Introduction
Welcome to our comprehensive guide on creating a Locustfile to simulate the login process on your website. This guide is designed to help developers and testers understand the criticality of load testing the login functionality using Locust, an open-source performance testing tool. By simulating user login at scale, you can uncover potential bottlenecks and improve the resilience of your authentication systems under high traffic conditions.
Purpose of Simulating Login Processes:
The login page is often the first point of interaction with your application for many users. It’s also a fundamental component that can impact both user experience and security. Simulating logins at scale helps ensure that:
- Your application can handle high volumes of concurrent login attempts without degradation of performance.
- Security mechanisms function correctly under stress.
- Session management policies are effective even with high user loads.
Importance of Load Testing:
Load testing is crucial for verifying the performance capabilities of your website. It allows you to measure response times, throughput rates, and resource utilization levels, ensuring that your service meets its performance expectations. Moreover, regular load testing helps in proactive performance tuning and capacity planning.
Why Locust?
Locust is preferred for such scenarios due to its versatility and ease of use. It allows you to write tests in plain Python code, making it flexible to integrate with any part of your website or application. Locust also scales horizontally, allowing you to simulate millions of users with the help of distributed testing.
Key Concepts and Tools Covered:
This guide will delve into the following crucial concepts and tools:
- Basic Setup: Installation of Locust and setting up the essential environment to get started.
- Locust Tasks: Writing tasks to simulate user behavior, specifically focusing on login.
- HTTP Sessions and Cookies: How Locust manages sessions and cookies, which are fundamental for emulating logged-in users.
- Error Handling: Techniques to identify and resolve issues that arise during load tests.
- Optimization Strategies: Enhancing the efficiency of your Locust scripts.
- Running Tests: Executing the load tests and interpreting the results to make informed decisions.
By the end of this guide, you’ll have a solid foundation in using Locust to effectively simulate user logins and interpret the results to optimize your application’s performance. Let’s begin our journey to ensure robust performance under load by understanding Locust and the principles of load testing in the next section.
Understanding Locust and Load Testing
Load testing is an essential practice for any website that expects to serve a large number of users, ensuring that it can handle high traffic and perform efficiently under stress. One effective tool for conducting these tests, especially for actions like user logins, is Locust.
What is Locust?
Locust is an open-source load testing tool written in Python. It excels in creating simple to complex test scenarios that mimic user behavior under load. The key feature of Locust is its ability to write test scenarios in plain Python code, making it highly flexible and easy to integrate into any developer’s workflow.
How Locust Works
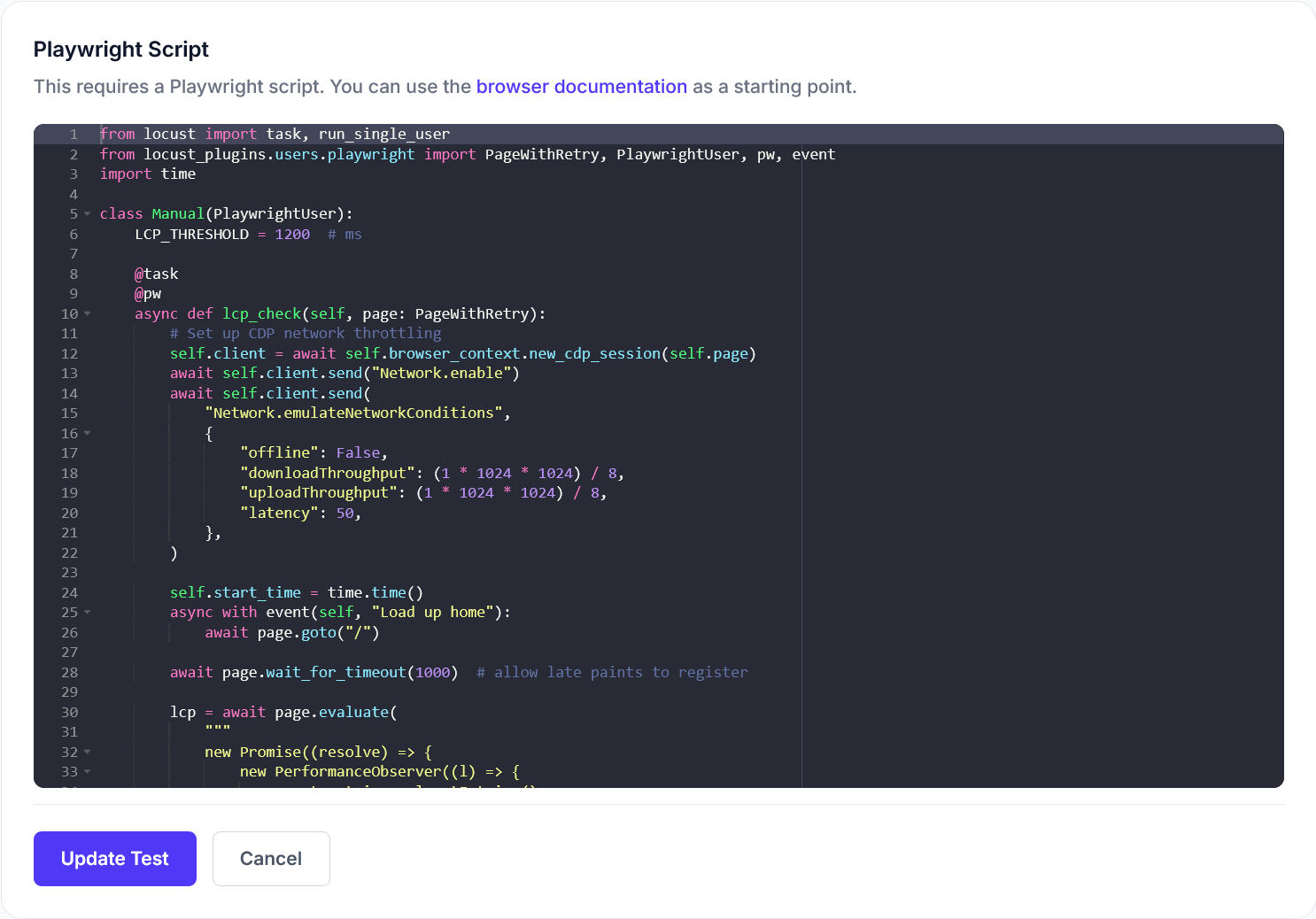
Locust uses a distributed model where each 'locust' or user simulates a specific type of site interaction, which in aggregate forms the basis of a load test. Users can define the behavior of these locusts using Python classes and functions. Here’s a basic example of a Locust task:
from locust import HttpUser, task
class WebsiteUser(HttpUser):
@task
def index_page(self):
self.client.get("/")
In this example, WebsiteUser represents a simulated user, and the index_page function defines a task that this user will perform - in this case, accessing the homepage.
Why Locust is Effective for Login Simulation
User login is often a key performance bottleneck in web applications, particularly because it involves session starts, database lookups, and potentially other backend service interactions. Simulating login processes is, therefore, critical to understanding how an application behaves under pressure. Here’s why Locust is particularly well-suited for this task:
-
Flexibility with Python Programming: Locust’s use of Python, a widely known and used programming language, allows testers to simulate complex login sequences. Testers can easily customize headers, session data, and handle responses just like in real-world scenarios.
-
Real-time Feedback: It offers a web-based interface showing the number of users simulated, their spawn rate, and current stats about response times, number of requests, and failure rates. This is particularly useful for adjusting the test conditions on the fly and immediately understanding the impact.
-
Scalability: Locust can start with just a few users and scale up to thousands, measuring the impact at each stage. This scalability makes it a robust choice for even the most high-traffic sites.
-
Event Hooks and Extensibility: Locust supports event hooks that allow for execution of arbitrary Python code when certain events occur, like receiving a response. This is useful for handling login tokens and session IDs which are part of typical login flows.
