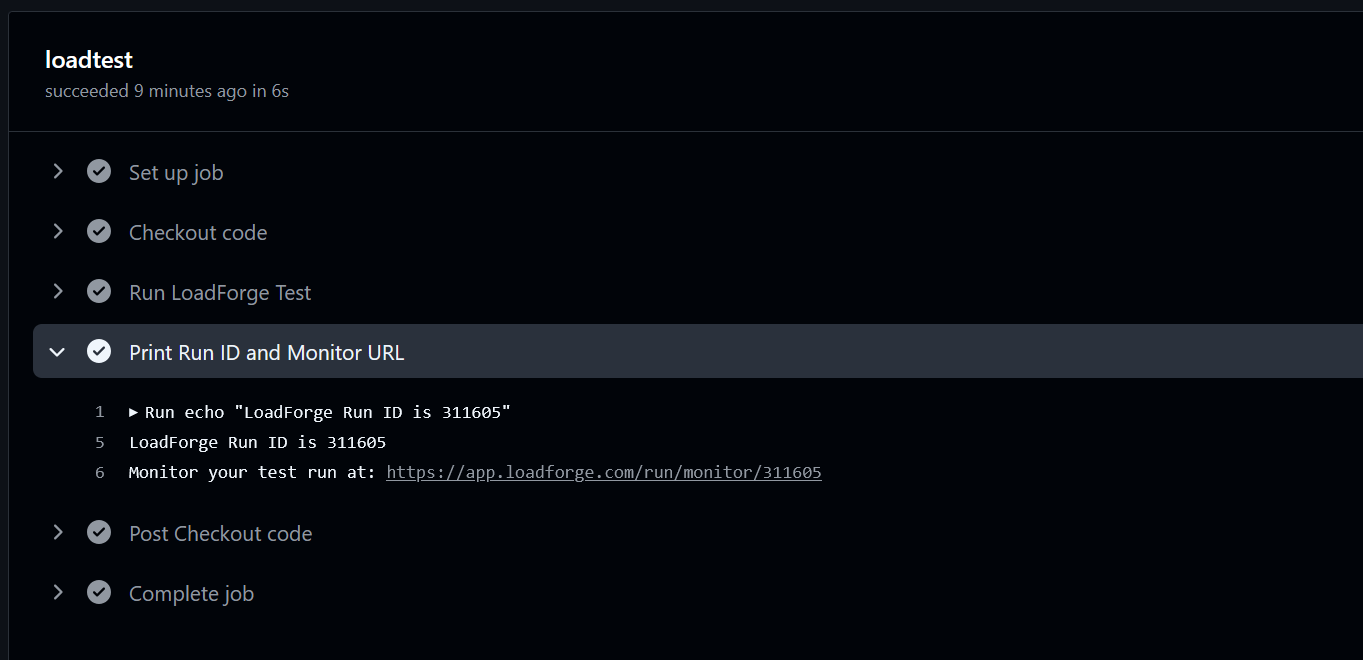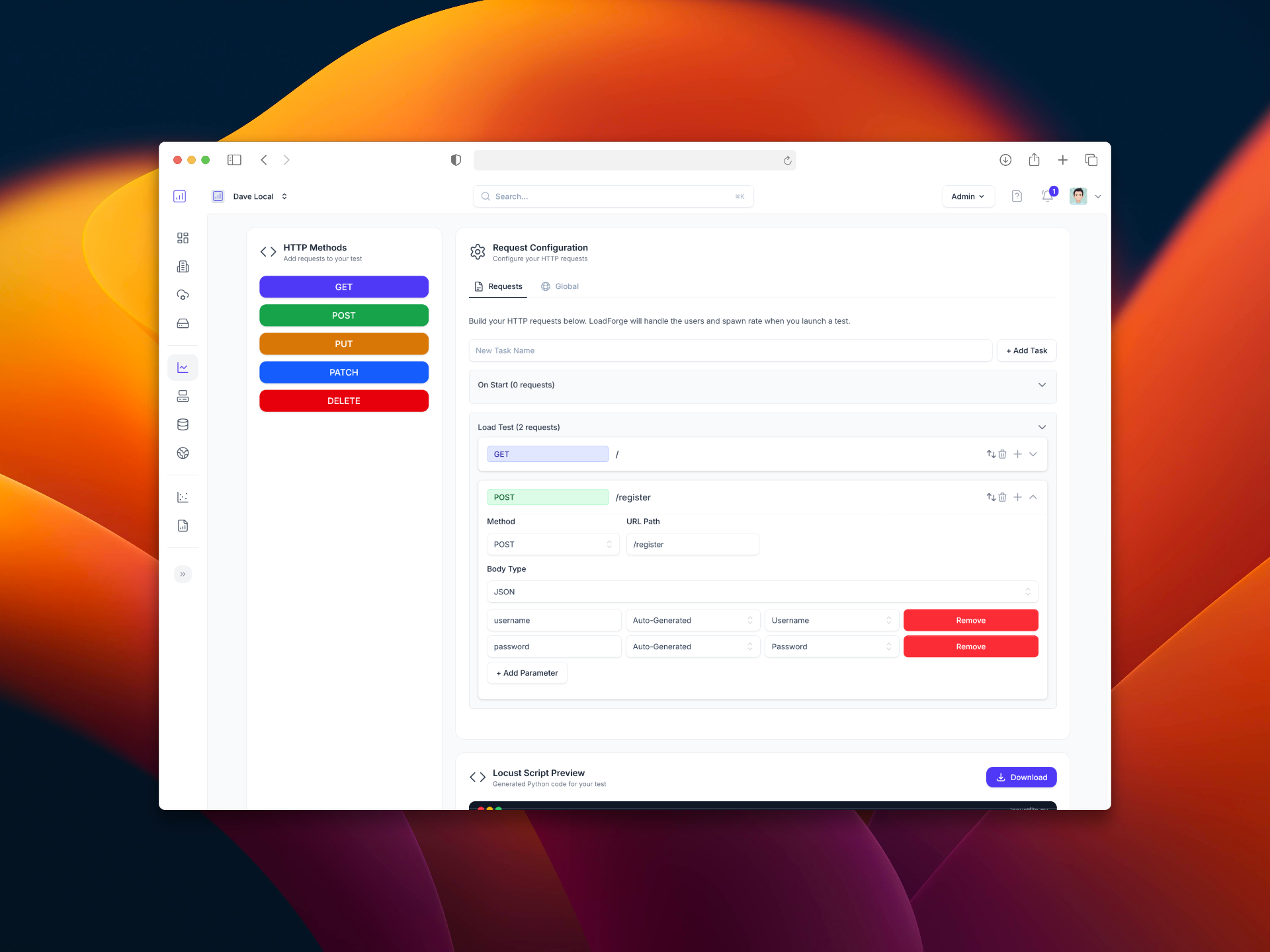
Jira Integration & Graphical Test Builder
We are proud to announce the release of two new features, available immediately. 🚀 Jira Integration: Automate Issue Tracking for...
