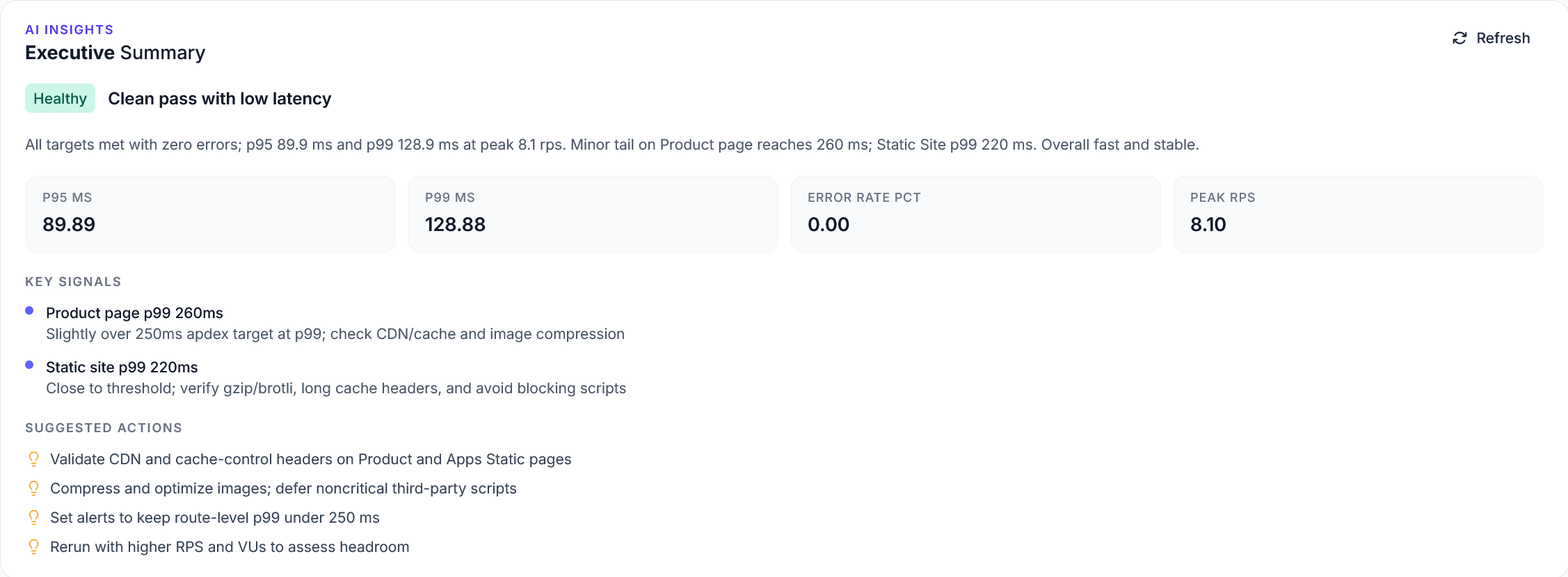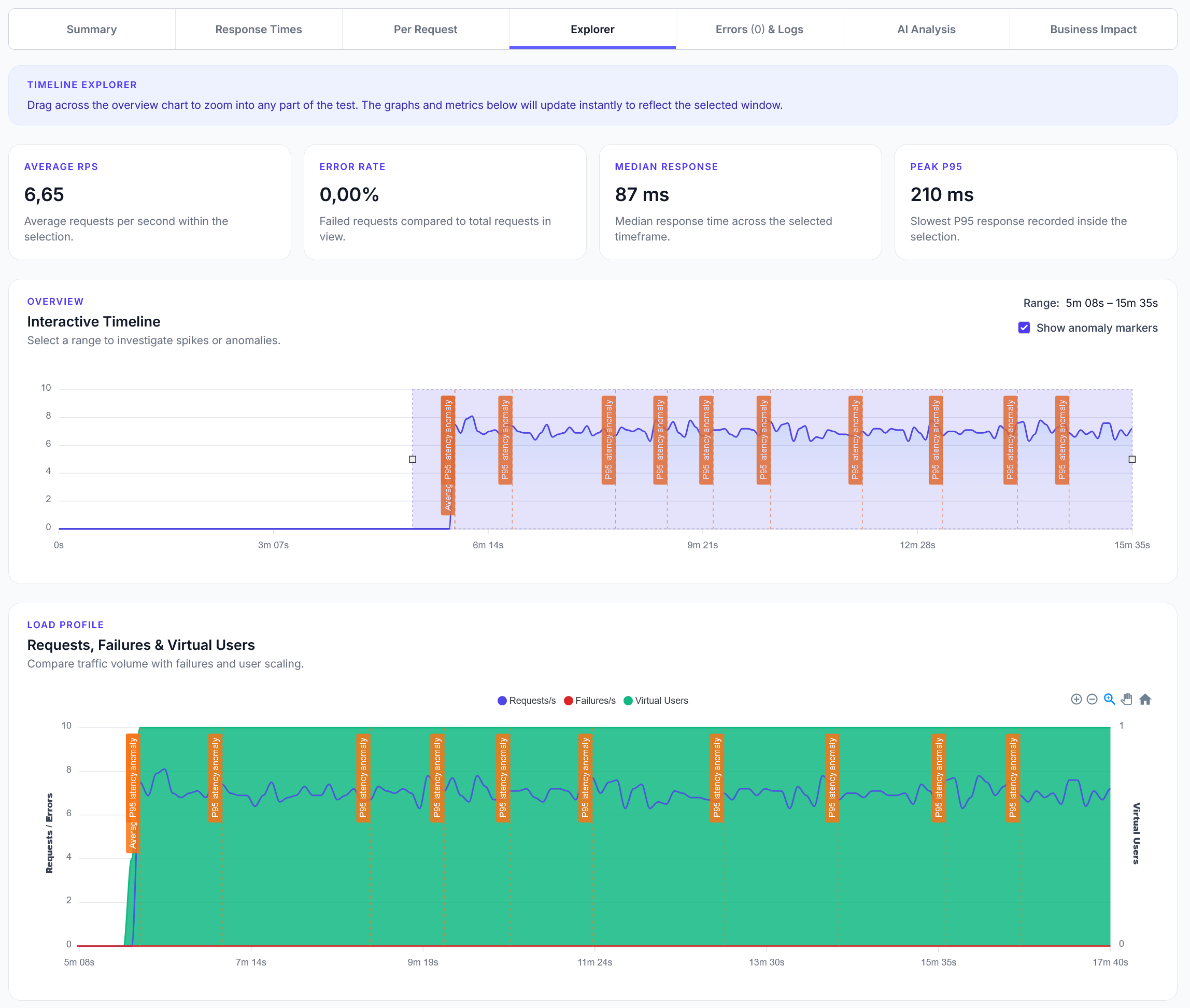
Explorer reports addition
We have added a new Explorer feature to reports, with a timeline scrubber and easy anomaly detection.
Simple load testing to compare response times and quality across OpenAI, Claude, and Gemini APIs
LoadForge can record your browser, graphically build tests, scan your site with a wizard and more. Sign up now to run your first test.
This guide shows how to compare AI API performance across different providers. Perfect for testing response times, reliability, and choosing the best AI provider for your needs.
from locust import task, HttpUser
import json
import random
import time
class AIComparisonUser(HttpUser):
def on_start(self):
# API configurations
self.openai_key = "your-openai-api-key"
self.claude_key = "your-claude-api-key"
self.gemini_key = "your-gemini-api-key"
# Test prompts for comparison
self.test_prompts = [
"Write a short product description for a wireless headphone.",
"Explain quantum computing in simple terms.",
"Create a brief email response thanking a customer.",
"Summarize the benefits of renewable energy.",
"Write a creative story opening in 2 sentences."
