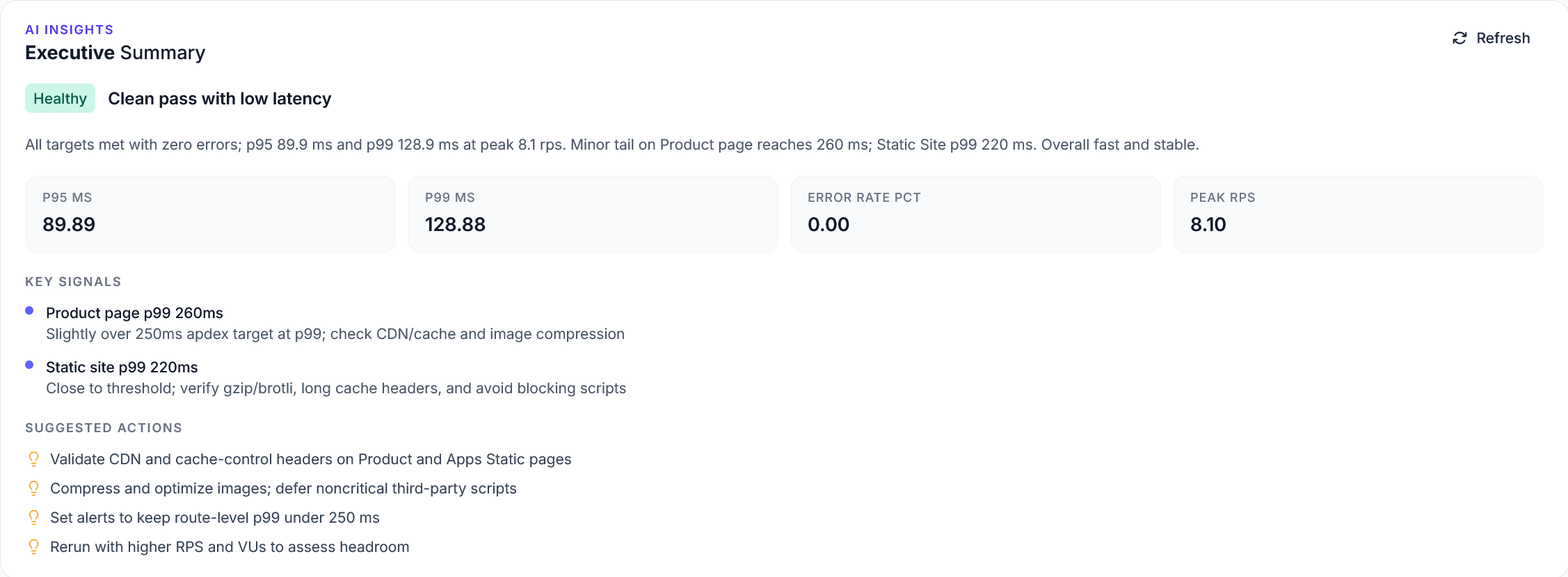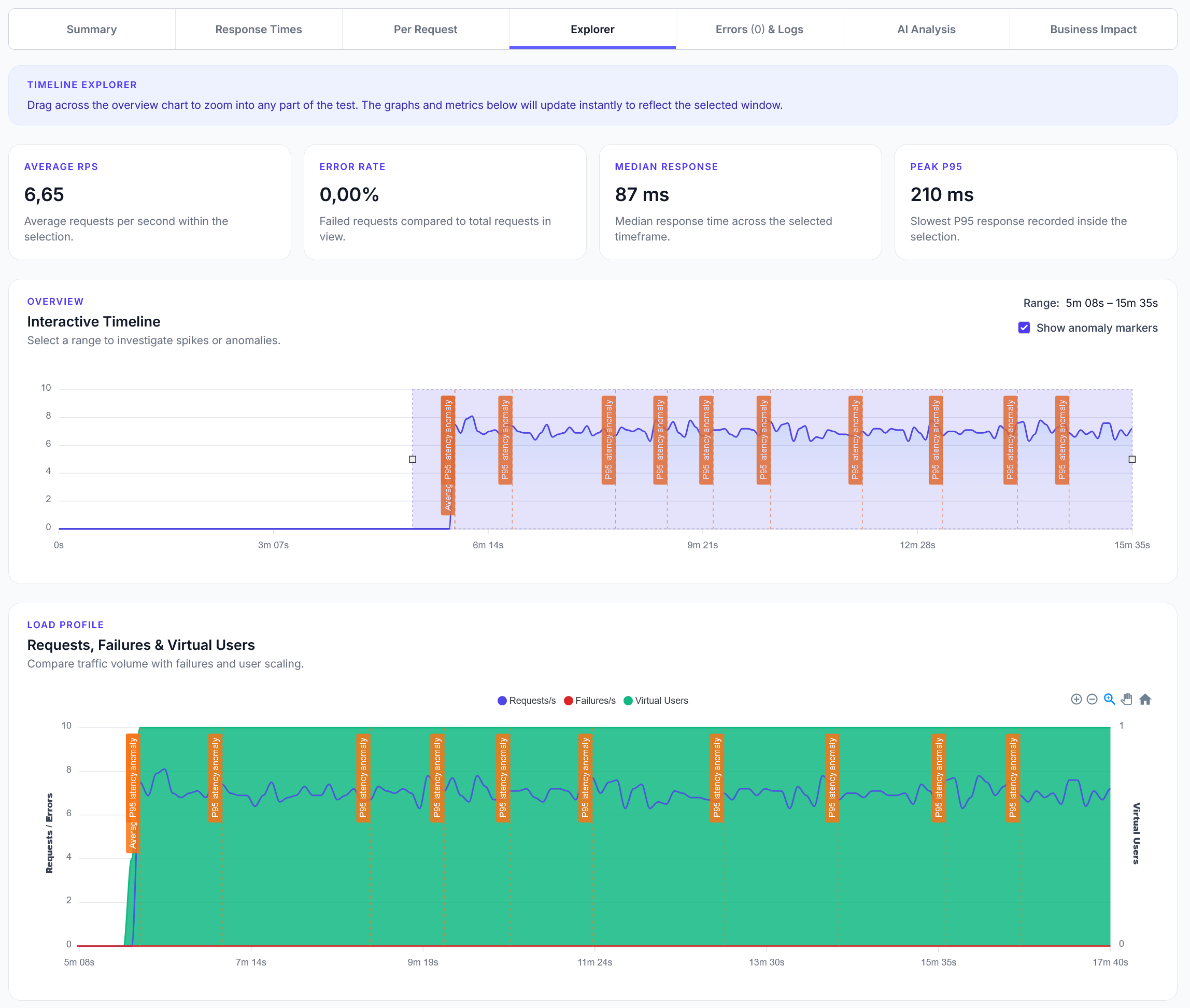
Explorer reports addition
We have added a new Explorer feature to reports, with a timeline scrubber and easy anomaly detection.
A premade example for how to load test your NextJS website and understand its performance.
LoadForge can record your browser, graphically build tests, scan your site with a wizard and more. Sign up now to run your first test.
In this guide, we'll walk through creating a load test for a Next.js website using Locust, and running it with LoadForge. This specific test is able to used with any Javascript based site (next, nuxt, react, etc) as it automatically crawls URLs on the site and uses those in the load test.
You can authenticate, maintain sessions, and much more with LoadForge. Browse the docs for examples on what you need, or use your LoadForge account's wizard or AI test generator to make the test for you.
Ensure you have:
LoadForge instances come pre-provisioned with many helpful tools, including beautifulsoup4, which we use for parsing html content in this test. You can install it yourself locally if you can busy developing your test still with the following command:
pip install locust beautifulsoup4
The example below demonstrates a user that crawls a webpage, discovering and loading linked pages and static content (like images, CSS, JS files). You can paste this locustfile directly into LoadForge to test your site.
from bs4 import BeautifulSoup
from locust import HttpUser, task, between
class WebsiteUser(HttpUser):