In the world of database management, ensuring optimal performance is a top priority, and one of the fundamental ways to achieve this is through efficient index design. Indexes in Microsoft SQL Server (MSSQL) are critical components that significantly influence query...

In the world of database management, ensuring optimal performance is a top priority, and one of the fundamental ways to achieve this is through efficient index design. Indexes in Microsoft SQL Server (MSSQL) are critical components that significantly influence query performance and overall database efficiency. This guide aims to dive deep into the best practices of index design, providing insights and practical advice to enhance your MSSQL performance.
Indexes work as look-up tables that the database search engine can use to speed up data retrieval. Without proper indexing, querying large datasets can become slow and resource-intensive, leading to performance bottlenecks and dissatisfied users.
Indexes in MSSQL can be visualized as data structures that point to the location of data in your tables. The most commonly used types are:
A simple example of creating a non-clustered index in MSSQL might look like the following:
CREATE NONCLUSTERED INDEX IX_ProductName
ON Products (ProductName);
In this example, ProductName in the Products table is indexed to speed up searches involving ProductName.
In summary, optimizing index design is crucial for any MSSQL database aiming for high performance and efficiency. The following sections of this guide will dive deeper into the types of indexes, how to select the right indexes, and maintenance practices, all aimed at helping you master the art of index optimization in MSSQL. The journey begins with understanding the fundamental concepts of indexing, discussed comprehensively in the next section.
By ensuring your indexes are well-designed and maintained, you position your MSSQL databases for superior performance, scalability, and reliability. Let's embark on this optimization journey together!
Indexes play a pivotal role in database performance, functioning as critical components that accelerate data retrieval processes. An index in MSSQL is essentially a data structure that enables the SQL Server to quickly locate and access the rows within a table based on the values of one or more columns. This section aims to delve into the mechanics of indexes, their different types, and their fundamental roles within MSSQL.
In the simplest terms, an index is like an index in a book—it helps you find information faster without having to scan through every page. In an MSSQL database, an index serves a similar purpose by providing pointers to the rows in a table where the data resides. When you query a database, the SQL Server can use these indexes to speed up data retrieval, making your queries far more efficient.
Indexes work by creating an internal data structure, typically a type of balanced tree (B-tree), which efficiently narrows down the data that needs to be scanned. When a query is executed, SQL Server can navigate through this tree structure to find the required rows with minimal effort.
For instance, consider a table Employees with the columns EmployeeID, FirstName, LastName, and DepartmentID. If you frequently query this table by LastName, creating an index on the LastName column can significantly speed up these queries.
A clustered index determines the physical order of data in a table. Think of it as the primary mechanism for storing table data. Unlike other indexes, a table can have only one clustered index because the data rows themselves can be stored in only one order.
CREATE CLUSTERED INDEX IX_Employees_LastName
ON Employees (LastName);
Non-clustered indexes, on the other hand, create a separate structure within the database that includes a reference to the original data. They can be used to improve the performance of queries that do not necessarily align with the clustered index.
CREATE NONCLUSTERED INDEX IX_Employees_DepartmentID
ON Employees (DepartmentID);
Unique indexes ensure that the values in the indexed columns are unique, preventing duplicate entries. These can be crucial for maintaining data integrity.
CREATE UNIQUE INDEX IX_Employees_EmployeeID
ON Employees (EmployeeID);
Filtered indexes apply a filter or condition to the index, making them smaller and less costly to maintain. They are particularly useful for indexing subsets of data.
CREATE NONCLUSTERED INDEX IX_Employees_Active
ON Employees (DepartmentID)
WHERE Active = 1;
Full-text indexes are specialized indexes used for full-text search queries. They allow for efficient searching of textual data by indexing words and phrases within the text.
CREATE FULLTEXT INDEX ON Employees(LastName)
KEY INDEX PK_Employees;
Understanding the various types of indexes available in MSSQL and their respective use-cases is fundamental to optimizing database performance. Each index type serves a unique purpose and can be leveraged to improve read and write operations, ensuring that your queries run efficiently and your data remains easily accessible. Moving forward, we will explore how to choose the right indexes and further optimize their design for your specific needs.
Selecting the right indexes for your MSSQL tables is a pivotal step in optimizing database performance. Proper indexing can significantly reduce query response times, ensuring the efficient retrieval and manipulation of data. This section provides guidelines and best practices on analyzing query patterns, balancing read vs. write performance, and considering storage implications to help you make informed decisions on index selection.
Understanding your query patterns is the first step in choosing the right indexes. Pay close attention to the types of queries most often run against your database. This can include:
WHERE, JOIN, ORDER BY, and GROUP BY clauses?Begin by examining the execution plans for these queries. SQL Server Management Studio (SSMS) provides tools for capturing and analyzing execution plans, which show how SQL Server executes queries and which indexes are used or might be beneficial.
To see execution plans, you can use:
SET STATISTICS PROFILE ON;
SELECT * FROM Orders WHERE CustomerID = 1;
SET STATISTICS PROFILE OFF;
Indexes can drastically speed up read operations (e.g., SELECT queries) but can also negatively impact write operations (e.g., INSERT, UPDATE, DELETE) because the indexes must be maintained. Here’s how you can balance the needs:
Read-intensive Workloads: Focus on creating indexes that cover the columns frequently accessed in read queries. Use covering indexes (discussed later) to include all columns needed by a query to avoid table scans.
Write-intensive Workloads: Minimize the number of indexes to reduce the overhead on write operations. Avoid creating too many non-clustered indexes on tables heavily involved in writes.
While indexes accelerate query performance, they consume additional storage space. The goal is to strike a balance between performance improvement and additional storage use:
Clustered Indexes: These define the physical storage order of data in the table and can only be one per table. They are efficient for range-based queries and generally should be created on columns that are often used for sorting or range queries.
Non-clustered Indexes: These store a sorted copy of the specified columns and a pointer back to the actual data. They are useful for exact match queries.
Evaluate the size of the columns you are indexing and the selectivity (i.e., the uniqueness of the column values). High selectivity columns often make good candidates for indexing.
Consider the storage impact with a table schema as follows:
CREATE TABLE Sales (
SalesID int PRIMARY KEY,
Date datetime,
CustomerID int,
Amount decimal(10, 2)
);
-- Adding a non-clustered index on CustomerID
CREATE INDEX idx_customerID ON Sales(CustomerID);
If CustomerID has high selectivity and is frequently used in query filters, the performance gains from this index can outweigh the storage costs.
Here are some practical guidelines to keep in mind when selecting the right indexes:
WHERE clause, JOIN clause, and ON conditions.By following these guidelines, you can ensure that your indexing strategy is aligned with your database’s workload characteristics and performance requirements.
Selecting the right columns to index is crucial for optimizing query performance in MSSQL. Properly chosen indexes can dramatically improve the speed and efficiency of data retrieval, while poorly chosen indexes can waste resources and degrade performance. Here are some best practices to guide you in selecting indexed columns effectively.
High Selectivity: Index columns that have high selectivity, meaning the column values are unique or close to unique. The more selective a column is, the more effectively an index can narrow down search results. For example, a column storing unique identifiers (like user IDs) is highly selective and is a prime candidate for indexing.
Filtering and Sorting: Columns frequently used in WHERE, JOIN, ORDER BY, and GROUP BY clauses are essential candidates for indexing. Indexes on these columns ensure that the database engine can quickly locate and sort the necessary data.
Combining Columns: Sometimes, it’s beneficial to create indexes that combine multiple columns. Evaluating query patterns helps determine the best combination of columns to index.
Smaller is Better: Smaller columns are more efficient to index because they require less storage and memory, and they allow the database engine to process queries faster. For example, a smaller integer column is preferable over a larger varchar column.
Data Types and Length: Use appropriate data types and lengths for indexed columns. Avoid unnecessary long data types. For instance, if a column only needs to store dates, use the DATE data type instead of DATETIME.
Index Overhead: Every index consumes disk space and memory and adds overhead to INSERT, UPDATE, and DELETE operations. Therefore, it's imperative to balance the benefits of indexing with the potential performance costs. Analyze your workload to maintain the right balance.
Duplicate Indexes: Avoid creating redundant indexes. Multiple indexes on the same columns in different orders can be replaced with a single, well-chosen composite or covering index.
Regular Reviews: Frequently review and purge unused indexes. MSSQL provides Dynamic Management Views (DMVs) that allow you to monitor index usage and identify rarely used indexes.
Consider a table Sales with the following structure:
CREATE TABLE Sales (
SaleID INT PRIMARY KEY,
ProductID INT,
OrderDate DATE,
Quantity INT,
TotalAmount DECIMAL(10, 2)
);
High selectivity columns like SaleID are already a primary key, implicitly creating a highly efficient clustered index. However, suppose queries often filter by OrderDate and ProductID. Indexing these columns greatly improves query performance:
CREATE INDEX idx_OrderDate ON Sales (OrderDate);
CREATE INDEX idx_ProductID ON Sales (ProductID);
If combined filtering on ProductID and OrderDate is common, a composite index might be more effective:
CREATE INDEX idx_ProductOrderDate ON Sales (ProductID, OrderDate);
This composite index benefits queries that filter by both ProductID and OrderDate together.