]
@task(2)
def test_openai_gpt35(self):
"""Test OpenAI GPT-3.5 Turbo"""
prompt = random.choice(self.test_prompts)
headers = {
"Authorization": f"Bearer {self.openai_key}",
"Content-Type": "application/json"
}
payload = {
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": prompt}],
"max_tokens": 150,
"temperature": 0.7
}
start_time = time.time()
with self.client.post(
"https://api.openai.com/v1/chat/completions",
json=payload,
headers=headers,
name="OpenAI GPT-3.5"
) as response:
response_time = (time.time() - start_time) * 1000
if response.status_code == 200:
data = response.json()
if "choices" in data and data["choices"]:
content = data["choices"][0]["message"]["content"]
tokens = data.get("usage", {}).get("total_tokens", 0)
print(f"OpenAI: {len(content)} chars, {tokens} tokens, {response_time:.0f}ms")
else:
response.failure("No choices in OpenAI response")
elif response.status_code == 429:
response.failure("OpenAI rate limit exceeded")
else:
response.failure(f"OpenAI error: {response.status_code}")
@task(2)
def test_claude(self):
"""Test Anthropic Claude"""
prompt = random.choice(self.test_prompts)
headers = {
"x-api-key": self.claude_key,
"Content-Type": "application/json",
"anthropic-version": "2023-06-01"
}
payload = {
"model": "claude-3-haiku-20240307",
"max_tokens": 150,
"messages": [{"role": "user", "content": prompt}]
}
start_time = time.time()
with self.client.post(
"https://api.anthropic.com/v1/messages",
json=payload,
headers=headers,
name="Claude Haiku"
) as response:
response_time = (time.time() - start_time) * 1000
if response.status_code == 200:
data = response.json()
if "content" in data and data["content"]:
content = data["content"][0]["text"]
tokens = data.get("usage", {}).get("input_tokens", 0) + data.get("usage", {}).get("output_tokens", 0)
print(f"Claude: {len(content)} chars, {tokens} tokens, {response_time:.0f}ms")
else:
response.failure("No content in Claude response")
elif response.status_code == 429:
response.failure("Claude rate limit exceeded")
else:
response.failure(f"Claude error: {response.status_code}")
@task(2)
def test_gemini(self):
"""Test Google Gemini"""
prompt = random.choice(self.test_prompts)
params = {"key": self.gemini_key}
payload = {
"contents": [{"parts": [{"text": prompt}]}],
"generationConfig": {
"maxOutputTokens": 150,
"temperature": 0.7
}
}
start_time = time.time()
with self.client.post(
"https://generativelanguage.googleapis.com/v1beta/models/gemini-pro:generateContent",
json=payload,
params=params,
name="Gemini Pro"
) as response:
response_time = (time.time() - start_time) * 1000
if response.status_code == 200:
data = response.json()
if "candidates" in data and data["candidates"]:
content = data["candidates"][0]["content"]["parts"][0]["text"]
# Gemini doesn't return token count in basic API
print(f"Gemini: {len(content)} chars, {response_time:.0f}ms")
else:
response.failure("No candidates in Gemini response")
elif response.status_code == 429:
response.failure("Gemini rate limit exceeded")
else:
response.failure(f"Gemini error: {response.status_code}")
@task(1)
def test_openai_gpt4(self):
"""Test OpenAI GPT-4 (if available)"""
prompt = random.choice(self.test_prompts)
headers = {
"Authorization": f"Bearer {self.openai_key}",
"Content-Type": "application/json"
}
payload = {
"model": "gpt-4",
"messages": [{"role": "user", "content": prompt}],
"max_tokens": 150,
"temperature": 0.7
}
start_time = time.time()
with self.client.post(
"https://api.openai.com/v1/chat/completions",
json=payload,
headers=headers,
name="OpenAI GPT-4"
) as response:
response_time = (time.time() - start_time) * 1000
if response.status_code == 200:
data = response.json()
if "choices" in data and data["choices"]:
content = data["choices"][0]["message"]["content"]
tokens = data.get("usage", {}).get("total_tokens", 0)
print(f"GPT-4: {len(content)} chars, {tokens} tokens, {response_time:.0f}ms")
elif response.status_code == 429:
response.failure("GPT-4 rate limit exceeded")
elif response.status_code == 404:
response.failure("GPT-4 not available (need API access)")
else:
response.failure(f"GPT-4 error: {response.status_code}")
Get API keys from each provider:
Replace the API key placeholders with your actual keys
Start with low user counts to avoid hitting rate limits
Typical results you might see: