Introduction
In today's fast-paced digital world, application performance can make or break user experience. Slow response times and inefficient data handling lead to user frustration and, eventually, loss of traffic. This is where performance optimization becomes crucial, especially in web applications built using the Phoenix Framework. Phoenix, powered by Elixir and the Erlang VM, is designed to build scalable, high-performing applications. However, even the best frameworks require careful tuning to achieve optimal results.
This guide aims to walk you through various performance optimization techniques tailored specifically for Phoenix applications. We will cover a wide range of topics to help you understand the different bottlenecks that can affect your application's performance and how to tackle them effectively.
By the end of this guide, you will have a clear understanding of:
- Understanding Phoenix Framework: We'll start with a brief introduction to the Phoenix Framework and its architecture, focusing on how it leverages the power of the Erlang VM for building highly scalable applications.
- Profiling Your Phoenix Application: Learn how to profile your application using tools like ExProf and Ecto SQL logging to identify performance bottlenecks.
- Optimizing Database Queries: Dive into best practices for writing efficient database queries with Ecto, including query optimization, indexing, and effective use of
Repo.preload.
- Improving Middleware and Plug Efficiency: Discover techniques for optimizing middleware and plugs to minimize request processing time.
- Leveraging Phoenix Channels and PubSub: Explore guidelines for using Phoenix Channels and PubSub effectively for real-time features, including scaling tips and techniques to reduce latency.
- Caching Strategies: Understand various caching strategies to boost your application's responsiveness, including Phoenix's built-in caching and external systems like Redis.
- Concurrency and Parallelism: Maximize performance through concurrency and parallelism with Elixir-specific tips using
Task.async and spawn.
- Static Asset Optimization: Get tips on optimizing the delivery of static assets using Webpack, CDN integration, and reducing asset load times.
- Deployment Considerations: Learn best practices for deploying Phoenix applications, including clustering, load balancing, and tuning BEAM VM settings.
- Monitoring and Alerts: Set up monitoring and alerting systems to proactively identify and address performance issues using tools like Prometheus, Grafana, and external services.
- Load Testing with LoadForge: Finally, we'll guide you through load testing your Phoenix application with LoadForge, from setting up tests to analyzing results and best practices for load testing.
Throughout this guide, we'll focus on practical and actionable advice, complete with code examples, where applicable, to help you implement these optimizations in your own projects. Performance tuning is an ongoing process, and this guide will serve as a foundational resource for your journey.
Let's dive in and start optimizing your Phoenix applications for top-notch performance!
Understanding Phoenix Framework
Phoenix is a powerful web development framework built on Elixir and leveraging the Erlang VM. Known for its high concurrency and fault-tolerance, Phoenix allows developers to quickly build scalable, real-time applications with minimal boilerplate code. In this section, we'll delve into the architecture of the Phoenix Framework and explore how it utilizes the Erlang VM to deliver exceptional performance.
Key Features of Phoenix
- Real-time Capability: Phoenix Channels allow for real-time bi-directional communication between clients and servers. This is essential for applications requiring instant updates, such as chat applications or live dashboards.
- Fault-tolerance: By leveraging the Erlang VM, Phoenix applications inherit the robust fault-tolerance and "let it crash" philosophy of Erlang, ensuring high availability and reliability.
- Concurrency: Erlang’s lightweight process model allows Phoenix to handle thousands of concurrent connections efficiently.
- Productivity: Phoenix offers a rich set of tools and a clear structure to write maintainable and testable code, making the development process smooth and efficient.
Phoenix Architecture
Phoenix applications are organized into a well-defined structure conducive to building scalable and maintainable codebases. The core elements of the architecture include:
- Endpoint: The central hub for all HTTP connections, handling requests and dispatching them to appropriate controllers or sockets.
- Router: Defines the routes for requests, mapping URLs to controllers and actions.
- Controller: Manages incoming requests, processes data, and interacts with the business logic layer.
- View: Responsible for rendering templates and serializing data for the client.
- Socket: Manages WebSocket connections for real-time features.
- Channel: Handles real-time communication over WebSockets, allowing for topic-based communication.
Here’s a brief look at the directory structure of a standard Phoenix application:
my_app/
├── lib/
│ └── my_app/
│ ├── endpoint.ex
│ ├── router.ex
│ ├── controllers/
│ ├── views/
│ └── channels/
├── priv/
└── repo/
└── migrations/
Leveraging the Erlang VM
The Erlang VM (BEAM) is where Phoenix truly shines for performance and scalability. Here are a few ways in which Phoenix and Elixir leverage the power of the Erlang VM:
- Process Model: Elixir processes are extremely lightweight, allowing the system to handle millions of processes simultaneously. This is beneficial for web applications, where each request can be handled by its process.
- Error Handling: The "let it crash" philosophy enables developers to write resilient applications. By designing processes to fail and restart independently, the system remains robust and avoids cascading failures.
- Scalability: BEAM’s ability to run on multicore processors and distribute workloads over a cluster of machines ensures that Phoenix applications can scale horizontally with ease.
- Schedulers: BEAM schedulers are designed to efficiently use CPU resources by balancing load across available cores.
Here's an example showing the simplicity of starting a GenServer, a basic building block for processes in Elixir:
defmodule MyApp.Worker do
use GenServer
# Callbacks
def init(initial_state) do
{:ok, initial_state}
end
def handle_call(:ping, _from, state) do
{:reply, :pong, state}
end
def handle_cast(:increment, state) do
{:noreply, state + 1}
end
end
This basic GenServer showcases how you can manage state and handle synchronous (call) and asynchronous (cast) messages with ease.