Conclusion
Locust’s distinct approach to load testing by utilizing real executable Python code for simulating users offers unparalleled flexibility and power. For tasks like simulating logins, where every small step might be crucial, Locust provides the depth of control and observation needed to make actionable insights and ensure your application can handle the real world at its busiest times. In the following sections, we will delve deeper into setting up Locust and crafting specific login simulation tasks.
Setting Up Your Environment
Setting up the right environment is the foundational step in ensuring that your Locust load tests are executed smoothly and efficiently. In this section, we will guide you through the process of installing Locust, configuring your development environment, and setting up any necessary prerequisites. By the end of this section, you will be ready to start writing your own Locustfile for simulating user logins.
Prerequisites
Before you begin installing Locust, ensure that you have the following prerequisites installed on your machine:
-
Python: Locust is written in Python and requires Python 3.6 or newer. You can download and install Python from the official Python website.
-
pip: pip is the package installer for Python. It usually comes pre-installed with Python. If not, you can install it by following the instructions on the pip installation page.
Installing Locust
Once you have Python and pip installed, you can install Locust using pip. Open your command line interface (CLI) and run the following command:
pip install locust
This command will download and install Locust and all its dependencies. To verify that Locust has been successfully installed, you can run the following command:
locust --version
If Locust is correctly installed, this command will display the version of Locust that you have installed.
Configuring Your Development Environment
To effectively write and test your Locustfiles, it's advisable to set up a dedicated virtual environment. This helps in managing dependencies and keeps your project isolated from global Python packages. You can create a virtual environment in your project directory by running:
python -m venv myenv
Activate the virtual environment with the following command:
myenv\Scripts\activate
source myenv/bin/activate
With the virtual environment activated, all Python and pip commands will operate within this isolated environment, and you can proceed to install Locust locally to this environment using the pip install locust command again if necessary.
Ensuring Network Configurations
Ensure that your network settings and firewalls allow HTTP traffic, as Locust will need to make web requests to the target website. This might involve configuring firewall settings or ensuring proper network permissions.
Directory Structure and Files
Create a directory for your Locust project, and within this directory, you will create your locustfile.py, where your login simulation scripts will be written. The typical structure looks like this:
/my-load-test/
|-- locustfile.py
Once your environment and project structure are correctly set up, you’re ready to start writing your Locustfile, where you'll define the behavior of your simulated users trying to log into your website.
This completes the environment setup necessary for running Locust for login simulations. In the following sections, we will delve into writing the actual Locustfile and simulating the login process.
Writing a Basic Locustfile
Before diving into specific login simulations, it's essential to understand how to construct a basic Locustfile. This file serves as the blueprint for your load tests, defining the behavior of simulated users (Locusts) interacting with your website. We'll start with the fundamentals of writing a Locustfile, focusing first on defining simple user behaviors and then gradually moving to more complex scenarios.
1. Importing Necessary Modules
Every Locustfile begins with importing required modules from Locust. The most critical import is HttpUser, which represents a user making HTTP requests:
from locust import HttpUser, task, between
HttpUser: Defines a user class that can make HTTP requests.task: A decorator to specify user tasks.between: Used to define the wait time between tasks.
2. Defining the User Class
Next, define a user class that extends HttpUser. This class includes settings and tasks that describe how the user behaves:
class WebsiteUser(HttpUser):
wait_time = between(1, 5)
The wait_time attribute specifies the time, in seconds, that a simulated user waits between executing tasks. It makes the behavior more realistic by mimicking human interaction.
3. Writing Tasks
Tasks are functions marked with the @task decorator and define the actions each user performs. Start by creating a simple task that makes a GET request:
@task
def view_homepage(self):
self.client.get("/")
The above task simulates users visiting the homepage ("/"). The self.client.get("/") statement performs a GET request to the root URL defined during the test configuration.
4. Scaling Complexity: Adding More Tasks
To extend the test scenario, introduce more tasks mimicking varied user behaviors, like accessing different parts of the website:
@task(2) # Higher weight means this task runs more frequently
def explore_products(self):
self.client.get("/products")
@task(1)
def about_us(self):
self.client.get("/about")
Tasks can also be weighted, determining their frequency of execution relative to others. In this example, explore_products has a higher weight (2), which means it is twice as likely to be executed compared to about_us (1).
5. Running Your Basic Load Test
Now that you’ve defined a basic user behavior with several tasks, you can run your Locust test locally using:
locust -f locustfile.py
This command starts the Locust web interface where you can specify the number of users to simulate and the spawn rate. Once set, begin the test and observe your website’s behavior under simulated traffic.
6. Next Steps
With the foundational Locustfile in place, you can progress to more specific test cases, like simulating user logins, which are covered in subsequent sections of this guide. By gradually adding complexity, you can tailor your load tests to provide meaningful insights specific to your website's various functionalities.
This introduction to writing a basic Locustfile prepares you with the fundamental skills needed to start crafting sophisticated load testing scenarios. As you become more comfortable with these basics, you can adapt and expand your tests to match real-world user behavior as closely as possible.
Simulating the Login Process
In this vital section of our guide, we concentrate on crafting a task within the Locustfile that efficiently simulates a user attempting to log into a website. This simulation includes handling form data submission, managing sessions, and navigating through various authentication mechanisms. Each of these areas plays a crucial role in authentically replicating how users interact with your login interface under load.
Handling Form Data
When a user logs into a website, they typically fill out a form providing credentials such as a username and password. To simulate this in Locust, you need to make an HTTP POST request to the login endpoint of your application, including the necessary data. Here’s a basic example:
from locust import HttpUser, task, between
class WebsiteUser(HttpUser):
wait_time = between(1, 5)
@task
def login(self):
self.client.post("/login", {"username": "testuser", "password": "password"})
In this example, /login is the path to the server's login endpoint, and the dictionary {"username": "testuser", "password": "password"} represents the credentials submitted.
Managing Sessions
HTTP is a stateless protocol, meaning it doesn’t maintain user state between different requests. This is where sessions come into play, especially important when simulating logins to ensure that the state of a logged-in user persists across multiple interactions with the application.
Locust automatically handles sessions between requests for the same user. Thus, once a user is logged in, you can perform further actions as this authenticated user without needing to log in every time a new request is sent.
Dealing with Authentication Mechanisms
Different applications use various methods for user authentication, including session tokens, cookies, or even more complex mechanisms like OAuth. It's crucial to handle these correctly in your Locustfile to ensure that your simulation behaves as similar as possible to real-world usage.
For instance, if your application uses CSRF tokens, you will need to fetch the login page first, extract the CSRF token from the response, and include it in your subsequent POST request. Here’s how you might accomplish this:
@task
def login(self):
# First get the login page to retrieve the CSRF token
response = self.client.get("/login")
csrf_token = self.extract_csrf_token(response.text)
# Post request with CSRF token included
self.client.post("/login", {
"username": "testuser",
"password": "password",
"csrfmiddlewaretoken": csrf_token
})
def extract_csrf_token(self, response_body):
# Logic to extract the CSRF token from the response body
return "token here"
Summary
By carefully managing form data, sessions, and authentication mechanisms, your Locustfile can effectively simulate user logins, replicating how users typically interact with your application. Understanding and implementing these processes accurately enhances your load testing's realism and value, ensuring your application can handle real-world usage at scale. In the succeeding sections, we will explore handling HTTP sessions and cookies in more depth, along with common error handling and optimization techniques for your Locustfile.
Handling HTTP Sessions and Cookies
In load testing, especially when simulating user logins, managing HTTP sessions and cookies is crucial. These mechanisms play a vital role in maintaining state and managing user authentication across multiple requests. Locust, being a powerful tool, handles sessions and cookies efficiently through its built-in HttpUser class. This section provides a detailed look at how to effectively manage these elements to ensure your simulations accurately reflect real-world usage.
