FastAPI and is based on the more universally recognized limits library.
Here's a simple example of setting up rate limiting using slowapi:
from slowapi import Limiter, _rate_limit_exceeded_handler
from slowapi.errors import RateLimitExceeded
from starlette.requests import Request
from fastapi import FastAPI, Depends
# Create a Limiter instance.
limiter = Limiter(key_func=lambda request: request.client.host)
app = FastAPI()
# Apply a limit to an individual route
@app.get("/limited")
@limiter.limit("5/minute")
async def limited(request: Request):
return "This route is limited to 5 requests per minute."
# Handle exceeded rate limits
app.state.limiter = limiter
app.add_exception_handler(RateLimitExceeded, _rate_limit_exceeded_handler)
Configuration Tweaks for Performance Enhancement
Optimizing your FastAPI configuration can yield significant performance improvements. Consider the following tweaks:
1. Max Workers for Uvicorn
When deploying FastAPI with Uvicorn, the number of worker processes can directly impact performance. More workers can handle more concurrent requests, but this comes at the cost of increased memory usage.
You can specify workers directly when launching Uvicorn:
uvicorn app:app --workers 4
Keep in mind that the optimal number of workers depends on the specific workload and server capacity.
2. Using JSONResponse Options
FastAPI uses JSONResponse from Starlette for sending JSON content. You can modify its behavior, such as ensuring ASCII encoding or changing how JSON is serialized, which can have performance implications:
from fastapi.responses import JSONResponse
from fastapi import FastAPI
app = FastAPI()
@app.get("/customjson")
async def custom_json():
content = {"message": "ASCII encoded JSON"}
return JSONResponse(content=content, ensure_ascii=False)
Disabling ensure_ascii can be advantageous if you are mainly serving non-ASCII content, making responses lighter and faster.
3. Enabling CORSMiddleware
If your FastAPI application is serving requests from different domains, it’s vital to handle Cross-Origin Resource Sharing (CORS) appropriately. However, improperly tuned CORS settings can impact performance due to preflight requests.
from fastapi.middleware.cors import CORSMiddleware
app.add_middleware(
CORSMiddleware,
allow_origins=["https://example.com"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
It’s best to be as specific as possible with allow_origins to not unnecessarily broaden the scope of allowed interactions, thus aligning security practices with performance.
Conclusion
Employing middleware for tasks such as rate limiting, and carefully tweaking FastAPI configuration, can lead to drastically improved performance and efficiency. These changes allow developers to ensure that their applications are not only robust under load but also secure and responsive to the needs of clients.
Deploying and Monitoring for Performance
Deploying a FastAPI application requires careful consideration to ensure that the application not only performs well under the usual conditions but also maintains resilience and responsiveness under high load. This section outlines strategic deployment practices and monitoring tools essential for maximizing your FastAPI application's performance in production environments.
Deployment Strategies
Containerization with Docker
Using Docker for deploying FastAPI applications enhances consistency across different environments and simplifies scalability. A Docker container encapsulates the environment, making it easy to deploy across different staging and production setups without compatibility issues.
Use this basic Dockerfile to containerize your FastAPI application:
FROM python:3.8-slim
WORKDIR /app
COPY . /app
RUN pip install -r requirements.txt
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "80"]
Kubernetes for Orchestration
For applications expecting significant traffic, Kubernetes helps manage containerized applications with auto-scaling, load balancing, and self-healing features.
Deploy your application on Kubernetes using a deployment configuration like this:
apiVersion: apps/v1
kind: Deployment
metadata:
name: fastapi-app
spec:
replicas: 3
selector:
matchLabels:
app: fastapi
template:
metadata:
labels:
app: fastapi
spec:
containers:
- name: fastapi
image: fastapi-app-image
ports:
- containerPort: 80
Continuous Integration and Continuous Deployment (CI/CD)
Automate your deployment process with CI/CD pipelines. This approach reduces human error, ensures consistent releases, and integrates seamlessly with testing for always-deployable applications.
Monitoring Tools for Performance
Monitoring is crucial to observe your application's operational performance and to pinpoint areas that require optimization.
Prometheus and Grafana
Prometheus offers powerful real-time monitoring and Grafana for visualization. Set up Prometheus to scrape your FastAPI metrics and use Grafana to create dashboards that provide insights into requests per second, response times, and system health.
Example Prometheus configuration to scrape metrics:
scrape_configs:
- job_name: 'fastapi'
static_configs:
- targets: ['<fastapi-host>:80']
Elastic Stack
The Elastic Stack (Elasticsearch, Logstash, and Kibana) is ideal for processing, monitoring, and visualizing logs. Use this stack to analyze logs generated by FastAPI applications for troubleshooting and gaining performance insights.
Sentry for Error Tracking
Utilize Sentry to track real-time errors. It helps you discover, triage, and prioritize errors in a real-world setting.
Best Practices for Performance Monitoring
- Set Realistic Thresholds: Establish performance benchmarks and thresholds that match real-world usage patterns.
- Monitor Dependencies: Keep an eye on external services and third-party dependencies, as their performance impacts your application.
- Perform Regular Audits: Continuously assess the application's performance and infrastructure to adjust resources and settings as needed.
- Log Strategically: Avoid verbose logging in production but ensure critical information is logged for diagnosing issues.
- Proactive Alerts: Set up alerts for anomalies in performance metrics to respond before they impact users.
Implementing these deployment and monitoring strategies ensures that your FastAPI application remains robust, scalable, and performant in production environments. Regular analysis and optimization based on feedback from monitoring tools also facilitate ongoing improvements to system performance.