Conclusion
By understanding the architecture and leveraging the Erlang VM, developers can build Phoenix applications that are not only high-performing but also resilient and scalable. This foundational knowledge will be essential as we move forward with more targeted performance optimization techniques in the subsequent sections.
Profiling Your Phoenix Application
Profiling your Phoenix application is an essential step in identifying and resolving performance bottlenecks. Without proper profiling, it's challenging to understand where your application may be experiencing slowdowns or inefficiencies. In this section, we'll cover techniques and tools for effectively profiling your Phoenix application. We'll focus on understanding specific tools like ExProf and Ecto SQL logging that can help you gain valuable insights into your application's performance characteristics.
Techniques for Profiling
Before diving into specific tools, it's essential to understand the overarching techniques used in profiling:
- Benchmarking: Measures the performance of isolated code segments to understand how long they take to execute.
- Tracing: Involves tracking the execution of functions and processes over time, providing a detailed view of how your application behaves under various conditions.
- Sampling: Captures snapshots of your application's state at regular intervals to identify which components are consuming the most resources.
Using ExProf for Profiling
ExProf is a lightweight profiling tool for Elixir applications, leveraging Erlang's Eprof library. It provides detailed reports on how much time processes spend in different functions. Here's how to integrate and use ExProf in your Phoenix application:
Installation
Add ExProf to your mix.exs dependencies:
defp deps do
[
{:exprof, "~> 0.2.4"}
]
end
Then run mix deps.get to install the dependency.
Profiling with ExProf
You can use ExProf to profile specific functions or parts of your application. For a comprehensive profiling, wrap the code you want to profile within an ExProf.Profile.profile block:
import ExProf.Macro
defmodule MyApp.SomeModule do
def run_heavy_operation do
profile do
# Place the code you want to profile here
IO.puts("Executing a heavy operation...")
:timer.sleep(1000)
IO.puts("Operation complete.")
end
:timer.tc(fn ->
heavy_function()
end)
end
defp heavy_function do
# Your complex logic here
end
end
By using ExProf.Profile.profile, you'll get a detailed output of function calls and their execution times, enabling you to identify which parts of your codebase are the most time-consuming.
Ecto SQL Logging
Database query performance is often a significant factor in the overall performance of a Phoenix application. Ecto, the database wrapper for Elixir, provides built-in logging that helps you analyze and optimize your queries.
Enabling Ecto SQL Logging
Ecto's SQL logging is enabled by default in the development environment. You can see the logs in your console output, which includes query execution times and the actual SQL statements:
[debug] QUERY OK source="users" db=3.7ms
SELECT u0."id", u0."name", u0."email" FROM "users" AS u0 []
This log entry indicates that a query to select user data took 3.7 milliseconds to execute.
Analyzing SQL Logs
Here are a few tips for interpreting and acting on Ecto SQL logs:
- Identify Slow Queries: Look for queries with high execution times (db=...). These queries may need optimization.
- Check Indexes: Ensure that your frequently queried fields have appropriate indexes to speed up search times.
- Use
Repo.preload: Instead of executing multiple individual queries, use Repo.preload to fetch associated data preemptively, reducing the number of database calls.
# Inefficient
users = Repo.all(User)
Enum.map(users, fn user -> Repo.get(Post, user.post_id) end)
# Efficient
users = Repo.all(User) |> Repo.preload(:posts)
Conclusion
Profiling is a crucial step in optimizing the performance of your Phoenix application. By leveraging tools like ExProf for detailed function-level analysis and Ecto's SQL logging for database query insights, you can accurately identify and address performance bottlenecks. Focus on understanding where your application spends the most time and effort, and iterate on improvements to achieve a highly performant application.
Optimizing Database Queries
Efficient database querying is paramount to the performance of any Phoenix application. In this section, we'll explore best practices for writing optimized queries using Ecto, discuss the importance of indexing, and demonstrate how to use Repo.preload effectively.
Query Optimization
Optimizing your Ecto queries can lead to significant performance improvements. Here are some general guidelines to follow:
-
Use Selective Fields:
Instead of fetching all fields from a table, retrieve only the fields you need. This reduces the amount of data transferred and processed.
# Inefficient query
users = Repo.all(User)
# Optimized query
users = Repo.all(from u in User, select: [:id, :name, :email])
-
Use Batching for Large Datasets:
When dealing with large datasets, querying data in batches can prevent memory overload and increase efficiency.
def fetch_users_in_batches(batch_size \\ 100) do
Repo.transaction(fn ->
Repo.stream(from u in User, order_by: :id)
|> Stream.chunk_every(batch_size)
|> Enum.each(&process_batch/1)
end)
end
defp process_batch(batch) do
# Process each batch of users
end
-
Avoid N+1 Query Problem:
The N+1 query problem occurs when an application executes N additional queries to fetch related data for each row in the result set.
# Inefficient way
users = Repo.all(User)
Enum.each(users, fn user ->
Repo.get!(Profile, user.profile_id)
end)
# Optimized way using Repo.preload
users = Repo.all(User) |> Repo.preload(:profile)
Indexing
Indexing is crucial for speeding up data retrieval. Without proper indexing, even simple queries can become slow as the amount of data grows.
- Primary Keys: Ensure all primary keys are indexed by default.
- Foreign Keys: Index foreign keys to improve join operations.
- Frequent Query Columns: Index columns that are frequently queried against or used in
WHERE clauses.
To create an index in a migration:
defmodule MyApp.Repo.Migrations.AddIndexToUsersEmail do
use Ecto.Migration
def change do
create index(:users, [:email])
end
end
Effective Use of Repo.preload
Repo.preload is a powerful tool to prefetch associated records in a single query, reducing the need for multiple database hits.
-
Preloading Associations:
Use Repo.preload to load associations eagerly when you know you will need associated data.
user = Repo.get(User, user_id) |> Repo.preload(:profile)
-
Selectively Preloading:
Limit preloads to only the necessary associations to minimize overhead.
user = Repo.get(User, user_id) |> Repo.preload([:profile, posts: [:comments]])
-
Conditional Preloading:
Preload associations conditionally based on your application logic.
users = Repo.all(User)
|> Enum.map(&conditional_preload(&1))
defp conditional_preload(user) do
if user.is_active do
Repo.preload(user, :active_sessions)
else
user
end
end
By adhering to these best practices for query optimization, indexing, and preloading, you can significantly improve the performance of database interactions within your Phoenix application. These efforts, combined with continuous monitoring and profiling, will ensure that your application's data layer remains efficient and responsive.
Improving Middleware and Plug Efficiency
Middleware (also known as plugs in Phoenix parlance) is critical in processing incoming requests and outgoing responses. However, inefficient use of middleware can lead to increased request latency and poor performance. This section will provide strategies to optimize middleware and plugs within your Phoenix application to ensure efficient request handling.
Understanding Plug and Middleware
In Phoenix, Plugs are the building blocks for request processing. They function as middleware components that sit between the web server and your application's final endpoint, allowing you to modify requests and responses.
A Plug in Phoenix consists of two functions:
init/1: Accepts options and initializes the plug.call/2: Takes the connection and options and processes the request.
A basic plug might look like this:
defmodule MyApp.Plugs.ExamplePlug do
import Plug.Conn
def init(options), do: options
def call(conn, _opts) do
conn
|> put_resp_header("x-plug-example", "example-value")
end
end
Tips for Optimizing Plugs
-
Avoid Unnecessary Plugs: Only use necessary plugs in your pipeline. Each plug adds overhead, so minimizing the number can reduce request processing time.
# Avoid unnecessary plugs
pipeline :browser do
plug :accepts, ["html"]
plug :fetch_session
plug :fetch_flash
# Removed unnecessary/unused plugs to improve performance
end
-
Order Matters: Place plugs with minimal processing and high impact at the start of your pipeline. More resource-intensive plugs can follow, ensuring that expensive operations are only performed when necessary.
-
Use Function Plugs When Possible: Single-purpose, lightweight plugs can be defined as functions rather than modules, reducing complexity and overhead.
defmodule MyAppWeb.Router do
...
pipeline :browser do
plug :put_secure_browser_headers
end
# Function plug implementation
defp put_secure_browser_headers(conn, _opts) do
put_resp_header(conn, "x-content-type-options", "nosniff")
end
end
-
Memoize Expensive Operations: Store the results of expensive computations and reuse them. This avoids recomputing values multiple times within a request lifecycle.
-
Asynchronous Processing: Offload non-critical processing to asynchronous tasks. For example, logging or external API requests can be processed in the background.
defmodule MyApp.Plugs.LogRequest do
import Plug.Conn
def init(options), do: options
def call(conn, _opts) do
Task.start(fn -> log_request(conn) end)
conn
end
defp log_request(conn) do
IO.puts("Logging request: #{conn.method} #{conn.request_path}")
# Add more logging logic here
end
end
-
Custom Middleware Optimization: Analyze custom middleware for optimization opportunities. Inline processing functions and remove redundant operations for performance gains.
Measuring Plug Performance
Use Plug.Debugger and performance profiling tools to measure the impact of your plugs. Monitoring tools like Phoenix's built-in telemetry can help you identify slow-running plugs.
defmodule MyAppWeb.Endpoint do
use Phoenix.Endpoint, otp_app: :my_app
if Mix.env() == :dev do
plug Plug.Debugger
end
...
end
Conclusion
Efficient middleware and plug usage is a crucial aspect of improving the overall performance of your Phoenix application. By following these optimization tips, you can reduce request processing times and ensure your application runs smoothly. Always profile and test plug performance as part of your optimization process to achieve the best results.
Next, we will look into leveraging Phoenix Channels and PubSub to further optimize real-time features in your Phoenix application.
Leveraging Phoenix Channels and PubSub
Phoenix Channels and PubSub provide a powerful and scalable way to handle real-time communication in your applications. They are particularly useful for features like chat applications, live updates, notifications, and more. This section will guide you through the best practices for utilizing these tools effectively, scaling your real-time features, and reducing latency.
Understanding Phoenix Channels
Phoenix Channels facilitate bidirectional communication between clients and servers, leveraging WebSockets for fast, efficient exchange of messages. Here’s a simple example of a channel:
defmodule MyAppWeb.MyChannel do
use MyAppWeb, :channel
def join("room:lobby", _message, socket) do
{:ok, socket}
end
def handle_in("new_msg", %{"body" => body}, socket) do
broadcast! socket, "new_msg", %{body: body}
{:noreply, socket}
end
end
Tips for Effective Channel Usage:
- Limit the use of
broadcast/3: Make sure you only broadcast necessary messages to avoid unnecessary load.
- Optimize joins: Perform minimal and efficient work inside the
join callback to ensure quick connections.
- Handle disconnections gracefully: Manage state cleanup when a client disconnects to free up resources.
Effective PubSub Patterns
Phoenix PubSub enables message passing between different parts of the application, both within a single node and across a cluster:
defmodule MyAppNotification do
alias Phoenix.PubSub
def notify(user_id, message) do
PubSub.broadcast!(MyApp.PubSub, "user:#{user_id}", message)
end
end
In the example above, messages are broadcast to specific topics, which can be subscribed to by various processes or channels.
Best Practices for PubSub:
- Topic structure: Design a clear and hierarchical topic structure to organize messages effectively.
- Throttling: Implement throttling mechanisms to prevent message flooding.
- Sharding topics: For systems with high volume, consider sharding topics to distribute the load better.
Scaling Tips
-
Clustering: Use Phoenix's built-in clustering capabilities to distribute channel processes across multiple nodes. This can be achieved by configuring BEAM distribution:
config :my_app, MyAppWeb.Endpoint,
url: [host: "example.com"],
secret_key_base: "...",
render_errors: [view: MyAppWeb.ErrorView, accepts: ~w(html json)],
pubsub_server: MyApp.PubSub,
live_view: [signing_salt: "..."]
-
Load Balancing: Use load balancers to distribute incoming WebSocket connections across multiple nodes.
-
Optimize Node Communication: Ensure efficient inter-node communication by tuning VM and network settings for your specific deployment environment.
Reducing Latency
- Edge Nodes: Deploy edge nodes closer to users to reduce latency.
- Efficient Broadcasts: Use efficient message encoding and avoid large payloads.
- Monitor Performance: Continuously monitor channel performance using tools like Telemetry, and identify and resolve latency issues.
Summary
By effectively utilizing Phoenix Channels and PubSub, you can build robust and scalable real-time features in your Phoenix applications. Follow best practices for channel handling, PubSub patterns, and scaling to ensure high performance and low latency. This sets a strong foundation for delivering a seamless and responsive user experience.
Continue optimizing other parts of your Phoenix application as discussed in the upcoming sections for overall improved performance.
Caching Strategies
Caching is a powerful technique for improving the performance of your Phoenix application by reducing the load on the database and speeding up response times. In this section, we'll explore various caching strategies including leveraging Phoenix's built-in caching capabilities and integrating with external caching systems like Redis.
Leveraging Phoenix's Built-in Caching
Phoenix provides several built-in mechanisms to cache data efficiently. These can be leveraged to store frequently accessed data and avoid repetitive processing. Here are some key strategies:
ETag and Conditional Requests
ETag headers and conditional requests can help reduce the amount of data transferred between the server and the client by ensuring that data is only sent when it has changed.
defmodule MyAppWeb.MyController do
use MyAppWeb, :controller
plug :put_etag
def show(conn, %{"id" => id}) do
data = MyApp.get_data(id)
if stale?(conn, data) do
render(conn, "show.json", data: data)
else
send_resp(conn, :not_modified, "")
end
end
defp put_etag(conn, _) do
put_resp_header(conn, "etag", :crypto.hash(:md5, conn.request_path) |> Base.encode64())
end
end
Phoenix Cache Plug
The Phoenix.Cache plug is a useful tool for caching responses. It stores responses in the cache and serves them directly if the same request is received again.
Install the phoenix_cache plug by adding it to your mix.exs:
defp deps do
[
{:phoenix, "~> 1.5.9"},
{:phoenix_cache, "~> 0.2"}
]
end
Then you can use it in your router:
defmodule MyAppWeb.Router do
use MyAppWeb, :router
use PhoenixCache
pipeline :api do
plug :accepts, ["json"]
plug PhoenixCache, ttl: :timer.hours(1)
end
scope "/api", MyAppWeb do
pipe_through :api
get "/data/:id", MyController, :show
end
end
Using External Caching Systems: Redis
For more advanced caching needs, external systems like Redis offer extensive capabilities for distributed caching. Redis is an in-memory data store that can handle high-throughput and low-latency caching.
Installing and Configuring Redis
First, add Redix to your dependencies:
defp deps do
[
{:redix, "~> 1.0"}
]
end
Next, set up a Redis connection in your application's supervision tree:
defmodule MyApp.Application do
use Application
def start(_type, _args) do
children = [
{Redix, name: :redix}
]
opts = [strategy: :one_for_one, name: MyApp.Supervisor]
Supervisor.start_link(children, opts)
end
end
Caching Data with Redis
Here's an example of caching data fetched from the database with Redis:
defmodule MyApp.Cache do
@moduledoc """
A module to handle caching with Redis.
"""
@ttl 3600 # 1 hour in seconds
def fetch(id) do
case Redix.command(:redix, ["GET", "data:#{id}"]) do
{:ok, nil} ->
data = MyApp.get_data(id)
:ok = Redix.command(:redix, ["SETEX", "data:#{id}", @ttl, :erlang.term_to_binary(data)])
{:ok, data}
{:ok, binary} ->
data = :erlang.binary_to_term(binary)
{:ok, data}
{:error, reason} ->
{:error, reason}
end
end
end
Using Redis for Session Storage
Redis can also be used to manage user sessions efficiently. You can configure Phoenix to use Redis for session storage by updating your config/config.exs:
config :my_app, MyAppWeb.Endpoint,
session_store: :redis,
session_options: [redis_server: "redis://localhost:6379/0", key: "_my_app_key"]
Conclusion
Effective caching strategies can drastically improve your Phoenix application's responsiveness and reduce database load. By leveraging Phoenix's built-in caching mechanisms and integrating with powerful external systems like Redis, you can ensure your application scales while maintaining high performance. Remember, while caching can provide significant performance benefits, it should be used judiciously to ensure it doesn't become a maintenance burden or lead to stale data issues.
Concurrency and Parallelism
Maximizing performance in a Phoenix application heavily depends on how well you utilize concurrency and parallelism. Elixir, built on the Erlang VM, boasts robust concurrency support that can significantly enhance your application's throughput and responsiveness. This section covers key techniques and Elixir-specific tips for leveraging concurrency to optimize your Phoenix application.
Understanding Concurrency in Elixir
Elixir handles concurrency through lightweight process management, enabled by the BEAM virtual machine. Each process in Elixir:
- Runs in isolation: No shared memory between processes, reducing the risk of race conditions.
- Is lightweight: Thousands of processes can run concurrently with minimal overhead.
- Communicates via message passing: Processes send and receive messages, allowing for efficient data exchange without direct memory access.
Task Module
The Task module simplifies concurrent task execution. It's particularly useful for short-lived concurrent tasks. Let's explore how to use Task.async and Task.await.
Task.async and Task.await
Task.async is utilized to spawn a process and run a given function concurrently. Task.await retrieves the result once the task completes.
defmodule ConcurrencyExample do
def perform_tasks do
task1 = Task.async(fn -> heavy_computation(1) end)
task2 = Task.async(fn -> heavy_computation(2) end)
result1 = Task.await(task1)
result2 = Task.await(task2)
{result1, result2}
end
defp heavy_computation(input) do
# simulate a heavy computation
:timer.sleep(2000)
input * 2
end
end
In this code, heavy_computation/1 runs concurrently in two separate processes, significantly reducing overall execution time from 4 seconds to about 2 seconds.
spawn and Message Passing
For more fine-grained control over processes, you can use spawn to create processes and send/receive messages for inter-process communication.
defmodule MessagePassingExample do
def perform do
parent = self()
child = spawn(fn -> child_process(parent) end)
send(child, {:calculate, 5})
receive do
{:result, result} ->
IO.puts("Result from child: #{result}")
end
end
defp child_process(parent) do
receive do
{:calculate, value} ->
result = value * 2
send(parent, {:result, result})
end
end
end
In this example, the parent process spawns a child process that waits for a message. When the child receives a :calculate message, it performs a computation and sends the result back to the parent.
Using GenServer
GenServer is a powerful abstraction for building concurrent applications. It simplifies the process lifecycle management and message handling.
defmodule GenServerExample do
use GenServer
def start_link(_) do
GenServer.start_link(__MODULE__, %{}, name: __MODULE__)
end
def init(state) do
{:ok, state}
end
def handle_call({:double, value}, _from, state) do
{:reply, value * 2, state}
end
end
defmodule Main do
def perform do
{:ok, pid} = GenServerExample.start_link([])
result = GenServer.call(pid, {:double, 5})
IO.puts("Result from GenServer: #{result}")
end
end
This GenServer example initializes a state and handles synchronous calls to double a given value, illustrating how GenServers can manage state and computations concurrently.
Recommended Practices
- Use Supervision Trees: To manage process lifecycles and ensure fault tolerance.
- Leverage Task.Supervisor: For supervised and robust task management.
- Monitor Processes: Use
Process.monitor/1 to track process exits and handle failures gracefully.
- Avoid Long Blocking Operations: Perform such tasks asynchronously to keep the application responsive.
Conclusion
Implementing concurrency and parallelism in Phoenix applications can vastly improve performance and responsiveness. Elixir's concurrency model, combined with tools like Task, spawn, and GenServer, provides a solid foundation for optimizing your application's performance. By following these practices, you can ensure your Phoenix application remains scalable and resilient under load.
Static Asset Optimization
Optimizing the delivery of static assets is crucial for improving the performance of your Phoenix application, ensuring faster page load times, and providing a better user experience. In this section, we'll cover some essential tips for optimizing static assets, including the use of Webpack, CDN integration, and strategies for reducing asset load times.
Utilizing Webpack for Asset Management
Webpack is a powerful module bundler that helps manage static assets such as JavaScript, CSS, and images. By using Webpack, you can bundle and minify your assets, resulting in smaller file sizes and faster load times.
-
Installing Webpack:
Ensure that you have Webpack installed and configured in your Phoenix application. Typically, this is done by default in modern Phoenix apps.
# Install dependencies
mix deps.get
npm install --prefix ./assets
-
Configuring Webpack:
Configure Webpack to bundle and minify your assets. Here’s a basic configuration example:
// assets/webpack.config.js
const path = require('path');
module.exports = {
entry: './js/app.js',
output: {
filename: 'app.js',
path: path.resolve(__dirname, '../priv/static/js'),
publicPath: '/js/'
},
module: {
rules: [
{
test: /\.js$/,
exclude: /node_modules/,
use: 'babel-loader'
},
{
test: /\.css$/,
use: ['style-loader', 'css-loader']
}
]
}
};
-
Building Assets:
Use Mix to build your assets for production:
MIX_ENV=prod mix phx.digest
npm run deploy --prefix ./assets
CDN Integration
Using a Content Delivery Network (CDN) is an effective way to speed up the delivery of static assets by serving them from geographically distributed servers. This can significantly reduce latency and increase load speeds for users across different regions.
-
Selecting a CDN:
Choose a reputable CDN provider such as Cloudflare, AWS CloudFront, or Akamai.
-
Configuring Phoenix to Use a CDN:
Update your Phoenix application to use the CDN for serving static assets. You can do this by setting the static_url in your endpoint configuration:
# config/prod.exs
config :your_app, YourAppWeb.Endpoint,
static_url: [host: "your-cdn-url.com"]
-
Uploading Assets to CDN:
Automatically or manually upload your static assets to your CDN provider. Many CDNs offer tools or plugins that can automate this process.
Reducing Asset Load Times
Beyond using Webpack and a CDN, there are additional strategies to reduce asset load times:
-
Minify and Compress Assets:
Ensure that JavaScript, CSS, and image files are minified and compressed. Webpack can handle the minification process, but for image compression, you might consider using tools like ImageOptim or online compressing services.
// Add to Webpack config for minification
const TerserPlugin = require('terser-webpack-plugin');
module.exports = {
optimization: {
minimize: true,
minimizer: [new TerserPlugin()],
},
};
-
Async Load JavaScript:
Use the async or defer attributes when including JavaScript files to avoid blocking the parsing of HTML.
<script src="/js/app.js" async></script>
-
HTTP/2 and Gzip:
Enable HTTP/2 and Gzip compression on your web server to improve the speed of asset delivery. For example, with Nginx:
server {
listen 443 ssl http2;
gzip on;
gzip_types text/plain application/javascript text/css;
}
-
Cache Headers:
Set appropriate cache headers to take advantage of browser caching.
# Add cache headers in your Plug pipeline
plug Plug.Static, at: "/", from: :your_app, gzip: true,
headers: [{"cache-control", "public, max-age=31536000"}]
By effectively managing and optimizing static assets, you can significantly enhance the performance of your Phoenix application, leading to faster load times and a better user experience. Implementing these strategies ensures that your users will encounter minimal delays, keeping your application efficient and responsive.
Deployment Considerations
Deploying Phoenix applications efficiently is crucial for maintaining performance at scale. By following best practices in clustering, load balancing, and fine-tuning BEAM VM settings, you can ensure your application runs smoothly and handles high traffic without issues.
Clustering with Phoenix
Clustering is a powerful feature of the BEAM virtual machine on which Elixir runs. By clustering your Phoenix application, you can ensure redundancy, facilitate horizontal scaling, and distribute load efficiently.
-
Setting Up Distributed Nodes:
-
In your configuration file, set the :distributed flag and define node names:
config :my_app, MyApp.Repo,
node: {:distributed, ["node1@127.0.0.1", "node2@127.0.0.1"]}
-
Start your nodes with unique names and cookies to enable communication between them:
iex --sname node1 --cookie "secret_cookie"
iex --sname node2 --cookie "secret_cookie"
-
Connecting Nodes:
-
Leveraging Phoenix Presence and PubSub:
- Phoenix Presence—used for tracking and broadcasting information about users in a system—can utilize the cluster for scalability.
Load Balancing
Load balancing is essential for distributing incoming HTTP requests across multiple servers to ensure no single server is overwhelmed.
-
Using Nginx:
-
Using HAProxy:
Tuning BEAM VM Settings
Optimizing the BEAM VM settings affects how your Elixir and Phoenix application perform at runtime. Here are a few key configurations:
-
Memory Allocation:
-
Scheduler Utilization:
-
Garbage Collection:
Additional Tips
- Regularly Update Dependencies: Ensure that all dependencies are up-to-date to take advantage of the latest performance improvements and security patches.
- Continuous Deployment and Integration: Implement CI/CD pipelines to automate deployment, ensuring consistent and error-free deployments.
By following these deployment best practices, you can optimize your Phoenix application for performance, scalability, and reliability. In the next section, we will explore how to monitor and set up alerts to proactively identify and address performance issues.
Monitoring and Alerts
In any web application, real-time monitoring and alerting are crucial for maintaining optimal performance and ensuring quick recovery from any issues that arise. By effectively setting up monitoring and alerting in your Phoenix application, you can proactively identify performance bottlenecks and address them before they impact your users. In this section, we will cover how to implement monitoring and alerts using Prometheus, Grafana, and other external services.
Prometheus for Monitoring Metrics
Prometheus is a powerful open-source monitoring system and time-series database. It can collect and store metrics, providing a query language (PromQL) to analyze and generate alerts. To get started with Prometheus in a Phoenix application, follow these steps:
-
Add Prometheus Dependencies: First, ensure you have the necessary Prometheus dependencies in your Phoenix application. You can use prometheus_ex and prometheus_plugs to integrate Prometheus with Phoenix.
defp deps do
[
{:prometheus_ex, "~> 3.0"},
{:prometheus_plugs, "~> 1.1"}
]
end
-
Configure Prometheus: Next, configure Prometheus within your application. In your endpoint.ex file, add the following plug to collect metrics:
plug Prometheus.PlugExporter
# Optional: Add custom metrics
defmodule MyAppWeb.Metrics do
use Prometheus.Metric
def setup do
Prometheus.Metric.Counter.declare(name: :phoenix_request_total, help: "Total number of requests")
end
end
# In your application start method
def start(_type, _args) do
MyAppWeb.Metrics.setup()
Supervisor.start_link([...], strategy: :one_for_one)
end
-
Run Prometheus: Configure Prometheus to scrape metrics from your Phoenix application. Set up a prometheus.yml file specifying the scrape target:
scrape_configs:
- job_name: 'phoenix_app'
static_configs:
- targets: ['localhost:4000'] # Your Phoenix application's URL
-
Start Prometheus: Run Prometheus using Docker:
docker run -d -p 9090:9090 -v $(pwd)/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus
Grafana for Visualizing Metrics
Grafana works hand-in-hand with Prometheus to visualize collected metrics. To visualize your metrics using Grafana, follow these steps:
-
Run Grafana: You can start a Grafana instance using Docker:
docker run -d -p 3000:3000 grafana/grafana
-
Add Prometheus as a Data Source:
- Log in to your Grafana instance (
http://localhost:3000).
- Navigate to Configuration > Data Sources.
- Add Prometheus as a new data source and configure its URL (
http://localhost:9090).
-
Create Dashboards:
- Create a new dashboard in Grafana.
- Add new panels with queries like
rate(phoenix_request_total[1m]).
- Customize visualizations to suit your monitoring needs.
Setting Up Alerts
Alerts notify you of performance anomalies. Prometheus and Grafana provide robust alerting mechanisms.
-
Prometheus Alert Rules: Create alert rules in your prometheus.yml file:
rule_files:
- "alerts.rules"
alerting:
alertmanagers:
- static_configs:
- targets: ['localhost:9093']
-
Define Alert Rules (alerts.rules):
groups:
- name: example
rules:
- alert: HighRequestRate
expr: rate(phoenix_request_total[5m]) > 100
for: 1m
labels:
severity: critical
annotations:
summary: "High request rate detected"
description: "The request rate is at {{ $value }} requests per second."
-
Alertmanager: Deploy Alertmanager to handle alerts.
docker run -d -p 9093:9093 prom/alertmanager
-
Grafana Alerts: Grafana also supports alerting based on its dashboards.
- Create an alert in a Grafana dashboard panel.
- Configure notification channels (email, Slack, etc.).
External Services
You can complement your monitoring setup with external services like:
- New Relic: For deep performance analytics and APM.
- Datadog: Integrates with Prometheus and provides full-stack observability.
- AppSignal: Specifically designed for Elixir and Phoenix applications.
By setting up effective monitoring and alerting, you can ensure your Phoenix application runs smoothly and efficiently, catching any performance issues before they affect your users. With Prometheus, Grafana, and additional external services, you have a comprehensive toolkit for maintaining and optimizing your application's performance.
This markdown content provides a comprehensive guide to setting up monitoring and alerts for a Phoenix application using Prometheus, Grafana, and external services. This section should fit seamlessly into the larger article on Phoenix performance optimization.
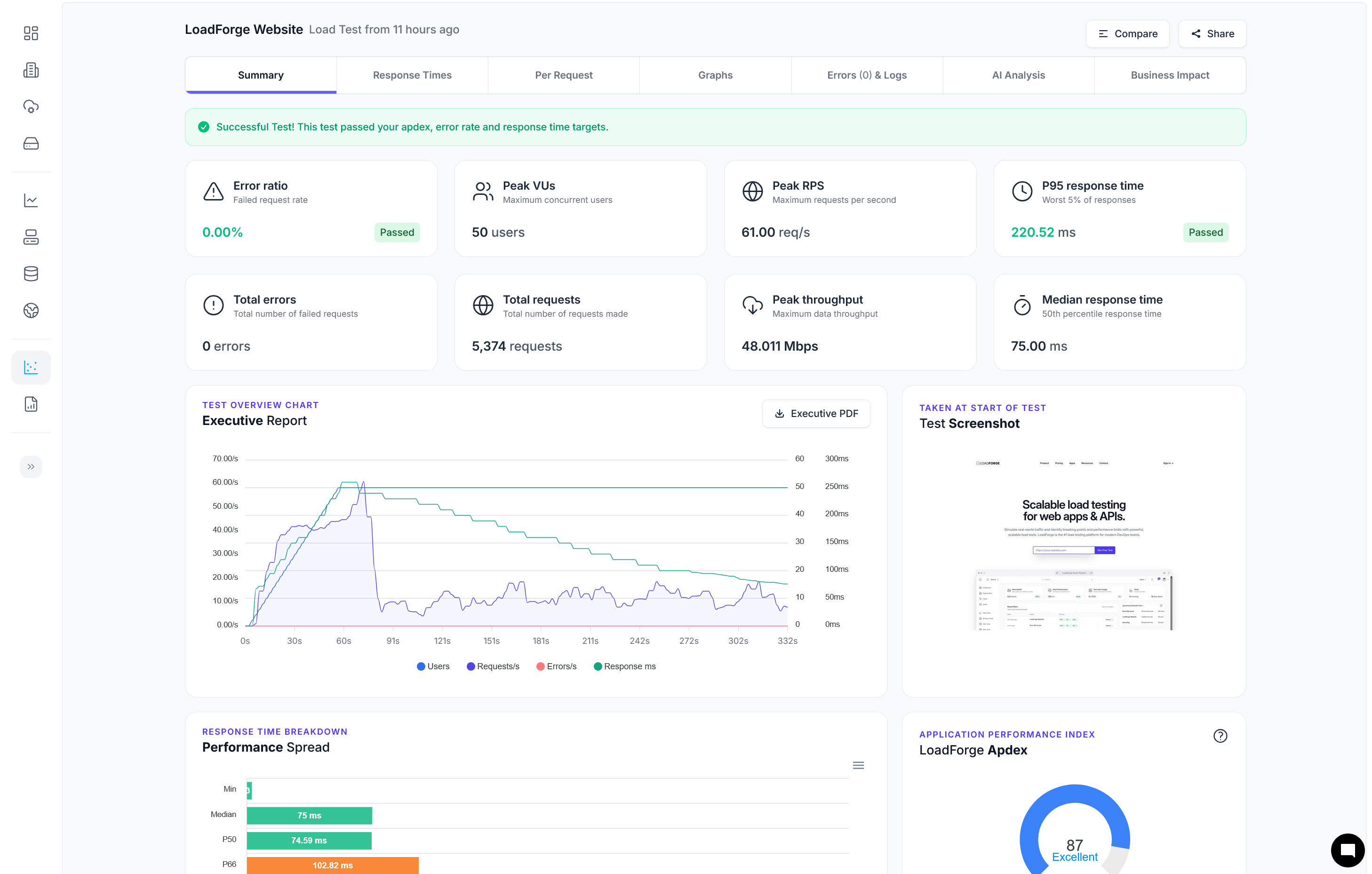
## Load Testing with LoadForge
Load testing is a critical phase in the performance optimization journey of your Phoenix application. Ensuring your application can handle the expected load and identifying potential bottlenecks under stress can save you from unpleasant surprises in production. In this section, we'll introduce you to LoadForge and demonstrate how to set up and efficiently use it for load testing your Phoenix application.
### Why Load Testing?
Load testing helps you:
- Validate the performance of your application under various load conditions.
- Identify and rectify bottlenecks before they impact your users.
- Ensure that new features or changes haven't introduced performance regressions.
- Optimize resource allocation to maintain a smooth user experience during peak traffic.
### Introduction to LoadForge
LoadForge is a powerful, easy-to-use load testing tool designed to simulate real user traffic and measure how your application performs under different conditions. With LoadForge, you can:
- Design and execute load tests with customizable parameters.
- Monitor application performance and resource utilization.
- Analyze results to gain insights into potential performance issues.
### Setting Up LoadForge
To get started with LoadForge, follow these steps:
1. **Sign Up and Log In:**
To use LoadForge, you need to sign up at the [LoadForge website](https://www.loadforge.com). Once signed up, log in to access the dashboard.
2. **Create a New Load Test:**
- From the dashboard, click on **New Test**.
- Configure the **Test Name**, **URL** of your Phoenix application, and other parameters such as the number of concurrent users and duration of the test.
3. **Define Test Scenarios:**
- LoadForge supports defining complex test scenarios. You can add multiple steps to simulate user journeys. For example, logging in, browsing products, and making a purchase.
```json
{
"scenarios": [
{
"name": "User Journey",
"steps": [
{
"method": "GET",
"url": "/",
"name": "Visit Homepage"
},
{
"method": "POST",
"url": "/login",
"name": "Login",
"body": {
"username": "testuser",
"password": "password"
}
},
{
"method": "GET",
"url": "/products",
"name": "Browse Products"
}
]
}
]
}
- Run the Test:
- Once your test is configured, click Run Test. LoadForge will start simulating traffic according to your defined scenarios.
- Monitor the test in real-time from the dashboard to see how your Phoenix application is responding.
Analyzing Load Testing Results
After the test completes, LoadForge provides detailed reports to help you analyze the performance of your application. Key metrics to look out for include:
- Response Time: Average, minimum, and maximum response times of your endpoints.
- Throughput: Number of requests processed per second.
- Error Rate: Percentage of requests that resulted in errors.
- Resource Utilization: CPU and memory usage during the test.
Best Practices for Load Testing
To get the most out of load testing with LoadForge, keep these best practices in mind:
- Test in a Production-like Environment: Ensure your testing environment closely resembles your production setup to get realistic results.
- Gradual Increase in Load: Start with a small number of users and gradually increase the load to identify the breaking point of your application.
- Run Tests Regularly: Perform load tests regularly, especially after significant changes or feature additions to your application.
- Analyze Bottlenecks: Use the detailed reports provided by LoadForge to pinpoint bottlenecks and optimize them.
- Iterate and Improve: Load testing is an iterative process. Apply fixes and optimizations, and re-test to measure the impact of your changes.
Conclusion
Load testing with LoadForge equips you with the insights needed to ensure your Phoenix application can handle the rigors of real-world usage. By identifying and addressing performance bottlenecks early, you can maintain a smooth and responsive experience for your users, even under peak load conditions.
Incorporating load testing into your development and deployment pipeline is a proactive step towards building robust and high-performing Phoenix applications. Happy optimizing!
Conclusion
In this guide, we've traversed a comprehensive roadmap of performance optimization strategies for Phoenix applications. By understanding and applying these techniques, you can significantly enhance both the efficiency and scalability of your Phoenix projects. Here’s a quick recap of the key points we covered:
-
Understanding Phoenix Framework:
- Grasping the fundamentals of Phoenix and its architecture.
- Leveraging the strengths of the Erlang VM for building scalable applications.
-
Profiling Your Phoenix Application:
- Employing tools like ExProf and Ecto SQL logging to identify bottlenecks.
-
Optimizing Database Queries:
- Writing efficient queries with Ecto.
- Utilizing indexing and Repo.preload effectively.
-
Improving Middleware and Plug Efficiency:
- Reducing request processing time through optimized middleware and custom plugs.
-
Leveraging Phoenix Channels and PubSub:
- Efficiently implementing real-time features.
- Scaling and reducing latency effectively.
-
Caching Strategies:
- Leveraging Phoenix’s built-in caching mechanisms.
- Integrating external systems like Redis for improved performance.
-
Concurrency and Parallelism:
- Utilizing Elixir-specific features like Task.async and spawn for background processing.
-
Static Asset Optimization:
- Optimizing the delivery of static assets through Webpack, CDN integration, and minimizing asset load times.
-
Deployment Considerations:
- Employing best practices for deploying Phoenix applications, including clustering and load balancing.
- Tuning BEAM VM settings for optimal performance.
-
Monitoring and Alerts:
- Setting up monitoring tools like Prometheus and Grafana.
- Implementing alerts to proactively identify performance issues.
-
Load Testing with LoadForge:
- Setting up load tests tailored to Phoenix applications using LoadForge.
- Analyzing load test results for continuous improvement.
Continuous Optimization
Performance optimization is an ongoing process, not a one-time effort. Even after you've employed the techniques discussed in this guide, it's crucial to continually monitor your application and make adjustments as needed.
- Regular Audits: Schedule regular audits of your application's performance, employing the profiling techniques discussed.
- Stay Updated: As both Elixir and Phoenix evolve, new performance optimization techniques and tools will emerge. Stay current by following the community and documented updates.
- Iterative Testing: Continuously refine your load testing scenarios with LoadForge. Analyzing the results will provide actionable insights into how your application handles increased traffic and stress.
Further Learning Resources
To aid you on your journey, here are some additional resources:
-
Books:
- Programming Phoenix by Chris McCord, Bruce Tate, and José Valim
- Designing for Scalability with Erlang/OTP by Francesco Cesarini and Steve Vinoski
-
Online Courses:
-
Documentation:
-
Communities and Forums:
By embedding these practices into your development lifecycle, you'll ensure your Phoenix applications remain robust, scalable, and high-performing. Here's to high performance and smooth scaling with Phoenix!