Understanding the Role of HTTP Sessions and Cookies
HTTP, inherently a stateless protocol, does not keep track of interactions. Sessions and cookies are used to retain user states and preferences across multiple HTTP requests:
-
HTTP Sessions: These are server-side mechanisms used to manage state information. The server assigns a unique session ID for each client, usually stored in a cookie, which the client sends with subsequent requests.
-
Cookies: Cookies are crucial for tracking sessions. They store user-specific information (like session IDs) on the client's machine to be sent with each HTTP request, allowing the server to recognize successive requests from the same user.
How Locust Handles Sessions and Cookies
When using Locust to simulate login processes, you do not have to manually manage cookies or session IDs. Locust's HttpUser class automatically handles cookies received from the server. Here’s how you can work with sessions and cookies in your Locustfile:
-
Automatic Cookie Management:
Locust’s HTTP client, which is part of the HttpUser class, automatically handles cookies. When a response includes Set-Cookie in its headers, the cookie is stored in the client's cookie jar and included in subsequent requests.
from locust import HttpUser, task
class WebsiteUser(HttpUser):
@task
def login(self):
self.client.post("/login", {"username": "locust", "password": "secret"})
In the above example, after the login function completes, any cookie set by /login is automatically saved and sent with future requests.
-
Session Management:
You can use the self.client object to explicitly control or modify sessions. However, in most common scenarios with Locust, sessions are implicitly handled via cookies without requiring explicit intervention.
class LoggedInUser(HttpUser):
def on_start(self):
self.client.post("/login", {"username": "user", "password": "password"})
# Following requests will use the same session ensured by cookies
-
Custom Cookie Setting:
If required, you can manually add or modify cookies:
class CustomCookieUser(HttpUser):
def on_start(self):
self.client.cookies.set("test_cookie", "12345")
This method allows you to set cookies before a task is executed, useful for scenarios where cookies need to be crafted in specific ways.
Best Practices for Managing Sessions and Cookies
While Locust efficiently handles basic session management and cookies, here are some best practices to ensure your tests are as realistic as possible:
- Persistent Sessions: Use the
on_start method to simulate a user login and carry forward the session for subsequent tasks within the same user instance.
- Cookie Modification: Only manipulate cookies if necessary for your test, as incorrect handling can lead to non-representative behavior.
- Secure Cookie Handling: When testing environments that resemble production, ensure that cookies marked as secure are transmitted over HTTPS to avoid security issues.
By understanding and effectively managing HTTP sessions and cookies, you can enhance your Locust scripts to more accurately simulate real-world user behavior, leading to more effective and reliable load testing outcomes.
Error Handling and Debugging
When simulating user logins with Locust, several common issues may arise that can affect the accuracy and performance of your tests. This section focuses on identifying these errors, understanding why they occur, and providing strategies to troubleshoot and resolve them effectively.
Common Errors and Their Symptoms
-
Connection Errors: These can happen due to network issues, wrong configuration, or server unavailability.
- Symptoms:
ConnectionRefusedError, MaxRetriesExceeded.
-
Authentication Failures: Incorrect handling of login credentials or session management can lead to failed login attempts.
- Symptoms: Unexpected 401 or 403 HTTP status codes, or redirections to login page despite providing credentials.
-
Session Handling Issues: If cookies or session tokens aren’t managed correctly, the server might fail to maintain user state across subsequent requests.
- Symptoms: Continuous redirection between different application states, loss of session after one or two successful requests.
-
Timeout Errors: These occur if the server takes too long to respond, potentially due to overloading.
- Symptoms:
TimeoutError, prolonged response times.
-
Script Bugs: Incorrect syntax, logical errors, or misunderstanding of the API can introduce issues in the Locust script itself.
- Symptoms: Python exceptions, unexpected behavior during test execution.