Proper indexed column selection involves understanding your data and query patterns, focusing on high selectivity columns, minimizing the impact of column size, and avoiding over-indexing pitfalls. Regularly reviewing and maintaining your index strategy ensures optimal database performance, supported by a well-balanced and lean set of indexes. This strategic approach is vital for running efficient queries while preserving the overall health and performance of your MSSQL database.
## Composite Indexes
Composite indexes are powerful tools in MSSQL that allow you to optimize the performance of queries involving multiple columns. By creating an index on more than one column, a composite index can provide significant performance improvements, especially for complex queries. In this section, we'll delve into when to use composite indexes, how to create them, and strategies for ordering columns within a composite index to achieve optimal performance.
### When to Use Composite Indexes
Composite indexes are particularly beneficial in the following scenarios:
1. **Multi-Column Query Conditions**: When your queries frequently filter, sort, or join on multiple columns, a composite index can significantly enhance performance. For example:
```sql
SELECT *
FROM Orders
WHERE CustomerID = 1234 AND OrderDate = '2022-12-12';
```
2. **Compound Key Joins**: When tables are joined on multiple columns, composite indexes help speed up the join operations:
```sql
SELECT a.OrderID, b.ProductID
FROM Orders a
JOIN OrderDetails b
ON a.OrderID = b.OrderID AND a.CustomerID = b.CustomerID;
```
3. **High Cardinality Columns Combination**: For columns with high cardinality (i.e., columns with a large number of unique values), composite indexes can improve query performance substantially.
### Creating Composite Indexes
Creating a composite index in MSSQL is straightforward. Here's the syntax for creating a composite index on the `Orders` table that includes the `CustomerID` and `OrderDate` columns:
```sql
CREATE INDEX idx_customer_orderdate ON Orders (CustomerID, OrderDate);
The order of columns in a composite index is crucial and can greatly affect query performance. Here are some guidelines for determining the order of columns:
Equality Columns First: Place columns that are used with the equality operator (=) before those used with range operators (e.g., <, >, BETWEEN, and LIKE). This maximizes the use of the index for lookups.
-- Optimal order for filtering by CustomerID and then OrderDate
CREATE INDEX idx_customer_orderdate ON Orders (CustomerID, OrderDate);
Column Selectivity: Higher selectivity columns (columns with more unique values) should come first in the composite index. This helps narrow down the result set more efficiently.
Query Usage Patterns: Analyze the query patterns to identify the most frequent columns used together in filters or joins.
-- If queries often filter by CustomerID and OrderDate, this index order is optimal
CREATE INDEX idx_customer_orderdate ON Orders (CustomerID, OrderDate);
Covering Indexes: If possible, include additional columns in the composite index to make it a covering index for specific queries. This minimizes the need to access the actual table data, as all required columns are included in the index.
-- Index covering the query without going back to the table
CREATE INDEX idx_customer_orderdate_covering ON Orders (CustomerID, OrderDate, Status);
Consider the following example where we have a table named Sales:
CREATE TABLE Sales (
SaleID INT PRIMARY KEY,
ProductID INT,
SaleDate DATE,
Quantity INT,
SalePrice DECIMAL(10,2)
);
To optimize queries that filter by ProductID and SaleDate, we would create a composite index:
CREATE INDEX idx_product_saledate ON Sales (ProductID, SaleDate);
This index will optimize queries such as:
SELECT *
FROM Sales
WHERE ProductID = 1001 AND SaleDate BETWEEN '2022-01-01' AND '2022-12-31';
Composite indexes are vital for improving MSSQL performance for queries involving multiple columns. By carefully selecting and ordering columns within composite indexes, you can significantly enhance query performance, reduce execution time, and improve overall database efficiency. In the next sections, we'll explore covering indexes and strategies for maintaining and monitoring these indexes to ensure ongoing performance gains.
Covering indexes are a powerful feature in MSSQL that can significantly enhance query performance. A covering index is an index that includes all the columns a query needs, meaning the query can be satisfied entirely using the index without having to access the base table. This section will delve into the concept of covering indexes, outline their benefits, explain how to create them, and provide practical examples illustrating their impact on query performance.
A covering index is an index that contains all the columns required by a specific query. This complete coverage allows the query optimizer to retrieve data directly from the index, bypassing the need to scan the base table. This not only speeds up query execution but also reduces I/O operations, leading to improved overall performance.
To create a covering index, you need to ensure that the index includes all the columns required by your query. This can be achieved using the INCLUDE clause to add non-key columns to a non-clustered index.
Here is a basic example:
CREATE INDEX idx_covering_example
ON Orders (CustomerID, OrderDate)
INCLUDE (OrderID, ShipCity);
In this example, the index idx_covering_example covers queries that need CustomerID and OrderDate as key columns and OrderID and ShipCity as additional data.
Consider the following SELECT query:
SELECT CustomerID, OrderDate, OrderID, ShipCity
FROM Orders
WHERE CustomerID = @CustomerID
ORDER BY OrderDate;
With the covering index idx_covering_example, this query can be executed efficiently, as all columns are included in the index.
Let's walk through a practical example where using a covering index makes a noticeable difference.