wait_time = between(1, 2.5)
def on_start(self):
self.crawl("/")
def crawl(self, path):
response = self.client.get(path, name="[Page] "+path)
if response.status_code == 200:
soup = BeautifulSoup(response.text, "html.parser")
# Discover linked pages
links = [a["href"] for a in soup.find_all("a", href=True)]
for link in links:
self.crawl(link)
# Load static content (img, css, js)
resources = [(link["href"], "CSS") for link in soup.find_all("link", href=True)]
resources += [(script["src"], "JS") for script in soup.find_all("script", src=True)]
resources += [(img["src"], "IMG") for img in soup.find_all("img", src=True)]
for resource, res_type in resources:
self.client.get(resource, name=f"[{res_type}] {resource}")
@task(1)
def load_homepage(self):
self.client.get("/")
on_start: Initiates crawling the homepage once per simulated user.crawl: A recursive method making GET requests to paths, discovering and loading other linked resources.@task(1): Simulates users continually loading the homepage.This guide provided a basic setup for load testing a Next.js website, crawling, and discovering links/resources. Ensure to optimize and adjust your locustfile based on real-world user interactions, website structure, and testing objectives.
LoadForge operates on the robust foundation of Locust. This compatibility ensures that users of open-source Locust can effortlessly adopt this script into their setups. If you're already leveraging Locust, think about integrating your script with LoadForge to elevate your testing experience!