Debugging Strategies
To effectively handle and resolve these issues, implement the following strategies:
-
Enhanced Logging
Increase the verbosity of logs to capture detailed information about the test execution.
import logging
logging.basicConfig(level=logging.DEBUG)
-
Assertions and Validations
Use assertions to validate responses at each step of the login process. This helps in quickly pinpointing where the error is occurring.
response = self.client.post("/login", {"username":"testuser", "password":"secret"})
assert response.status_code == 200, "Failed to log in, status code: " + str(response.status_code)
-
Use Try-Catch Blocks
Handle exceptions gracefully by using try-catch blocks to catch and log errors without breaking the entire test script.
try:
response = self.client.post("/login", data={"username": "testuser", "password": "wrongpassword"})
except ConnectionRefusedError as e:
self.interrupt(reschedule=False) # Stops this task set
logging.error("Connection refused: " + str(e))
-
Simulate in Stages
Break down the login process into smaller stages or tasks and simulate each independently. This modular approach makes it easier to isolate and fix issues in specific parts of the login flow.
-
Review Server Logs
If possible, review the logs from the web server or the backend. Server logs often provide clues that are not apparent from the client side.
-
Parameterize Requests
Ensure data variability by using parameterized inputs for usernames and passwords. This can sometimes reveal edge cases that cause unexpected failures.
from locust import task
class UserBehavior(TaskSet):
@task
def login(self):
self.client.post("/login", {"username": self.locust.username, "password": self.locust.password})
Resolving Errors
Once you identify the source of an error, take corrective action based on the issue. This might include:
- Adjusting configurations (timeouts, number of users).
- Fixing bugs in the Locustfile script.
- Improving server capacity or stability.
- Correcting user data or authentication mechanisms.
Conclusion
Effective error handling and debugging are crucial skills when working with Locust for simulation of user logins. By understanding common pitfalls, applying targeted debugging strategies, and using robust error handling, you can enhance the reliability and accuracy of your load testing efforts. Remember, thorough testing during development saves significant hassle post-deployment.
Optimizing Your Locustfile
Optimizing your Locustfile is crucial for ensuring that your load tests are not only effective but also efficient. This part of the guide will provide you with tips and tricks for enhancing the performance and reliability of your login simulations. By refining your Locustfile, you can improve test speed, reduce resource consumption, and get more accurate results.
Use Task Weights
When defining tasks in your Locustfile, you can assign weights to prioritize certain actions over others. This is especially useful when simulating real-world use cases where certain operations (like logging in) are performed more frequently than others.
from locust import HttpUser, task, between
class WebsiteUser(HttpUser):
wait_time = between(1, 5)
@task(3)
def login(self):
pass # your login logic goes here
@task(1)
def another_task(self):
pass # logic for another less frequent task
Minimize Data Overhead
Avoid sending unnecessary data in your requests. For login simulations, ensure you are only sending the required parameters (like username and password). Extra data can increase request size and slow down the simulation.
Handling Static Assets
To speed up your tests, it's generally a good idea to exclude static assets (images, CSS, JS) that are not central to the load test. This can be done by restricting or filtering out these requests in your Locustfile.
class WebsiteUser(HttpUser):
@task
def login(self):
# Assuming static assets are fetched from static.example.com
with self.client.get("/login", catch_response=True) as response:
if "static.example.com" in response.url:
response.failure("Static asset request ignored.")
Reuse Login Credentials
If the test scenario allows, reuse login credentials instead of generating new ones for every test iteration. This can reduce the overhead on your authentication servers and speed up the login process.
class WebsiteUser(HttpUser):
def on_start(self):
self.client.post("/login", {"username": "test_user", "password": "test_password"})
Enable Response Caching
If your load test scenario includes repeated requests to the same endpoints with the same parameters, consider caching responses locally to avoid unnecessary network traffic and reduce load times.
from functools import lru_cache
class WebsiteUser(HttpUser):
@task
@lru_cache(maxsize=100)
def repeated_request(self):
self.client.get("/endpoint")
Profiling and Tuning
Use profiling tools to identify performance bottlenecks in your Locustfile. Adjust task rates, concurrency levels, and other parameters based on profiling data to achieve the optimal balance between load and performance.
Asynchronous Tasks
For advanced users, consider using asynchronous tasks to simulate more complex user behaviors and interactions. This can be particularly effective for scenarios where a user might start multiple independent tasks without waiting for the previous one to complete.
from locust import task
import asyncio
class AsyncWebsiteUser(HttpUser):
@task
async def async_task(self):
await asyncio.sleep(1)
self.client.get("/async-endpoint")
Conclusion
Optimizing your Locustfile is an iterative process. Start with simple optimizations and gradually move to more complex scenarios as you continue to learn from each test's performance data. By applying these optimizations, you can create highly effective and efficient login simulations that closely mimic real-world user behavior.
Running the Load Test
Once you have your Locustfile ready, simulating a user login process, the next crucial step is running the load test to examine your application's behavior under stress. This phase is instrumental in revealing how well your system can handle multiple users logging in simultaneously, and aids in identifying potential bottlenecks or failures in your authentication system.
Setting Up Test Parameters
Before firing up the test, you need to establish your testing criteria, which includes:
- Number of Users (Clients): This is the total number of simulated users that will be logging in to your application.
- Hatch Rate (Spawn Rate): This determines how fast the users are spawned. For example, 10 users per second.
- Host: The URL of the application you are testing.
You can either specify these parameters directly in the command line or within your Locustfile. Here’s how you would run a test from the command line:
locust -f locustfile.py --users 100 --spawn-rate 10 --host https://yourapplication.com
Running the Test
Navigate to your project directory in the terminal where your Locustfile is located and run the command above. Upon executing this command, Locust will start a web interface on http://0.0.0.0:8089. Open this URL in your web browser to access the Locust dashboard.
Interacting With the Locust Dashboard
Through the Locust web interface, you can:
- Start/Stop the Test: Control the execution of your load testing.
- View Real-Time Stats: Monitor the number of requests, median response times, number of failures, and more.
- Download Reports: Generate and download test results for detailed analysis.
Here's a typical view you might encounter in the dashboard:
| Type |
Name |
Requests |
Failures |
Median Response Time |
Average Response Time |
Min Response Time |
Max Response Time |
Average Content Size |
Requests/s |
| POST |
/login |
10000 |
50 |
150ms |
200ms |
100ms |
5000ms |
150 Bytes |
100 |
Interpreting the Results
Understand that not all metrics will be equally important for every test. For a login functionality, key areas to focus on include:
- Failure Rate: Ideally should be close to 0. High failure rates might indicate problems with the login system under load.
- Response Times: Should not deviate significantly as load increases. A large increase could signify backend issues like database performance bottlenecks.
Conclusion
Finally, watch for any alerts or thresholds that are breached during the test. A successful load test will inform if your current infrastructure is adequate or if scaling strategies need to be implemented to handle peak loads, ensuring your users have a seamless login experience. Remember, the end goal is to proactively optimize and prepare, preventing any login failures during real-world application use.
Advanced Techniques
In this section, we dive into the advanced features and techniques of Locust that can further enhance the capabilities of your load tests, especially when dealing with complex scenarios. These techniques include parameterization, managing test data variability, and integrating Locust into Continuous Integration/Continuous Deployment (CI/CD) pipelines.
Parameterization
Parameterization is crucial when you want to simulate real-world user interactions more effectively. It enables you to dynamically modify inputs for each test iteration, making your load tests more realistic and robust.
Below is an example of how to implement parameterization in a Locustfile:
from locust import HttpUser, task, between
import csv
class WebsiteUser(HttpUser):
wait_time = between(1, 5)
def on_start(self):
self.credentials = self._get_credentials()
def _get_credentials(self):
users = []
with open('users.csv', newline='') as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
users.append(row)
return users
@task
def login(self):
for creds in self.credentials:
self.client.post(
"/login",
{"username": creds['username'], "password": creds['password']}
)
In this example, users.csv contains multiple user credentials, allowing the simulation to use a different user for each test iteration.
Managing Test Data Variability
To mimic real user behavior, variability in test data is crucial. This can be achieved by incorporating random choices or generating data on the fly, which helps in identifying unexpected issues that occur with diverse datasets.
Here’s how you can introduce data variability:
from locust import HttpUser, task, between
import random
class WebsiteUser(HttpUser):
wait_time = between(1, 5)
@task
def submit_form(self):
data = {
"email": f"user{random.randint(1, 1000)}@example.com",
"comment": f"Test comment {random.randint(1, 100)}"
}
self.client.post("/submit_form", data=data)
Integration with CI/CD Pipelines
Integrating Locust into CI/CD pipelines ensures that performance tests run automatically, which is vital for detecting performance regressions and bottlenecks before they affect production environments. Here’s an example of how you can integrate a simple Locust test into a Jenkins pipeline:
- Create a Jenkins Job: Set up a new job in Jenkins specifically for Locust tests.
- Configure the Build Trigger: Choose how you want to trigger the build—perhaps every time a commit is pushed to a particular branch.
- Add Build Steps:
- Install Locust on the build agent if not already installed.
- Run the Locust test using the command line interface.
- Optionally, add steps to archive the test results and reports.
locust -f locustfile.py --headless -u 100 -r 10 --run-time 1h --html report.html
- Post-build Actions: Configure Jenkins to send notifications based on test outcomes, and analyze the test results.
Integrating Locust into your CI/CD pipeline automates performance testing, providing immediate feedback on the impact of recent changes and ensuring that performance standards are maintained throughout the development process.
By leveraging these advanced techniques in Locust, you can significantly enhance the effectiveness and reliability of your load testing strategy, ensuring that your application is not only functional but also robust under varying loads and conditions.
Conclusion
In this guide, we have explored the intricacies of creating an effective Locustfile to simulate the login process on a website. From setting up your environment and writing a basic Locustfile to handling HTTP sessions and optimizing your load test, each section has contributed to building a comprehensive understanding of load testing using Locust.
Key Points Review
-
Understanding Locust and Load Testing: We've learned that Locust is an intuitive, script-based load testing tool that allows us to simulate millions of simultaneous users. The importance of load testing, particularly for login functionality, cannot be overstated as it ensures our applications can handle real-world traffic and usage patterns.
-
Writing and Optimizing a Locustfile: Starting with simple user tasks, we progressed to simulate complex user behaviors such as logging into a website. We discussed how to handle form data, manage sessions, and authenticate users effectively.
-
HTTP Sessions and Debugging: Handling HTTP sessions and cookies is crucial for maintaining user state during testing. We've also covered the common pitfalls in login simulations and best practices for debugging and error handling.
-
Running the Load Test: Proper execution of your load test and correct interpretation of the results determine the success of your testing efforts. We've provided insights into configuring test parameters and analyzing the outcomes to enhance the application’s performance and robustness.
Next Steps
Following the successful implementation of your login simulation test, consider the following steps to continue improving your web application's performance and reliability:
- Continuous Testing: Integrate Locust testing into your CI/CD pipeline to ensure continuous performance evaluation as part of your development process.
- Scalability Tests: Extend your testing scenarios to cover not just login processes but other critical functionalities that might impact the scalability of your application.
- Advanced Scenarios: Utilize advanced Locust features such as test data variability and parameterization to simulate more diverse and complex user interactions.
- Monitoring and Alerting: Implement monitoring tools to continuously track the performance of your application in production, using insights gained from load testing to set useful alerts.
Learning More
To deepen your understanding of Locust and load testing, consider exploring additional resources such as the official Locust documentation, community forums, or advanced tutorials. Participating in community discussions and sharing your experiences can also provide new insights and best practices.
Your journey in enhancing web application performance is ongoing, and with the tools and techniques discussed in this guide, you are well-equipped to tackle the challenges that come with ensuring a robust, user-friendly application that can scale effectively under heavy loads. Keep testing, keep optimizing, and continue to learn from each test’s outcomes to ensure your applications are not just functional but truly resilient and efficient.