SELECT ProductID, ProductName, Price
FROM Products
WHERE CategoryID = @CategoryID
ORDER BY Price DESC;
Without a covering index, this query would necessitate multiple accesses to the base table to retrieve ProductName and Price. To optimize, we create a covering index:
CREATE INDEX idx_covering_products
ON Products (CategoryID, Price)
INCLUDE (ProductID, ProductName);
Now, when the same query is executed:
SELECT ProductID, ProductName, Price
FROM Products
WHERE CategoryID = @CategoryID
ORDER BY Price DESC;
The query optimizer can use idx_covering_products to retrieve all necessary columns directly from the index, significantly improving the query performance.
Covering indexes are a valuable tool in the MSSQL performance optimization toolkit. By including all columns a query needs, covering indexes allow for faster query execution and reduced resource usage. Properly designed covering indexes can make a significant difference in the efficiency of your database operations.
Regular index maintenance is vital for ensuring consistent database performance in MSSQL. Over time, indexes can become fragmented due to the frequent insert, update, and delete operations. Fragmentation can lead to inefficient query performance and increased I/O operations, making it imperative to rebuild and reorganize indexes periodically. This section delves into the importance of index maintenance, the differences between rebuilding and reorganizing indexes, and how to automate these tasks effectively.
Indexes are essential for query performance, but without regular maintenance, they can degrade, leading to:
Index maintenance helps by reclaiming space, reorganizing pages, and optimizing index structure to ensure that queries run efficiently.
MSSQL provides two primary methods for maintaining indexes: rebuilding and reorganizing. Each method serves a different purpose and is suitable under different circumstances.
Rebuilding Indexes:
-- Example of rebuilding an index
ALTER INDEX [IndexName] ON [Schema].[TableName] REBUILD;
Reorganizing Indexes:
-- Example of reorganizing an index
ALTER INDEX [IndexName] ON [Schema].[TableName] REORGANIZE;
To ensure your database remains performant, it's crucial to automate index maintenance tasks. This can be achieved using maintenance plans or custom scripts that regularly check for fragmentation and perform the necessary actions.
MSSQL Management Studio offers built-in maintenance plans to automate index maintenance. These plans can be scheduled to run during off-peak hours to minimize the impact on production workloads.
Index Rebuild Task or Index Reorganize Task.For more control and flexibility, custom scripts can be developed and scheduled via SQL Server Agent. Below is an example script that rebuilds or reorganizes indexes based on their fragmentation level.
USE [YourDatabaseName];
GO
DECLARE @index_id int, @object_id int, @partition_number int, @frag float, @sql nvarchar(max);
DECLARE db_cursor CURSOR FOR
SELECT
object_id,
index_id,
partition_number,
avg_fragmentation_in_percent
FROM
sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, 'LIMITED')
WHERE
avg_fragmentation_in_percent > 5;
OPEN db_cursor;
FETCH NEXT FROM db_cursor INTO @object_id, @index_id, @partition_number, @frag;
WHILE @@FETCH_STATUS = 0
BEGIN
SET @sql = NULL;
IF @frag < 30
SET @sql = N'ALTER INDEX ' + QUOTENAME(i.name) + ' ON ' + QUOTENAME(SCHEMA_NAME(o.schema_id)) + '.' + QUOTENAME(OBJECT_NAME(i.object_id)) + ' REORGANIZE;';
ELSE
SET @sql = N'ALTER INDEX ' + QUOTENAME(i.name) + ' ON ' + QUOTENAME(SCHEMA_NAME(o.schema_id)) + '.' + QUOTENAME(OBJECT_NAME(i.object_id)) + ' REBUILD;';
EXEC sp_executesql @sql;
FETCH NEXT FROM db_cursor INTO @object_id, @index_id, @partition_number, @frag;
END
CLOSE db_cursor;
DEALLOCATE db_cursor;
By utilizing automated maintenance plans or custom scripts, you can ensure your MSSQL indexes remain optimized, thereby maintaining peak database performance. Regular index maintenance mitigates performance degradation and ensures that your queries run smoothly, even as your database evolves.
Monitoring and analyzing index usage is crucial for ensuring that your index design is optimized for peak performance. In this section, we will explore various tools and techniques available in MSSQL for evaluating the effectiveness of your indexes, identifying missing indexes, and making informed decisions for further optimization.
Dynamic Management Views (DMVs) are powerful tools in MSSQL that provide insights into the internal workings of your database. Specifically, certain DMVs give detailed information about index usage and can help identify underperforming or unused indexes.
One of the most useful DMVs for monitoring index usage is sys.dm_db_index_usage_stats. This view provides statistics about how indexes are being accessed, including information about seeks, scans, lookups, and updates.
The following query retrieves the use statistics for all indexes in your database:
SELECT
DB_NAME(database_id) AS database_name,
OBJECT_NAME(object_id) AS table_name,
index_id,
name AS index_name,
user_seeks,
user_scans,
user_lookups,
user_updates
FROM
sys.dm_db_index_usage_stats AS ius
JOIN sys.indexes AS ix ON ix.object_id = ius.object_id AND ix.index_id = ius.index_id
WHERE
database_id = DB_ID()
ORDER BY
user_seeks DESC, user_scans DESC;
MSSQL also provides DMVs to help identify missing indexes that could potentially improve query performance. The sys.dm_db_missing_index_details DMV provides information about missing indexes based on the queries executed.
Use the following query to get details about missing indexes:
SELECT
mid.statement AS table_name,
migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans) AS improvement_measure,
mid.equality_columns,
mid.inequality_columns,
mid.included_columns
FROM
sys.dm_db_missing_index_groups AS mig
JOIN sys.dm_db_missing_index_group_stats AS migs ON mig.index_group_handle = migs.group_handle
JOIN sys.dm_db_missing_index_details AS mid ON mid.index_handle = mig.index_handle
ORDER BY
improvement_measure DESC;
The Database Tuning Advisor (DTA) is an integrated tool within MSSQL that analyzes your database's workload and recommends indexes that should be created, modified, or dropped. It is particularly useful for identifying indexes you might have missed or for tuning index designs based on actual usage patterns.
To use the DTA, you need to capture a workload file using SQL Server Profiler and then run the DTA on this file to get index recommendations.
Introduced in SQL Server 2016, Query Store provides a rich set of features for monitoring index usage. It captures a history of queries, plans, and runtime statistics, making it easier to analyze query performance over time and identify which indexes are being used efficiently.
To enable Query Store, you can run the following T-SQL command:
ALTER DATABASE YourDatabaseName
SET QUERY_STORE = ON;
Once Query Store is enabled, you can use the SQL Server Management Studio (SSMS) interface to visualize and analyze index usage statistics.
When analyzing index effectiveness, consider the following factors:
By leveraging the power of DMVs and built-in MSSQL tools like the Database Tuning Advisor and Query Store, you can effectively monitor and analyze index usage in your database. Regular analysis helps you make data-driven decisions for optimizing index design, leading to improved database performance and resource utilization.
Index fragmentation is an inevitable issue that arises over time as data in your MSSQL database is inserted, updated, and deleted. It can severely impact the performance of your queries by causing increased I/O operations and slower data retrieval times. Addressing fragmentation ensures that your indexes remain efficient and your queries perform optimally.
Index fragmentation occurs when the logical order of pages in an index no longer matches the physical order on the disk. There are two main types of fragmentation:
Fragmentation can lead to:
You can use the Dynamic Management Views (DMVs) to identify the fragmentation levels of your indexes. The following query evaluates fragmentation:
SQL
SELECT
DB_NAME() AS DatabaseName,
OBJECT_NAME(ips.object_id) AS TableName,
i.name AS IndexName,
ips.index_id,
ips.avg_fragmentation_in_percent,
ips.page_count
FROM
sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, 'DETAILED') AS ips
JOIN
sys.indexes AS i
ON ips.object_id = i.object_id
AND ips.index_id = i.index_id
WHERE
ips.page_count > 1000
ORDER BY
ips.avg_fragmentation_in_percent DESC;
Rebuilding an index drops and re-creates the index which removes fragmentation by sorting the data and compacting the pages.
SQL
ALTER INDEX ALL ON [table_name]
REBUILD;
Reorganizing an index is a lightweight operation that only defragments the leaf level of the index. This method is less resource-intensive.
SQL
ALTER INDEX ALL ON [table_name]
REORGANIZE;
The fill factor setting affects how much free space to leave on each page during index creation or rebuild. Setting an appropriate fill factor can mitigate future fragmentation.
SQL
CREATE INDEX [index_name] ON [table_name] (column_name)
WITH (FILLFACTOR = 80);
To ensure indexes remain optimal, establish a regular maintenance schedule. Here’s a sample script you can schedule to run periodically:
SQL
DECLARE @dbname NVARCHAR(255);
DECLARE db_cursor CURSOR FOR
SELECT name
FROM sys.databases
WHERE state = 0 -- Only online databases
OPEN db_cursor
FETCH NEXT FROM db_cursor INTO @dbname
WHILE @@FETCH_STATUS = 0
BEGIN
DECLARE @sql NVARCHAR(MAX);
SET @sql = 'USE [' + @dbname + '];' +
'DECLARE @table NVARCHAR(255);' +
'DECLARE table_cursor CURSOR FOR ' +
'SELECT OBJECT_NAME(object_id) ' +
'FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, ''DETAILED'') ' +
'WHERE avg_fragmentation_in_percent > 10 ' +
'OPEN table_cursor ' +
'FETCH NEXT FROM table_cursor INTO @table ' +
'WHILE @@FETCH_STATUS = 0 ' +
'BEGIN ' +
'EXEC(''ALTER INDEX ALL ON '' + @table + '' REORGANIZE'' + ''); ' +
'FETCH NEXT FROM table_cursor INTO @table ' +
'END ' +
'CLOSE table_cursor ' +
'DEALLOCATE table_cursor ';
EXEC sp_executesql @sql;
FETCH NEXT FROM db_cursor INTO @dbname
END
CLOSE db_cursor
DEALLOCATE db_cursor;
Regularly evaluating and addressing index fragmentation using these techniques is crucial for maintaining optimal database performance and efficiency.
## Case Studies
Real-world implementations of optimized index design can significantly enhance MSSQL performance. In this section, we will explore various case studies that demonstrate the tangible benefits of well-implemented indexing strategies. These examples will illustrate before-and-after scenarios, as well as provide performance metrics to highlight the improvements.
### Case Study 1: E-Commerce Platform Optimization
**Scenario:** An e-commerce site experienced severe latency during peak shopping periods. Customers reported slow searches and delayed checkout processes.
**Solution:** A detailed analysis of query patterns revealed that the `Orders` table, which held millions of rows, lacked proper indexing. By implementing a combination of clustered and non-clustered indexes, the performance improved drastically.
#### Before Optimization:
- **Query:**
```sql
SELECT OrderID, CustomerID, OrderDate
FROM Orders
WHERE CustomerID = 'CUST12345'
AND OrderDate > '2023-01-01'
```
- **Execution Time:** 8.4 seconds
- **I/O Statistics:**
- Logical reads: 150,000
- Physical reads: 10,200
#### After Optimization:
- **Indexes Added:**
```sql
CREATE CLUSTERED INDEX IX_Orders_OrderDate ON Orders (OrderDate);
CREATE NONCLUSTERED INDEX IX_Orders_CustomerID ON Orders (CustomerID);
```
- **Execution Time:** 1.3 seconds
- **I/O Statistics:**
- Logical reads: 1,500
- Physical reads: 300
**Result:** Query execution time improved by approximately 85%, significantly enhancing user experience during high-traffic periods.
### Case Study 2: Financial Reporting System
**Scenario:** A financial institution required faster report generation from their `Transactions` table, which aggregated large amounts of data.
**Solution:** By creating covering indexes, the number of required reads decreased significantly, thus accelerating report processing times.
#### Before Optimization:
- **Query:**
```sql
SELECT TransactionID, AccountID, TransactionDate, Amount
FROM Transactions
WHERE AccountID = 'ACC56789'
AND TransactionDate BETWEEN '2022-01-01' AND '2022-12-31'
```
- **Execution Time:** 15.7 seconds
- **I/O Statistics:**
- Logical reads: 250,000
- Physical reads: 20,500
#### After Optimization:
- **Indexes Added:**
```sql
CREATE NONCLUSTERED INDEX IX_Transactions_Covering
ON Transactions (AccountID, TransactionDate)
INCLUDE (TransactionID, Amount);
```
- **Execution Time:** 2.9 seconds
- **I/O Statistics:**
- Logical reads: 2,200
- Physical reads: 400
**Result:** Report generation time reduced by 82%, significantly improving productivity for financial analysts.
### Case Study 3: SaaS Application with Frequent Writes
**Scenario:** A SaaS application faced performance degradation due to log-heavy tables, necessitating a balanced read-write optimization.
**Solution:** Upgrading the indexing strategy to include selective indexing on highly queried columns while ensuring minimal overhead on write operations.
#### Before Optimization:
- **Query:**
```sql
SELECT LogID, UserID, Action, LogTimestamp
FROM UserLogs
WHERE UserID = 'USER78910'
AND LogTimestamp > '2023-08-01'
```
- **Execution Time:** 12.1 seconds
- **I/O Statistics:**
- Logical reads: 180,000
- Physical reads: 15,000
#### After Optimization:
- **Indexes Added:**
```sql
CREATE NONCLUSTERED INDEX IX_UserLogs_UserID ON UserLogs (UserID);
CREATE NONCLUSTERED INDEX IX_UserLogs_LogTimestamp ON UserLogs (LogTimestamp);
```
- **Execution Time:** 2.5 seconds
- **I/O Statistics:**
- Logical reads: 1,800
- Physical reads: 350
**Result:** Achieved a 79% reduction in query execution time with a minimal impact on write performance, facilitating smoother application functionality.
### Summary
These case studies underscore the importance of tailored indexing strategies for diverse scenarios. By implementing appropriate indexes—whether clustered, non-clustered, covering, or composite—you can significantly elevate database performance, reduce latency, and enhance overall system efficiency. Such optimizations yield substantial benefits, readily apparent through the tangible improvements in query execution times and resource utilization.
## Common Pitfalls and Best Practices
Designing indexes in MSSQL is crucial for optimal database performance, but it is easy to make mistakes that can lead to inefficiencies. In this section, we will identify some common pitfalls encountered when designing indexes and offer best practices to help you avoid these issues.
### Common Pitfalls
1. **Over-Indexing**:
- **Issue**: Adding too many indexes can degrade performance, especially for write-heavy applications. Each additional index requires extra storage and maintenance overhead.
- **Tip**: Regularly review your indexes using DMV queries to identify and remove unused or redundant indexes.
- **Example**:
```sql
SELECT
OBJECT_NAME(S.[OBJECT_ID]) AS [TableName],
I.[name] AS [IndexName],
I.[index_id] AS [IndexID],
C.[name] AS [ColumnName],
IX.[usage_count]
FROM
SYS.DM_DB_INDEX_USAGE_STATS AS IX
JOIN
SYS.INDEXES AS I
ON
IX.[index_id] = I.[index_id]
JOIN
SYS.TABLES AS S
ON
S.[object_id] = I.[object_id]
JOIN
SYS.COLUMNS AS C
ON
C.[object_id] = S.[object_id] AND C.[column_id] = I.[index_id]
WHERE
IX.[database_id] = DB_ID()
```
2. **Ignoring Write Performance**:
- **Issue**: Focusing solely on read performance without considering the impact on write operations can lead to significant performance degradation.
- **Tip**: Balance read and write performance by selectively indexing frequently queried columns and avoiding unnecessary indexes on frequently updated tables.
3. **Incorrect Index Order in Composite Indexes**:
- **Issue**: Placing columns in the wrong order in composite indexes can render the index suboptimal.
- **Tip**: Ensure that columns with a higher cardinality are placed first in composite indexes to maximize index selectivity.
4. **Not Accounting for Fragmentation**:
- **Issue**: Fragmented indexes can lead to inefficient I/O operations, impacting the performance.
- **Tip**: Regularly rebuild or reorganize indexes to minimize fragmentation.
- **Example**:
```sql
-- Rebuilding an index
ALTER INDEX ALL ON [dbo].[YourTable] REBUILD;
-- Reorganizing an index
ALTER INDEX ALL ON [dbo].[YourTable] REORGANIZE;
```
5. **Neglecting to Use Covering Indexes**:
- **Issue**: Overlooking the benefits of covering indexes can result in suboptimal query performance.
- **Tip**: Identify queries that can benefit from covering indexes and design them accordingly.
- **Example**:
```sql
-- Creating a covering index
CREATE NONCLUSTERED INDEX IDX_CoveringIndex
ON [dbo].[YourTable] (Column1, Column2)
INCLUDE (Column3, Column4);
```
### Best Practices
1. **Analyze Query Patterns**:
- Regularly review your query patterns to identify which columns are frequently used in SELECT, WHERE, JOIN, and ORDER BY clauses. Design your indexes based on these patterns.
2. **Leverage SQL Server Tools**:
- Utilize tools like SQL Server Profiler, Database Engine Tuning Advisor (DTA), and Dynamic Management Views (DMVs) to monitor and analyze index performance.
3. **Follow the "One-Fact-Per-Index" Principle**:
- Design your indexes to cater to specific query patterns rather than trying to create all-encompassing indexes. This avoids the pitfall of over-indexing.
4. **Consider Selectivity**:
- Index columns with high selectivity, i.e., columns that have a high ratio of unique values. This boosts the efficiency of index searches.
5. **Use the INCLUDE Clause Wisely**:
- When creating covering indexes, use the INCLUDE clause to add non-key columns, thus reducing the need for additional I/O operations.
- **Example**:
```sql
CREATE NONCLUSTERED INDEX IDX_Example
ON [dbo].[YourTable] (KeyColumn1, KeyColumn2)
INCLUDE (NonKeyColumn1, NonKeyColumn2);
```
6. **Performance Testing**:
- Regularly conduct performance testing using LoadForge to simulate various load conditions and assess the impact of your indexing strategy.
- **Example**:
```shell
loadforge test run --scenario your_scenario_id --env your_env_id
```
By following these best practices and being mindful of the common pitfalls, you can design efficient indexes that markedly improve MSSQL database performance.
## Conclusion
In this guide, we've delved into the essential aspects of optimizing index design for MSSQL, highlighting why it is a critical area for boosting database performance. Here's a summary of the key points we've covered and a reiteration of the importance of meticulous index optimization:
### Key Points Recap
1. **Understanding Indexes**:
- We explored what indexes are, how they function, and the different types available in MSSQL, including clustered and non-clustered indexes.
2. **Choosing the Right Indexes**:
- Emphasized the importance of selecting appropriate indexes. This involves analyzing query patterns, balancing read/write performance, and considering storage implications.
3. **Indexed Columns Selection**:
- Discussed best practices for selecting columns to index, focusing on the need to index selective columns, the impact of column size, and avoiding the trap of over-indexing.
4. **Composite Indexes**:
- Took an in-depth look at composite indexes, their usage scenarios, and the optimal ordering of columns within a composite index.
5. **Covering Indexes**:
- Introduced the concept of covering indexes, explained their benefits, and provided examples of how they can significantly speed up query performance.
6. **Index Maintenance**:
- Stressed the importance of regular index maintenance, including rebuilding and reorganizing indexes. Automated maintenance tasks were also discussed to streamline this process.
7. **Monitoring and Analyzing Index Usage**:
- Presented tools and techniques for monitoring index usage, like utilizing Dynamic Management Views (DMVs) to analyze and optimize index effectiveness.
8. **Dealing with Fragmentation**:
- Explained index fragmentation, its performance impacts, and methods to mitigate fragmentation such as adjusting fill factors and regular maintenance schedules.
9. **Case Studies**:
- Provided real-world examples illustrating how optimized index design improves performance, showcasing before-and-after scenarios with performance metrics.
10. **Common Pitfalls and Best Practices**:
- Identified frequent mistakes in index design and shared best practices to avoid them, ensuring the design is both effective and efficient.
### Importance of Optimizing Index Design
Optimizing index design in MSSQL isn't just a peripheral task—it's a core component of maintaining an efficient and responsive database system. Properly designed indexes can drastically reduce query execution times, lessen the strain on hardware resources, and improve overall user experience. Conversely, poor indexing strategies can lead to degraded performance, increased maintenance overhead, and even system outages.
By implementing the guidelines and best practices discussed in this guide, you can achieve:
- **Faster Query Performance**: Queries can retrieve data more quickly, which improves responsiveness for end-users.
- **Enhanced Resource Utilization**: Reduced CPU and I/O operations translate to more efficient use of server resources.
- **Improved Scalability**: Well-optimized indexes contribute to a more scalable database system, capable of handling increased loads more gracefully.
- **Reduced Maintenance Costs**: Effective index management helps in minimizing maintenance efforts and reducing costs associated with downtime and latency issues.
Implementing these practices and continually refining your approach will lead to a robust, efficient, and performant MSSQL database environment. For load testing and further performance benchmarking, consider using specialized tools like LoadForge to validate the impact of your optimization efforts.
In summary, the careful design and maintenance of indexes in MSSQL underpin the performance and reliability of your database applications. Remember to continuously monitor, analyze, and adjust your indexing strategies to adapt to changing data patterns and workloads, ensuring sustained high performance over time.